















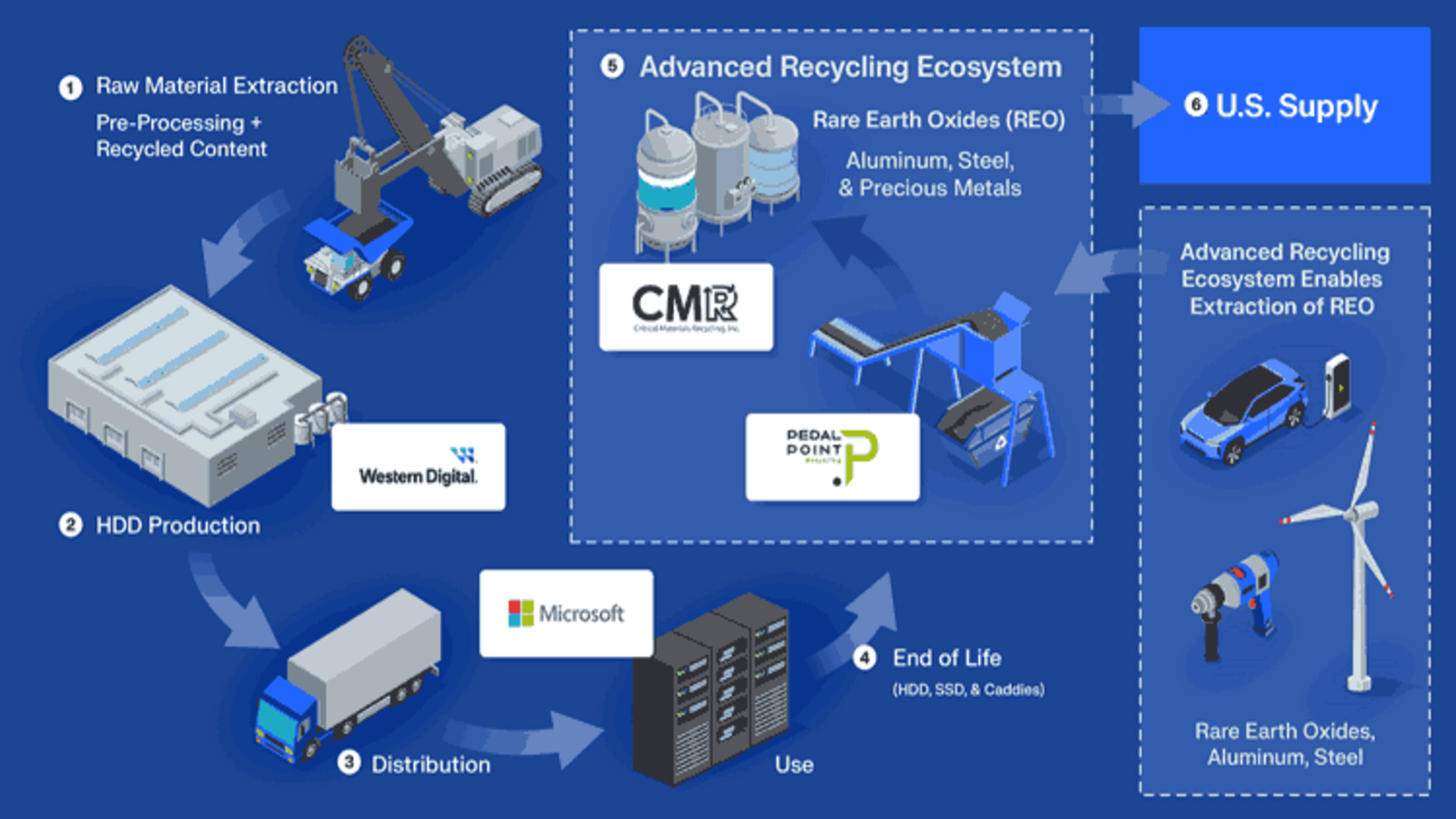



























































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






















































































































































![Architecture for TypeScript backend with multiple entry points or apps [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)
![Is This Programming Paradigm New? [closed]](https://miro.medium.com/v2/resize:fit:1200/format:webp/1*nKR2930riHA4VC7dLwIuxA.gif)



























































































-Classic-Nintendo-GameCube-games-are-coming-to-Nintendo-Switch-2!-00-00-13.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)







































































































































![M4 MacBook Air Drops to New All-Time Low of $912 [Deal]](https://www.iclarified.com/images/news/97108/97108/97108-640.jpg)
![New iPhone 17 Dummy Models Surface in Black and White [Images]](https://www.iclarified.com/images/news/97106/97106/97106-640.jpg)






























































































































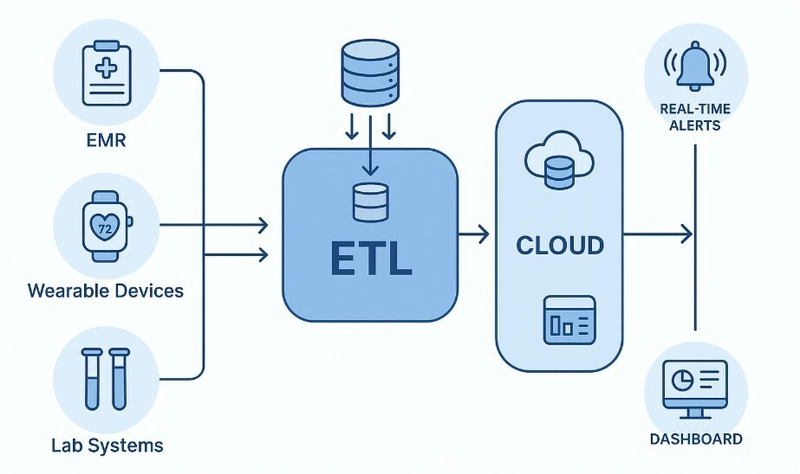
Build a knowledge graph from documents using Docling
First experience of building a knowledge graph from a document using Docling! Introduction and motivation Knowledge graphs are powerful tools for representing information in a structured way. They consist of nodes, which represent entities (like people, places, or concepts), and edges, which represent the relationships between those entities. By organizing information in this manner, knowledge graphs enable more intuitive data exploration, facilitate complex query answering, and support advanced analytical tasks. They are used in a wide range of applications, including search engines, recommendation systems, and data integration, to provide deeper insights and enhance decision-making. Using Docling for document extraction can significantly streamline the process of building knowledge graphs. Docling’s ability to parse diverse document formats, including complex PDFs, and provide a structured representation of the document’s content simplifies the identification of key entities and relationships. Instead of dealing with raw text, which requires extensive pre-processing, Docling offers a more organized output, making it easier to extract the specific information needed to populate a knowledge graph, such as the entities (“Paris”, “Eiffel Tower”) and their relations (“is located in”, “was designed by”) present in the sample document. This structured approach reduces the effort involved in information extraction and improves the accuracy of the resulting knowledge graph. Code Implementation Okay, having introduced the idea, I decided to write a sample code which builds a knowledge graph out of a PDF. The following is the code alongside with the results. # preparation python3 -m venv venv source venv/bin/activate pip install --upgrade pip pip install 'docling[all]' pip install spacy pip install networkx pip install matplotlib pip install nlp import json import logging import time from pathlib import Path import spacy import networkx as nx import matplotlib.pyplot as plt from docling.datamodel.base_models import InputFormat from docling.datamodel.pipeline_options import ( AcceleratorDevice, AcceleratorOptions, PdfPipelineOptions, ) from docling.document_converter import DocumentConverter, PdfFormatOption # Load a spaCy language model nlp = spacy.load("en_core_web_sm") def extract_text_from_docling_document(docling_document): """Extracts text content from a Docling Document object.""" text = docling_document.export_to_text() return text def build_knowledge_graph(text): doc = nlp(text) graph = nx.Graph() # Extract entities for ent in doc.ents: graph.add_node(ent.text, label=ent.label_) # Simple relationship extraction (can be improved) for sent in doc.sents: for i, token in enumerate(sent): if token.dep_ in ["nsubj", "dobj"]: subject = [w for w in token.head.lefts if w.dep_ == "nsubj"] object_ = [w for w in token.head.rights if w.dep_ == "dobj"] if subject and object_: graph.add_edge(subject[0].text, object_[0].text, relation=token.head.lemma_) elif subject and token.head.lemma_ in ["be", "have"]: right_children = [child for child in token.head.rights if child.dep_ in ["attr", "acomp"]] if right_children: graph.add_edge(subject[0].text, right_children[0].text, relation=token.head.lemma_) return graph def visualize_knowledge_graph(graph): """Visualizes the knowledge graph.""" pos = nx.spring_layout(graph) nx.draw(graph, pos, with_labels=True, node_size=3000, node_color="skyblue", font_size=10, font_weight="bold") edge_labels = nx.get_edge_attributes(graph, 'relation') nx.draw_networkx_edge_labels(graph, pos, edge_labels=edge_labels) plt.title("Knowledge Graph from Document") plt.show() def main(): logging.basicConfig(level=logging.INFO) _log = logging.getLogger(__name__) # Initialize the logger here #nlp = spacy.load("en_core_web_sm") # Load spacy # Removed from here #input_doc_path = Path("./input/2503.11576v1.pdf") input_doc_path = Path("./input/input.pdf") ########################################################################### # Docling Parse with EasyOCR # ---------------------- pipeline_options = PdfPipelineOptions() pipeline_options.do_ocr = True pipeline_options.do_table_structure = True pipeline_options.table_structure_options.do_cell_matching = True pipeline_options.ocr_options.lang = ["es"] pipeline_options.accelerator_options = AcceleratorOptions( num_threads=4, device=AcceleratorDevice.AUTO ) doc_converter = DocumentConverter( format_options={ InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options) } ) ###########################################################################

First experience of building a knowledge graph from a document using Docling!
Introduction and motivation
Knowledge graphs are powerful tools for representing information in a structured way. They consist of nodes, which represent entities (like people, places, or concepts), and edges, which represent the relationships between those entities. By organizing information in this manner, knowledge graphs enable more intuitive data exploration, facilitate complex query answering, and support advanced analytical tasks. They are used in a wide range of applications, including search engines, recommendation systems, and data integration, to provide deeper insights and enhance decision-making.
Using Docling for document extraction can significantly streamline the process of building knowledge graphs. Docling’s ability to parse diverse document formats, including complex PDFs, and provide a structured representation of the document’s content simplifies the identification of key entities and relationships. Instead of dealing with raw text, which requires extensive pre-processing, Docling offers a more organized output, making it easier to extract the specific information needed to populate a knowledge graph, such as the entities (“Paris”, “Eiffel Tower”) and their relations (“is located in”, “was designed by”) present in the sample document. This structured approach reduces the effort involved in information extraction and improves the accuracy of the resulting knowledge graph.
Code Implementation
Okay, having introduced the idea, I decided to write a sample code which builds a knowledge graph out of a PDF.
The following is the code alongside with the results.
# preparation
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install 'docling[all]'
pip install spacy
pip install networkx
pip install matplotlib
pip install nlp
import json
import logging
import time
from pathlib import Path
import spacy
import networkx as nx
import matplotlib.pyplot as plt
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import (
AcceleratorDevice,
AcceleratorOptions,
PdfPipelineOptions,
)
from docling.document_converter import DocumentConverter, PdfFormatOption
# Load a spaCy language model
nlp = spacy.load("en_core_web_sm")
def extract_text_from_docling_document(docling_document):
"""Extracts text content from a Docling Document object."""
text = docling_document.export_to_text()
return text
def build_knowledge_graph(text):
doc = nlp(text)
graph = nx.Graph()
# Extract entities
for ent in doc.ents:
graph.add_node(ent.text, label=ent.label_)
# Simple relationship extraction (can be improved)
for sent in doc.sents:
for i, token in enumerate(sent):
if token.dep_ in ["nsubj", "dobj"]:
subject = [w for w in token.head.lefts if w.dep_ == "nsubj"]
object_ = [w for w in token.head.rights if w.dep_ == "dobj"]
if subject and object_:
graph.add_edge(subject[0].text, object_[0].text, relation=token.head.lemma_)
elif subject and token.head.lemma_ in ["be", "have"]:
right_children = [child for child in token.head.rights if child.dep_ in ["attr", "acomp"]]
if right_children:
graph.add_edge(subject[0].text, right_children[0].text, relation=token.head.lemma_)
return graph
def visualize_knowledge_graph(graph):
"""Visualizes the knowledge graph."""
pos = nx.spring_layout(graph)
nx.draw(graph, pos, with_labels=True, node_size=3000, node_color="skyblue", font_size=10, font_weight="bold")
edge_labels = nx.get_edge_attributes(graph, 'relation')
nx.draw_networkx_edge_labels(graph, pos, edge_labels=edge_labels)
plt.title("Knowledge Graph from Document")
plt.show()
def main():
logging.basicConfig(level=logging.INFO)
_log = logging.getLogger(__name__) # Initialize the logger here
#nlp = spacy.load("en_core_web_sm") # Load spacy # Removed from here
#input_doc_path = Path("./input/2503.11576v1.pdf")
input_doc_path = Path("./input/input.pdf")
###########################################################################
# Docling Parse with EasyOCR
# ----------------------
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
pipeline_options.do_table_structure = True
pipeline_options.table_structure_options.do_cell_matching = True
pipeline_options.ocr_options.lang = ["es"]
pipeline_options.accelerator_options = AcceleratorOptions(
num_threads=4, device=AcceleratorDevice.AUTO
)
doc_converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options)
}
)
###########################################################################
start_time = time.time()
conv_result = doc_converter.convert(input_doc_path)
end_time = time.time() - start_time
_log.info(f"Document converted in {end_time:.2f} seconds.")
if conv_result and conv_result.document:
text = extract_text_from_docling_document(conv_result.document)
if text:
knowledge_graph = build_knowledge_graph(text)
if knowledge_graph:
print("Number of nodes:", knowledge_graph.number_of_nodes())
print("Number of edges:", knowledge_graph.number_of_edges())
visualize_knowledge_graph(knowledge_graph)
print("\nNodes:", knowledge_graph.nodes(data=True))
print("\nEdges:", knowledge_graph.edges(data=True))
else:
_log.warning("Could not extract text from the Docling document.")
else:
_log.error("Docling conversion failed or returned an empty document.")
if __name__ == "__main__":
main()
Now let’s try to build a document which represents relation between entities. I used a LLM (granite) to generate the text below!
"The city of Paris, located in France, is renowned for its iconic Eiffel Tower. It is a popular tourist destination. The tower was designed by Gustave Eiffel. Marie Curie, a famous scientist, was born in Paris and made significant contributions to the field of radioactivity. She worked at the Radium Institute. The Seine River flows through Paris."
Explanation of why this is suitable:
This document contains several entities and relationships that can be easily extracted and represented in a knowledge graph:
• Entities: Paris, France, Eiffel Tower, Gustave Eiffel, Marie Curie, Radium Institute, Seine River
• Relationships:
o Paris is located in France.
o Paris is renowned for the Eiffel Tower.
o The Eiffel Tower was designed by Gustave Eiffel.
o Marie Curie was born in Paris.
o Marie Curie was a scientist.
o Marie Curie made contributions to radioactivity.
o Marie Curie worked at the Radium Institute.
o The Seine River flows through Paris.
A knowledge graph constructed from this document would represent these entities as nodes and the relationships as edges, providing a structured representation of the information.
I made a PDF from the text above and used it as my “input.pdf”.
After the code runs (successfully ⭐) I get the following outputs;
INFO:__main__:Document converted in 8.63 seconds.
WARNING:docling_core.types.doc.document:Parameter `strict_text` has been deprecated and will be ignored.
Number of nodes: 23
Number of edges: 7
2025-04-23 21:33:52.828 python3[73966:691115] The class 'NSSavePanel' overrides the method identifier. This method is implemented by class 'NSWindow'
Nodes: [('Paris', {'label': 'GPE'}), ('France', {'label': 'GPE'}), ('Eiffel Tower', {'label': 'FAC'}), ('Gustave Eiffel', {'label': 'PERSON'}), ('Marie Curie', {'label': 'PERSON'}), ('the Radium Institute', {'label': 'FAC'}), ('Seine River', {'label': 'LOC'}), ('## Explanation', {'label': 'MONEY'}), ('Radium Institute', {'label': 'ORG'}), ('the Eiffel Tower', {'label': 'LOC'}), ('The Eiffel Tower', {'label': 'LOC'}), ('city', {}), ('renowned', {}), ('It', {}), ('destination', {}), ('Explanation', {}), ('entities', {}), ('this', {}), ('suitable', {}), ('Curie', {}), ('scientist', {}), ('contributions', {}), ('graph', {})]
Edges: [('city', 'renowned', {'relation': 'be'}), ('It', 'destination', {'relation': 'be'}), ('Explanation', 'entities', {'relation': 'contain'}), ('entities', 'graph', {'relation': 'represent'}), ('this', 'suitable', {'relation': 'be'}), ('Curie', 'scientist', {'relation': 'be'}), ('Curie', 'contributions', {'relation': 'make'})]
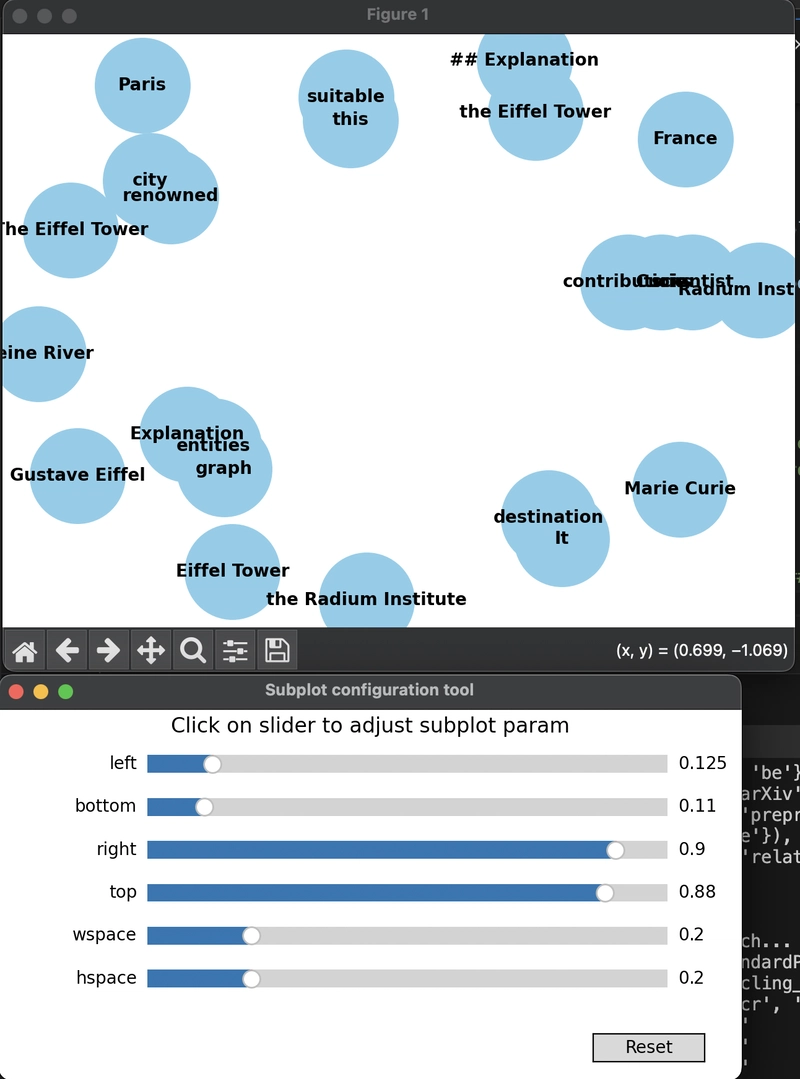
Et voilà !
Conclusion
In conclusion, the effective utilization of Docling in document extraction streamlines the creation of knowledge graphs by simplifying the identification of key entities and relationships from complex documents, thereby enhancing accuracy and efficiency.


