








































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






















































































































































![Architecture for TypeScript backend with multiple entry points or apps [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)
![Is This Programming Paradigm New? [closed]](https://miro.medium.com/v2/resize:fit:1200/format:webp/1*nKR2930riHA4VC7dLwIuxA.gif)



























































































-Classic-Nintendo-GameCube-games-are-coming-to-Nintendo-Switch-2!-00-00-13.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)























_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)











































































































![M4 MacBook Air Drops to New All-Time Low of $912 [Deal]](https://www.iclarified.com/images/news/97108/97108/97108-640.jpg)
![New iPhone 17 Dummy Models Surface in Black and White [Images]](https://www.iclarified.com/images/news/97106/97106/97106-640.jpg)

































































































































6 Ways To Supercharge Your Node.js Serverless Workflow
The rise of serverless has given us new ways to ship business value faster than ever. It allows us to iterate and build cost-effective solutions in record time. I've worked with serverless for six years and never felt more productive. But it didn't start that way. When first starting with serverless, I struggled a lot. I was used to running applications and their dependencies locally during development. With serverless, this proved to be a lot more difficult. There are tools like LocalStack, but back then, it wasn't as mature as it is today. I struggled to find a good balance between rapid feedback and confidence that what I built was working. On one end, you want to unit test as much as possible, since it offers the most rapid feedback. With the many building blocks of serverless, this can quickly evolve into a difficult mocking exercise. It's easy to spend more time crafting mocks than writing actual code. On the other end, you could embrace the “testing in the cloud” approach, where you deploy your application to AWS to verify that everything is working as expected. This gives you more confidence but results in a slower feedback loop since you'll have to deploy every change. I've seen many teams struggle when transitioning to serverless, with the two most common concerns being testing and local development. Do you double down on unit tests? Should you forego unit tests and focus on integration/end-to-end tests instead? Over the years, I've tried multiple approaches, and I think the answer lies somewhere in between. I've found a workflow that I'm happy with, that allows me to iterate with rapid feedback while staying confident that what I'm shipping is working. In this post, I'll share some tools and techniques I use. I'm writing this from the perspective of a Node.js developer building serverless applications on AWS Lambda. If you use a different language or FaaS platform, some things might not apply, but I hope you get some insights that help you improve your development experience. Setting the stage In this blog post, I'll use the following sample architecture as a basis. It's an order service, that allows users to create and retrieve orders. When creating an order, the service will call the product service to check that the included products are valid and available. The service then persists the order and uses DynamoDB streams to trigger a Lambda function that sends an OrderCreated event to EventBridge. With this architecture in mind, let's look at how my workflow building it might look. I will walk through two different feedback loops, the inner and outer loops. The goal of the inner loop is to provide rapid feedback on isolated parts of the application, while the outer loop gives me confidence that the application works as a whole. The rapid inner feedback loop For rapid feedback, unit tests are king. With unit tests, I can test small units of code in isolation. At this stage, I don't care whether everything is wired up correctly. For example, I do not test whether a PutItem to DynamoDB results in an OrderCreated event being sent to EventBridge. Instead, I identify key parts of the application and test those in isolation: Calling the product service Sending an OrderCreated event to EventBridge Saving and retrieving an order from DynamoDB I'm using three different techniques for these three parts. Let's tackle them one by one. Mocking HTTP requests with Mock Service Worker Let's start by looking at the call to the product service. In code, this could look something like this: const productServiceUrl = process.env.PRODUCT_SERVICE_URL || "https://product-service.com"; export const getProductDetails = async (productId: string) => { const res = await fetch(`${productServiceUrl}/products/${productId}`); if (res.status === 404) { throw new Error("Product not found"); } return res.json(); }; To properly test this, I need to mock the HTTP request. In theory, I could mock fetch directly, but I've found that the tool Mock Service Worker makes it much easier to manage, especially as the number of mocks grows. MSW intercepts all outgoing HTTP requests and allows me to configure mock responses. I can set up mocks to return a valid response for the product ID p123, and a 404 response for the product ID p456: import { http, HttpResponse } from "msw"; import { setupServer } from "msw/node"; const handlers = [ http.get("https://product-service.com/products/p123", () => { return HttpResponse.json({ productId: "p123", name: "Rubber Duck", price: 1.99, }); }), http.get("https://product-service.com/products/p456", () => { return HttpResponse.json( { error: "Product not found", }, { status: 404 }, ); }), ]; export const server = setupServer(...handlers); I can now test that the getProductDetails function handles both the happy path and the error path: describe("product s
The rise of serverless has given us new ways to ship business value faster than ever. It allows us to iterate and build cost-effective solutions in record time. I've worked with serverless for six years and never felt more productive.
But it didn't start that way. When first starting with serverless, I struggled a lot. I was used to running applications and their dependencies locally during development. With serverless, this proved to be a lot more difficult. There are tools like LocalStack, but back then, it wasn't as mature as it is today. I struggled to find a good balance between rapid feedback and confidence that what I built was working.
On one end, you want to unit test as much as possible, since it offers the most rapid feedback. With the many building blocks of serverless, this can quickly evolve into a difficult mocking exercise. It's easy to spend more time crafting mocks than writing actual code.
On the other end, you could embrace the “testing in the cloud” approach, where you deploy your application to AWS to verify that everything is working as expected. This gives you more confidence but results in a slower feedback loop since you'll have to deploy every change.
I've seen many teams struggle when transitioning to serverless, with the two most common concerns being testing and local development. Do you double down on unit tests? Should you forego unit tests and focus on integration/end-to-end tests instead?
Over the years, I've tried multiple approaches, and I think the answer lies somewhere in between. I've found a workflow that I'm happy with, that allows me to iterate with rapid feedback while staying confident that what I'm shipping is working.
In this post, I'll share some tools and techniques I use. I'm writing this from the perspective of a Node.js developer building serverless applications on AWS Lambda. If you use a different language or FaaS platform, some things might not apply, but I hope you get some insights that help you improve your development experience.
Setting the stage
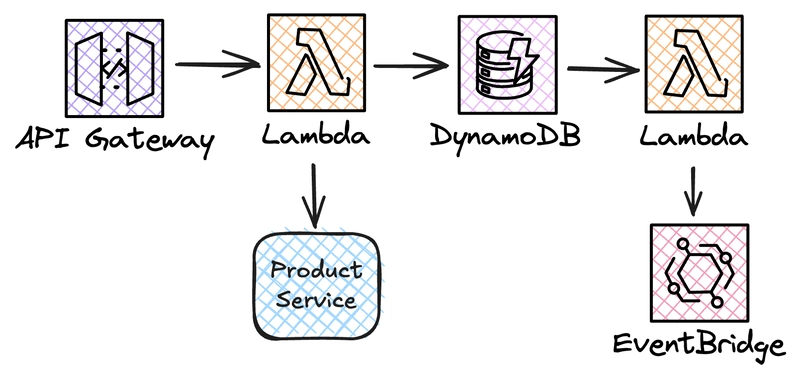
In this blog post, I'll use the following sample architecture as a basis. It's an order service, that allows users to create and retrieve orders. When creating an order, the service will call the product service to check that the included products are valid and available. The service then persists the order and uses DynamoDB streams to trigger a Lambda function that sends an OrderCreated event to EventBridge.
With this architecture in mind, let's look at how my workflow building it might look. I will walk through two different feedback loops, the inner and outer loops. The goal of the inner loop is to provide rapid feedback on isolated parts of the application, while the outer loop gives me confidence that the application works as a whole.
The rapid inner feedback loop
For rapid feedback, unit tests are king. With unit tests, I can test small units of code in isolation. At this stage, I don't care whether everything is wired up correctly. For example, I do not test whether a PutItem to DynamoDB results in an OrderCreated event being sent to EventBridge. Instead, I identify key parts of the application and test those in isolation:
- Calling the product service
- Sending an
OrderCreatedevent to EventBridge - Saving and retrieving an order from DynamoDB
I'm using three different techniques for these three parts. Let's tackle them one by one.
Mocking HTTP requests with Mock Service Worker
Let's start by looking at the call to the product service. In code, this could look something like this:
const productServiceUrl = process.env.PRODUCT_SERVICE_URL || "https://product-service.com";
export const getProductDetails = async (productId: string) => {
const res = await fetch(`${productServiceUrl}/products/${productId}`);
if (res.status === 404) {
throw new Error("Product not found");
}
return res.json();
};
To properly test this, I need to mock the HTTP request. In theory, I could mock fetch directly, but I've found that the tool Mock Service Worker makes it much easier to manage, especially as the number of mocks grows.
MSW intercepts all outgoing HTTP requests and allows me to configure mock responses. I can set up mocks to return a valid response for the product ID p123, and a 404 response for the product ID p456:
import { http, HttpResponse } from "msw";
import { setupServer } from "msw/node";
const handlers = [
http.get("https://product-service.com/products/p123", () => {
return HttpResponse.json({
productId: "p123",
name: "Rubber Duck",
price: 1.99,
});
}),
http.get("https://product-service.com/products/p456", () => {
return HttpResponse.json(
{
error: "Product not found",
},
{ status: 404 },
);
}),
];
export const server = setupServer(...handlers);
I can now test that the getProductDetails function handles both the happy path and the error path:
describe("product service", () => {
beforeAll(async () => {
// Start MSW
server.listen();
});
it("should return product details", async () => {
const actual = await getProductDetails("p123");
expect(actual).toEqual({
productId: "p123",
name: "Rubber Duck",
price: 1.99,
});
});
it("should throw an error when product not found", async () => {
await expect(getProductDetails("p456")).rejects.toThrow(
"Product not found",
);
});
});
MSW allows me a lot of flexibility when mocking any HTTP request. I can configure mocks to return different responses based on the request path, headers, and more, and I can also use MSW to mock WebSockets and GraphQL requests. It is also easy to use in any project, since it isn't tied to a specific testing framework.
If your application includes HTTP requests to external services, I recommend adding MSW to your test setup. It will save you a lot of time and effort.
Mocking AWS SDK calls
With the call to the product service out of the way, let's tackle the sending of OrderCreated events to EventBridge.
export const sendOrderCreatedEvent = async (order: Order) => {
await eventBridgeClient.send(
new PutEventsCommand({
Entries: [
{
Source: "com.example.order",
DetailType: "OrderCreated",
EventBusName: "MyBus",
Detail: JSON.stringify(order),
},
],
}),
);
};
Isn't this another HTTP request under the hood that MSW can handle? Well, yes, it is. But it's a bit more complex to mock than the previous example. This is because the AWS SDK does much work under the hood to send the request and parse the response. To mock this, I must know how the underlying request looks to mock it properly with MSW. I'd also have to return a response that matches what the SDK expects, with the correct format, headers, etc.
The fact that different AWS services have wildly different APIs results in mocking quickly becoming an exercise in reimplementing the AWS SDK in MSW mocks.
Instead of MSW, I'm using aws-sdk-client-mock and aws-sdk-client-mock-vitest, which makes it easy to mock and inspect calls made using the AWS SDK.
describe("Events", () => {
const ebMock = mockClient(EventBridgeClient);
it("should send an OrderCreated event", async () => {
const order = {
orderId: "o123",
products: [
{
productId: "p123",
quantity: 1,
},
],
};
await sendOrderCreatedEvent(order);
expect(ebMock).toHaveReceivedCommandWith(PutEventsCommand, {
Entries: [
expect.objectContaining({
DetailType: "OrderCreated",
Detail: JSON.stringify(order),
}),
],
});
});
});
With this test, I'm confident that the function sendOrderCreatedEvent correctly sends OrderCreated events with the correct payload to EventBridge. At this stage, I don't care whether the function has permission to send the event. I'll verify that later in the outer feedback loop.
Mocking stateful behavior
Let's move on to the last part, saving and retrieving an order from DynamoDB. But, isn't this another AWS SDK call to mock with aws-sdk-client-mock? Yes, it is. But when working with stateful behavior, such as persisting data, I like to verify that the data model works as expected. For example, does the item I save to DynamoDB have the correct format? Can I read it back? Do my queries return the expected records?
On another note, when working with DynamoDB, I rarely use the AWS SDK directly. I prefer using the ElectroDB library, which is much more pleasant to work with. To use aws-sdk-client-mock together with ElectroDB, I would have to delve into the internals of ElectroDB to figure out how it uses the AWS SDK under the hood.
My approach here blurs the line between unit and integration tests. I could execute the tests against a real DynamoDB table by configuring AWS credentials locally and ensuring a table exists. Since DynamoDB is serverless, it would barely cost anything. What if I use a relational database, Redis, or something else? I prefer an approach that works locally for different stateful services, where I don't have to spin up a live database cluster. I leave that for the outer feedback loop when testing the application as a whole.
Instead, I'm using TestContainers which allows me to spin up a local DynamoDB instance for the duration of my tests, using the official amazon/dynamodb-local image.
const item = new electrodb.Entity(...);
export const getItem = async (id: string) => {
const response = await item.get({ id }).go();
return response.data;
};
export const createItem = async (name: string) => {
const response = await item.create({ name }).go();
return response.data;
};
export const listItems = async () => {
const response = await item.scan.go();
return response.data;
};
export const deleteItem = async (id: string) => {
const response = await item.delete({ id }).go();
return response.data;
};
The code shows a simple database implementation using ElectroDB. Let's look at how I can test this, and then we'll take a look at the actual TestContainers setup.
describe("Database", () => {
beforeEach(async () => {
await createTable();
});
afterEach(async () => {
await deleteTable();
});
it("should create an item", async () => {
const created = await createItem("test");
expect(created).toMatchObject({
id: expect.any(String),
name: "test",
});
});
it("should get an item", async () => {
const created = await createItem("test");
const actual = await getItem(created.id);
expect(actual).toMatchObject(created);
});
it("should return a list of items", async () => {
const items = await Promise.all([createItem("test1"), createItem("test2")]);
const actual = await listItems();
expect(actual.length).toBe(2);
expect(actual).toEqual(expect.arrayContaining(items));
});
it("should delete an item", async () => {
const created = await createItem("test");
expect(await getItem(created.id)).toMatchObject(created);
await deleteItem(created.id);
expect(await getItem(created.id)).toBeNull();
});
});
With these tests, I'm confident that my database implementation works as expected. After I create an item, I can retrieve it using the generated id. I know that listing and deleting items work. I create a new table before each test starts to ensure there are no side effects from earlier tests.
This all executes in a local DynamoDB instance running in Docker that holds the state in memory, ensuring the tests execute quickly.
What isn't quick, though, is the startup of the Docker container itself. When developing, I usually start a npm run test:watch process that will re-run my tests whenever I make code changes. If I had to wait 3-7 seconds for the Docker container to start every time I make a change, that would severely slow down the feedback loop.
To circumvent this, I'm using globalSetup in Vitest.
import { defineConfig } from "vitest/config";
export default defineConfig({
test: {
globalSetup: ["./test/setup-containers.ts"],
...
},
});
import { GenericContainer, type StartedTestContainer } from "testcontainers";
let dynamodb: StartedTestContainer;
async function startDynamo() {
return new GenericContainer("amazon/dynamodb-local")
.withExposedPorts(8000)
.start();
}
export async function setup() {
dynamodb = await startDynamo();
process.env.AWS_ENDPOINT_URL_DYNAMODB = `http://${dynamodb.getHost()}:${dynamodb.getMappedPort(8000)}`;
}
export async function teardown() {
await dynamodb.stop();
}
Now, whenever I run npm run test or npm run test:watch, Vitest will automatically start the DynamoDB container and expose it on a random port. I then set the AWS_ENDPOINT_URL_DYNAMODB environment variable to override the URL the AWS DynamoDB SDK uses. I will only get a slight delay when starting the test watcher. All subsequent code changes will trigger the tests with no delay.
Summary
Those are the main techniques for mocking in unit tests that I use during development. To recap, I:
- Mock HTTP requests with Mock Service Worker
- Mock stateless AWS SDK (EventBridge, SQS, etc.) calls with aws-sdk-client-mock
- Mock stateful behavior with TestContainers
With this, I'm confident that my code does what it's supposed to do. But I've not tested that the different parts of my application play well together. Let's leave the inner loop and look at integration and end-to-end tests.
The outer feedback loop
While unit tests give me rapid feedback on isolated parts, they cannot tell me if I wired everything correctly. The sample application could be broken in many ways:
- The API Gateway doesn't route the request to the Lambda function.
- The Lambda functions are missing required permissions.
- The DynamoDB table doesn't have its stream enabled.
- The product service is not available.
- ...
To verify that the application works as a whole, I test my application end-to-end in a real environment. This means deploying my application to AWS and running tests, e.g., by sending requests to the API Gateway. This will surface any issues with configuration, permissions, and so on.
Let's say that I locate an issue. I've confirmed that a new order is successfully created in DynamoDB, but no OrderCreated event is sent to EventBridge. What do I do? I could:
- Make some changes
- Deploy to AWS
- Send a request
- Check CloudWatch logs
- Rinse and repeat
This is a painfully slow feedback loop compared to the rapid inner loop. As an application grows, so does the time it takes to deploy it. Can I speed up this feedback loop?
Debugging in the cloud
When developing, I treat the cloud as an extension of my local development environment. This means that I deploy early and often to get continuous feedback. But, deploying my application on every code change wastes time. Debugging end-to-end issues can devolve into log debugging, where I make a change, deploy, and check the logs for clues. What if I can attach a debugger locally while running the application in the cloud?
The outstanding tool Lambda Live Debugger allows me to do that. I can deploy my application, start the debugger in my IDE, and then step through the code as if it ran on my computer. I can, for example, set a breakpoint in the Lambda function that sends an OrderCreated event. When an item is created in DynamoDB, the stream will trigger the Lambda function, and the debugger will break at the breakpoint. This is especially powerful in event-driven architectures, or complex step function workflows with many Lambda functions.
With LLD, I can get rapid feedback on my changes even when running in the cloud. Changes to the code are reflected immediately, and I can step through the code of my Lambda functions as they are executed using real input events from real AWS services.
Personal Ephemeral environments
All places I've worked have had multiple environments, such as dev, staging, and production. Having only one development environment usually results in questions like "Can I deploy to dev or is anyone using it?" and "Who broke dev?".
One of the key benefits of serverless is that it enables what is generally called ephemeral environments. True serverless services, such as Lambda, DynamoDB, and EventBridge, have a billing model where you only pay for actual usage. This characteristic allows us to deploy multiple development environments without breaking the bank.
When coaching teams on how to get the most out of serverless, I always recommend that every developer on the team deploy a separate personal development environment. This eliminates the problem of a shared development environment being "used" by another developer, and allows team members to work on parallel tasks without interfering with each other.
Ephemeral environments are a requirement for the approach mentioned earlier with LLD. Once, I spent more time than I want to admit wondering why a shared test environment didn't work as expected, and why the CloudWatch logs looked like gibberish. It turned out that someone had been using a live debugger without restoring the functions when they finished. Shared environments don't lend themselves well to live debugging.
To deploy personal development environments, you must ensure that your infrastructure doesn't have resource names that might clash between environments. Take the DynamoDB table in our sample application as an example. If we were to hard-code the table name to OrderTable in our Infrastructure-as-Code, deploying two versions of the environment to the same account would be impossible. If you aren't using an IaC tool that defaults to creating a unique resource name, you have to ensure that uniqueness yourself between environments.
const table = new dynamodb.Table(this, "MyTable", {
// Do NOT set tableName. Let CDK generate a unique name.
partitionKey: { name: "pk", type: dynamodb.AttributeType.STRING },
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
});
Another powerful usage of ephemeral environments is in your CI/CD pipeline. For each pull request, you can deploy the application to a new environment, run tests against it, and then tear down the environment again. The ephemeral nature means you can deploy and test pull requests in parallel without conflicts.
Often, embracing ephemeral environments removes the need for shared non-production environments.
What about the product service?
What if the team behind the product service has gone all-in on ephemeral environments and removed all shared environments except production? The order service depends on it, so which product service environment should I use when developing?
Here, I take a similar approach as when unit testing, where I'm using MSW to mock external HTTP requests. I would rather not run MSW inside the Lambda function since that would entail packaging it with non-production code. It would also need a runtime switch to toggle MSW on or off depending on the environment. Instead, I'm using a technique I recently blogged about, with a Rust adoption of WireMock running in a Lambda extension.
With the extension, a WireMock server will be available on, for example, http://localhost:1234 within the Lambda function. I can mock the product service using WireMock stub files.
{
"request": {
"method": "GET",
"urlPath": "/product-service/products/p123"
},
"response": {
"status": 200,
"jsonBody": {
"productId": "p123",
"name": "Rubber Duck",
"price": 1.99
}
}
}
{
"request": {
"method": "GET",
"urlPath": "/product-service/products/p456"
},
"response": {
"status": 404,
"jsonBody": {
"error": "Product not found"
}
}
}
Then I set the PRODUCT_SERVICE_URL environment variable to http://localhost:1234/product-service, and I'm good to go.
Even if all teams deploy services to shared development and staging environments, I still recommend using the WireMock extension to stub requests to those services. This reduces the risk of another team blocking your progress when they have issues with their non-production environment.
It's also a great way to test how your application behaves when services you depend on are experiencing issues or abnormal latencies. Using WireMock, you can inject faults and latencies and test how your application handles them.
Lastly, it's more or less needed if you have to integrate with a service that doesn't exist in a deployed state yet. As long as an API spec exists, you can start stubbing requests to it with WireMock while the team behind the service is building it.
Summary
To summarize, I use the following strategies to speed up the feedback loop when verifying that my application works as a whole:
- I use Lambda Live Debugger to debug my code, even when running in the cloud.
- I use personal ephemeral environments to allow team members to work independently.
- I run a Rust adoption of WireMock in a Lambda extension to mock external HTTP requests.
Live debugging ensures that I can bypass the lengthy deployment cycle. Ephemeral environments and external services mocks ensure that I'm rarely blocked by another team member or team.
Conclusion
Building with serverless has many benefits, such as allowing you to focus on shipping business value while AWS takes care of the underlying infrastructure. But I've seen developers new to serverless struggle with local development and testing.
If you are used to running your entire application and its dependencies locally, the shift to serverless and running in the cloud can feel like a step back. But it doesn't have to be.
By adopting the techniques and tools in this post, you are well on your way to a fantastic developer experience when building serverless. This workflow offers rapid feedback and the confidence you need to iterate and ship value faster than ever.


