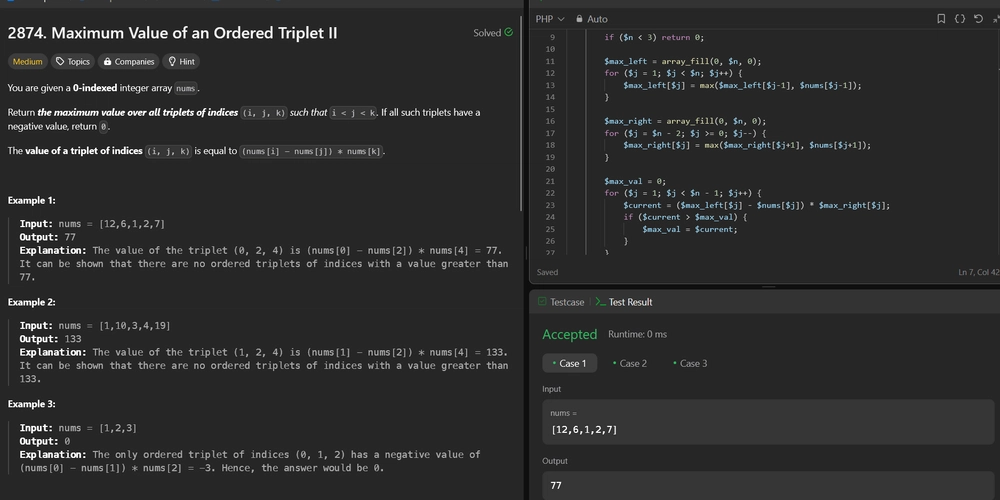
![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)



































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.jpg?#)

































_ArtemisDiana_Alamy.jpg?#)


 (1).webp?#)








































































-xl.jpg)












![Yes, the Gemini icon is now bigger and brighter on Android [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/02/Gemini-on-Galaxy-S25.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Rushes Five Planes of iPhones to US Ahead of New Tariffs [Report]](https://www.iclarified.com/images/news/96967/96967/96967-640.jpg)
![Apple Vision Pro 2 Allegedly in Production Ahead of 2025 Launch [Rumor]](https://www.iclarified.com/images/news/96965/96965/96965-640.jpg)
























































































































Using Python Pandas to Clean and Analyze Scraped Data
This blog was initially posted to Crawlbase Blog Collecting data from the web can be messy, with missing values, duplicates, and inconsistent formats. To use it, you need to clean and analyze. That’s where Python Pandas comes in. Pandas is a powerful library that helps structure, clean, and analyze data. It allows you to remove errors, filter what’s relevant and extract insights easily. In this guide we’ll cover why data cleaning matters, how to use Pandas for processing and key techniques to clean and analyze scraped data. Python Pandas for Data Processing Pandas is a powerful Python library for working with structured data. It helps in organizing, cleaning, and analyzing big datasets. When dealing with scraped data, Pandas has many functions to handle missing values, remove duplicates, filter info, and extract insights. The core data structures in Pandas are DataFrame and Series. A DataFrame is a table-like structure where data is stored in rows and columns, like an Excel sheet. A Series is a single column of a DataFrame. These structures make it easy to manipulate and transform scraped data. Using Pandas you can: Load data from CSV, JSON or databases. Clean data by handling missing values and formatting. Analyze data by sorting, grouping, and applying statistical functions. Visualize insights with built-in plotting functions. For example, loading scraped data into a Pandas DataFrame is as simple as: import pandas as pd # Load scraped data from a CSV file df = pd.read_csv("scraped_data.csv") # Display first five rows print(df.head()) With Pandas, you can quickly clean and analyze scraped data, making it more useful for decision-making. In the next section, we will explore different data cleaning techniques using Pandas. Cleaning Scraped Data with Pandas Raw scraped data often contains missing values, duplicate records, inconsistent formatting, and irrelevant information. Cleaning the data ensures accuracy and improves analysis. Pandas provides efficient methods to handle these issues. Handling Missing Values Missing values can appear due to incomplete data extraction. Pandas offers multiple ways to deal with them: import pandas as pd # Load scraped data df = pd.read_csv("scraped_data.csv") # Check for missing values print(df.isnull().sum()) # Remove rows with missing values df_cleaned = df.dropna() # Fill missing values with a default value df_filled = df.fillna("Not Available") Removing Duplicates Scraped data may contain repeated records, which can skew analysis. You can remove duplicates using Pandas: # Remove duplicate rows df_unique = df.drop_duplicates() # Keep the first occurrence and remove others df_no_duplicates = df.drop_duplicates(keep="first") Standardizing Data Formats Inconsistent data formats can cause errors. You can standardize text cases, date formats, and numerical values: # Convert text to lowercase df["product_name"] = df["product_name"].str.lower() # Standardize date format df["date"] = pd.to_datetime(df["date"], format="%Y-%m-%d") # Normalize numerical data df["price"] = df["price"].astype(float) Filtering Out Irrelevant Data Unnecessary columns or rows can be removed to keep only valuable information: # Drop unwanted columns df_filtered = df.drop(columns=["unnecessary_column"]) # Keep only rows that meet a condition df_filtered = df[df["price"] > 10] Cleaning data is a crucial step before analysis. Once the data is structured and refined, we can apply Pandas functions to extract insights, which we’ll explore in the next section. Analyzing Scraped Data with Pandas Once your scraped data is clean, the next step is to analyze it for meaningful insights. Pandas makes it easy to sort, group, aggregate, and visualize data, helping you uncover trends and patterns. Sorting and Aggregating Data Sorting helps organize data, while aggregation summarizes it based on key metrics. import pandas as pd # Load cleaned data df = pd.read_csv("cleaned_data.csv") # Sort by price in descending order df_sorted = df.sort_values(by="price", ascending=False) # Aggregate data to find the average price per category average_price = df.groupby("category")["price"].mean() print(average_price) Extracting Insights with Grouping Grouping data allows you to analyze patterns across different categories. # Count the number of products per category product_count = df.groupby("category")["product_name"].count() # Find the highest-priced product in each category highest_price = df.groupby("category")["price"].max() print(product_count) print(highest_price) Applying Statistical Functions Pandas provides built-in statistical methods to analyze numerical data. # Get basic statistics about prices print(df["price"].describe()) # Calculate median and standard deviation median_price = df["price"].median() std_dev_price

This blog was initially posted to Crawlbase Blog
Collecting data from the web can be messy, with missing values, duplicates, and inconsistent formats. To use it, you need to clean and analyze. That’s where Python Pandas comes in.
Pandas is a powerful library that helps structure, clean, and analyze data. It allows you to remove errors, filter what’s relevant and extract insights easily.
In this guide we’ll cover why data cleaning matters, how to use Pandas for processing and key techniques to clean and analyze scraped data.
Python Pandas for Data Processing
Pandas is a powerful Python library for working with structured data. It helps in organizing, cleaning, and analyzing big datasets. When dealing with scraped data, Pandas has many functions to handle missing values, remove duplicates, filter info, and extract insights.
The core data structures in Pandas are DataFrame and Series. A DataFrame is a table-like structure where data is stored in rows and columns, like an Excel sheet. A Series is a single column of a DataFrame. These structures make it easy to manipulate and transform scraped data.
Using Pandas you can:
- Load data from CSV, JSON or databases.
- Clean data by handling missing values and formatting.
- Analyze data by sorting, grouping, and applying statistical functions.
- Visualize insights with built-in plotting functions.
For example, loading scraped data into a Pandas DataFrame is as simple as:
import pandas as pd
# Load scraped data from a CSV file
df = pd.read_csv("scraped_data.csv")
# Display first five rows
print(df.head())
With Pandas, you can quickly clean and analyze scraped data, making it more useful for decision-making. In the next section, we will explore different data cleaning techniques using Pandas.
Cleaning Scraped Data with Pandas
Raw scraped data often contains missing values, duplicate records, inconsistent formatting, and irrelevant information. Cleaning the data ensures accuracy and improves analysis. Pandas provides efficient methods to handle these issues.
Handling Missing Values
Missing values can appear due to incomplete data extraction. Pandas offers multiple ways to deal with them:
import pandas as pd
# Load scraped data
df = pd.read_csv("scraped_data.csv")
# Check for missing values
print(df.isnull().sum())
# Remove rows with missing values
df_cleaned = df.dropna()
# Fill missing values with a default value
df_filled = df.fillna("Not Available")
Removing Duplicates
Scraped data may contain repeated records, which can skew analysis. You can remove duplicates using Pandas:
# Remove duplicate rows
df_unique = df.drop_duplicates()
# Keep the first occurrence and remove others
df_no_duplicates = df.drop_duplicates(keep="first")
Standardizing Data Formats
Inconsistent data formats can cause errors. You can standardize text cases, date formats, and numerical values:
# Convert text to lowercase
df["product_name"] = df["product_name"].str.lower()
# Standardize date format
df["date"] = pd.to_datetime(df["date"], format="%Y-%m-%d")
# Normalize numerical data
df["price"] = df["price"].astype(float)
Filtering Out Irrelevant Data
Unnecessary columns or rows can be removed to keep only valuable information:
# Drop unwanted columns
df_filtered = df.drop(columns=["unnecessary_column"])
# Keep only rows that meet a condition
df_filtered = df[df["price"] > 10]
Cleaning data is a crucial step before analysis. Once the data is structured and refined, we can apply Pandas functions to extract insights, which we’ll explore in the next section.
Analyzing Scraped Data with Pandas
Once your scraped data is clean, the next step is to analyze it for meaningful insights. Pandas makes it easy to sort, group, aggregate, and visualize data, helping you uncover trends and patterns.
Sorting and Aggregating Data
Sorting helps organize data, while aggregation summarizes it based on key metrics.
import pandas as pd
# Load cleaned data
df = pd.read_csv("cleaned_data.csv")
# Sort by price in descending order
df_sorted = df.sort_values(by="price", ascending=False)
# Aggregate data to find the average price per category
average_price = df.groupby("category")["price"].mean()
print(average_price)
Extracting Insights with Grouping
Grouping data allows you to analyze patterns across different categories.
# Count the number of products per category
product_count = df.groupby("category")["product_name"].count()
# Find the highest-priced product in each category
highest_price = df.groupby("category")["price"].max()
print(product_count)
print(highest_price)
Applying Statistical Functions
Pandas provides built-in statistical methods to analyze numerical data.
# Get basic statistics about prices
print(df["price"].describe())
# Calculate median and standard deviation
median_price = df["price"].median()
std_dev_price = df["price"].std()
print(f"Median Price: {median_price}")
print(f"Standard Deviation: {std_dev_price}")
Visualizing Data with Pandas
Visual representation of data makes analysis easier. Pandas integrates with Matplotlib for basic data visualization.
import matplotlib.pyplot as plt
# Bar chart of product count per category
product_count.plot(kind="bar", title="Number of Products per Category")
plt.xlabel("Category")
plt.ylabel("Count")
plt.show()
# Histogram of price distribution
df["price"].plot(kind="hist", bins=20, title="Price Distribution")
plt.xlabel("Price")
plt.show()
By leveraging Pandas for analysis, you can extract valuable insights from scraped data. In the next section, we’ll discuss best practices for efficient data cleaning and analysis.
This blog was initially posted to Crawlbase Blog