






























































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)













































































































































































































































































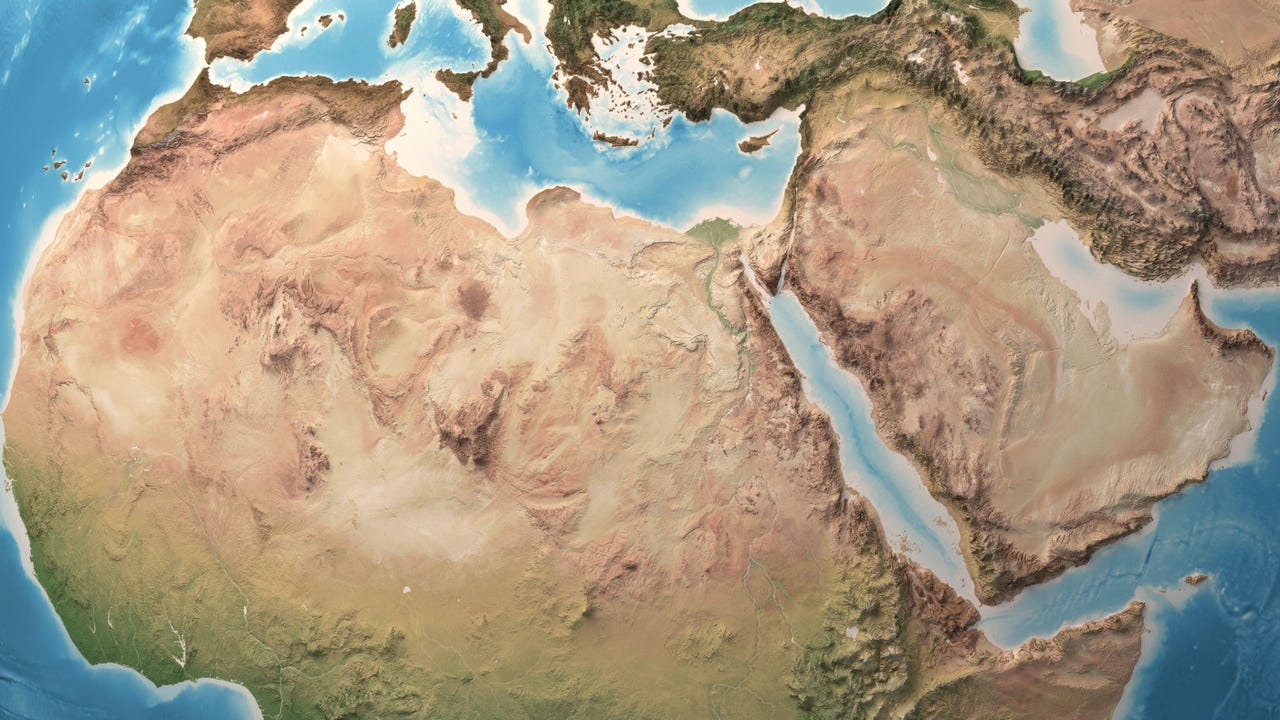


























































































![Hostinger Horizons lets you effortlessly turn ideas into web apps without coding [10% off]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/IMG_1551.png?resize=1200%2C628&quality=82&strip=all&ssl=1)


![This new Google TV streaming dongle looks just like a Chromecast [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/04/thomson-cast-150-google-tv-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Drops New Immersive Adventure Episode for Vision Pro: 'Hill Climb' [Video]](https://www.iclarified.com/images/news/97133/97133/97133-640.jpg)

![Most iPhones Sold in the U.S. Will Be Made in India by 2026 [Report]](https://www.iclarified.com/images/news/97130/97130/97130-640.jpg)






























































































































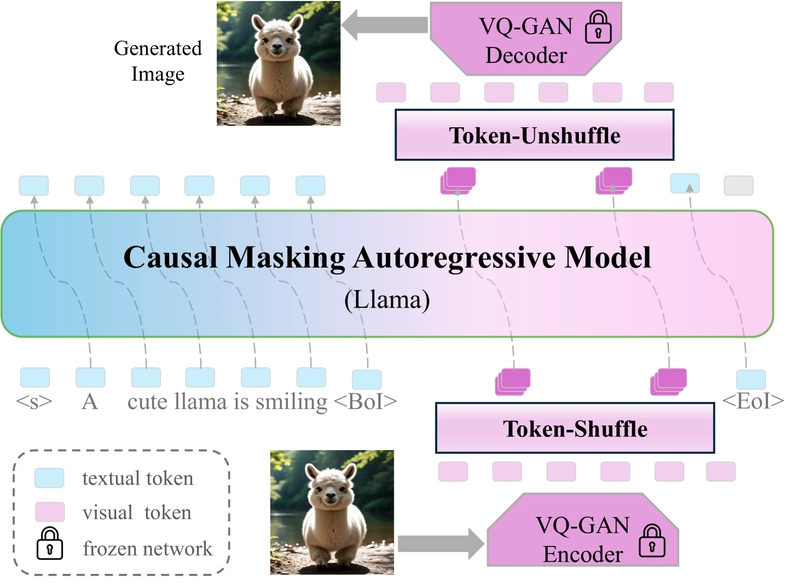
Token-Shuffle: Autoregressive Models Generate High-Res Images
This is a Plain English Papers summary of a research paper called Token-Shuffle: Autoregressive Models Generate High-Res Images. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Solving the Token Bottleneck in Autoregressive Image Generation Autoregressive (AR) models have dominated language generation but struggle with image synthesis compared to diffusion-based models. Their primary limitation is the substantial number of image tokens required, which restricts both training and inference efficiency as well as image resolution. Token-Shuffle presents a novel solution that reduces the number of visual tokens processed by Transformer models. The key insight: visual vocabularies in Multimodal Large Language Models (MLLMs) contain dimensional redundancy, as low-dimensional visual codes from the visual encoder get mapped to high-dimensional language vocabularies. Token-Shuffle Pipeline: a plug-and-play operation pair for reducing visual token number in MLLMs, comprising a token-shuffle operation to merge spatially local visual tokens for Transformer input and a token-unshuffle operation to disentangle inferred visual tokens. The approach uses two key operations: Token-shuffle - merges spatially local tokens along the channel dimension to decrease input token number Token-unshuffle - untangles the inferred tokens after Transformer blocks to restore spatial arrangement For the first time, this method pushes AR text-to-image generation to a resolution of 2048×2048 with impressive generation quality. The 2.7B parameter model achieves a 0.77 overall score on hard prompts in GenAI-benchmark, outperforming AR models like LlamaGen by 0.18 and diffusion models like LDM by 0.15. Current Landscape of Text-to-Image Generation Models Text-to-image generation has seen remarkable progress, with diffusion models like Stable Diffusion dominating the field. AR models, however, offer potential advantages for unified multimodal systems if their limitations can be overcome. Two primary strategies exist for image generation in MLLMs: Continuous visual tokens - deliver superior image quality with fewer tokens but require extensive modifications to the LLM pipeline Discrete visual tokens - more compatible with LLMs but require quadratically more tokens as resolution increases Real-world MLLM applications like EMU3 and Chameleon predominantly adopt discrete visual tokens, applying the "next-token prediction" paradigm to image generation. These models convert images into discrete tokens, allowing autoregressive Transformers to generate images similarly to text generation. While demonstrating impressive capabilities, they face substantial resolution limitations. Unlike language, which typically requires dozens to hundreds of tokens, images demand thousands - often 4K visual tokens for a 1024×1024 resolution image. This makes both training and inference prohibitively costly due to the quadratic computational complexity of Transformers, as explored in Beyond Next Token: Next X Prediction in Autoregressive Models. Token-Shuffle: A Novel Method for Reducing Visual Tokens Foundation and Architecture Token-Shuffle builds on a decoder-only autoregressive Transformer model (LLaMA) for language modeling. The model processes the conditional probability of each token based on previous tokens, using standard cross-entropy loss for training. For image synthesis, the researchers incorporate discrete visual tokens into the model's vocabulary using a pretrained VQGAN model that down-samples input resolution by a factor of 16. The VQGAN codebook contains 16,384 tokens concatenated with LLaMA's original vocabulary, plus special tokens to mark image boundaries. The Challenge of High-Resolution Images The prohibitive token count for high-resolution images represents a fundamental limitation. A 1024×1024 image requires 4K visual tokens, while a 2048×2048 image demands 16K tokens - impractical for effective training and efficient inference with next-token prediction. Illustration of visual vocabulary dimensional redundancy. Left: Two MLPs reduce visual token rank by a factor of r. Right: Pre-training loss for different r values, showing substantial dimension reduction with minimal performance impact. Visual Dimensional Redundancy A key insight driving Token-Shuffle is the dimensional redundancy in visual vocabularies. When appending visual codebook tokens to language vocabularies, the embedding dimensionality increases substantially - often jumping from around 256 dimensions to 3072 or 4096 dimensions. Experiments show this redundancy allows compression of visual token dimension by up to a factor of 8 without significantly impacting generation quality. Token-Shuffle Operations Token-Shuffle leverages this redundancy to reduce visual token counts in Transformers, improving computational efficiency and enabling high-
This is a Plain English Papers summary of a research paper called Token-Shuffle: Autoregressive Models Generate High-Res Images. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Solving the Token Bottleneck in Autoregressive Image Generation
Autoregressive (AR) models have dominated language generation but struggle with image synthesis compared to diffusion-based models. Their primary limitation is the substantial number of image tokens required, which restricts both training and inference efficiency as well as image resolution.
Token-Shuffle presents a novel solution that reduces the number of visual tokens processed by Transformer models. The key insight: visual vocabularies in Multimodal Large Language Models (MLLMs) contain dimensional redundancy, as low-dimensional visual codes from the visual encoder get mapped to high-dimensional language vocabularies.
Token-Shuffle Pipeline: a plug-and-play operation pair for reducing visual token number in MLLMs, comprising a token-shuffle operation to merge spatially local visual tokens for Transformer input and a token-unshuffle operation to disentangle inferred visual tokens.
The approach uses two key operations:
- Token-shuffle - merges spatially local tokens along the channel dimension to decrease input token number
- Token-unshuffle - untangles the inferred tokens after Transformer blocks to restore spatial arrangement
For the first time, this method pushes AR text-to-image generation to a resolution of 2048×2048 with impressive generation quality. The 2.7B parameter model achieves a 0.77 overall score on hard prompts in GenAI-benchmark, outperforming AR models like LlamaGen by 0.18 and diffusion models like LDM by 0.15.
Current Landscape of Text-to-Image Generation Models
Text-to-image generation has seen remarkable progress, with diffusion models like Stable Diffusion dominating the field. AR models, however, offer potential advantages for unified multimodal systems if their limitations can be overcome.
Two primary strategies exist for image generation in MLLMs:
- Continuous visual tokens - deliver superior image quality with fewer tokens but require extensive modifications to the LLM pipeline
- Discrete visual tokens - more compatible with LLMs but require quadratically more tokens as resolution increases
Real-world MLLM applications like EMU3 and Chameleon predominantly adopt discrete visual tokens, applying the "next-token prediction" paradigm to image generation. These models convert images into discrete tokens, allowing autoregressive Transformers to generate images similarly to text generation. While demonstrating impressive capabilities, they face substantial resolution limitations.
Unlike language, which typically requires dozens to hundreds of tokens, images demand thousands - often 4K visual tokens for a 1024×1024 resolution image. This makes both training and inference prohibitively costly due to the quadratic computational complexity of Transformers, as explored in Beyond Next Token: Next X Prediction in Autoregressive Models.
Token-Shuffle: A Novel Method for Reducing Visual Tokens
Foundation and Architecture
Token-Shuffle builds on a decoder-only autoregressive Transformer model (LLaMA) for language modeling. The model processes the conditional probability of each token based on previous tokens, using standard cross-entropy loss for training.
For image synthesis, the researchers incorporate discrete visual tokens into the model's vocabulary using a pretrained VQGAN model that down-samples input resolution by a factor of 16. The VQGAN codebook contains 16,384 tokens concatenated with LLaMA's original vocabulary, plus special tokens to mark image boundaries.
The Challenge of High-Resolution Images
The prohibitive token count for high-resolution images represents a fundamental limitation. A 1024×1024 image requires 4K visual tokens, while a 2048×2048 image demands 16K tokens - impractical for effective training and efficient inference with next-token prediction.
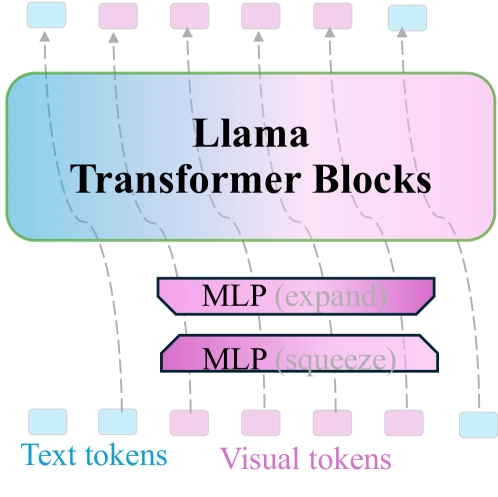
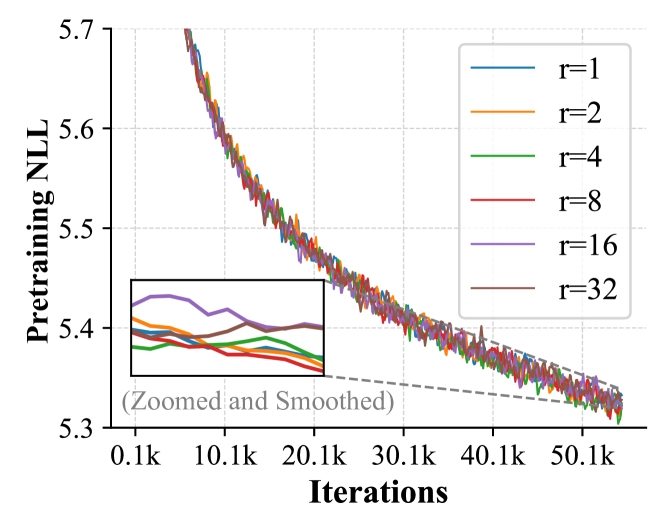
Illustration of visual vocabulary dimensional redundancy. Left: Two MLPs reduce visual token rank by a factor of r. Right: Pre-training loss for different r values, showing substantial dimension reduction with minimal performance impact.
Visual Dimensional Redundancy
A key insight driving Token-Shuffle is the dimensional redundancy in visual vocabularies. When appending visual codebook tokens to language vocabularies, the embedding dimensionality increases substantially - often jumping from around 256 dimensions to 3072 or 4096 dimensions.
Experiments show this redundancy allows compression of visual token dimension by up to a factor of 8 without significantly impacting generation quality.
Token-Shuffle Operations
Token-Shuffle leverages this redundancy to reduce visual token counts in Transformers, improving computational efficiency and enabling high-resolution image generation as examined in Elucidating the Design Space of Language Models for Image Generation.
The method shuffles spatially local visual tokens into single tokens before feeding them into the Transformer. A shared MLP layer compresses visual token dimensions, ensuring the fused token maintains the original dimension. With a local shuffle window size of s, this reduces token number by a factor of s², significantly reducing computational burden.
Token-Shuffle can enhance efficiency quadratically. For instance, with a shuffle window size s=2, we achieve approximately a 4× reduction in both training FLOPs and token number. Considering the use of KV-cache during inference, inference time scales roughly linearly with the token number.
For recovery, a token-unshuffle operation disentangles the fused tokens back into their local visual tokens, with MLP layers restoring original dimensionality. This approach predicts the next fused token rather than individual tokens, allowing multiple local visual tokens to be generated in a single step.
CFG Scheduler for AR Image Generation
The researchers incorporate classifier-free guidance (CFG) during both training and inference, a technique widely used in diffusion models. They randomly drop 10% of prompts during training, creating unconditional samples. During inference, they adjust logits using a weighted combination of conditional and unconditional predictions.

Comparison of different CFG schedulers with a monotonic increase in CFG scale from 1 to 7.5. Right: CFG-scheduler improves both visual aesthetics and text alignment, compared to the baseline of a consistent CFG value of 7.5 across all visual tokens.
Since AR models differ fundamentally from diffusion models, the researchers introduce a new inference CFG-scheduler to improve image generation quality. This approach minimizes the influence of unconditional logits on early visual tokens to prevent artifacts, with the CFG having cumulative impact from first to last token.
Training and Evaluating Token-Shuffle
Training Process
The experiments used the 2.7B Llama model with 20 autoregressive Transformer blocks. Training occurred in three stages, gradually increasing resolution:
- 512×512 resolution - No Token-Shuffle needed due to manageable token count; trained on ~50 billion tokens with 4K sequence length
- 1024×1024 resolution - Introduced Token-Shuffle for efficiency; scaled to 2TB training tokens
- 2048×2048 resolution - Further scaled with special stabilization techniques; trained on ~300 billion tokens
Image captions were rewritten by Llama3 to generate detailed prompts, improving generation quality. The researchers fine-tuned models at different stages on 1,500 selected high-quality images for presentation.
Quantitative Results
Token-Shuffle demonstrates strong performance on benchmarks, outperforming other autoregressive models and competing with diffusion-based approaches.
| Model | Type | "Basic" prompts | "Hard" prompts | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Attribute | Scene | Relation | Overall | Count | Differ | Compare | Logical | Overall | |||||
| Spatial | Action | Part | Nogate | Universal | |||||||||
| SDXL-v2.1 | Diff. | 0.80 | 0.79 | 0.76 | 0.77 | 0.80 | 0.78 | 0.68 | 0.70 | 0.68 | 0.54 | 0.64 | 0.62 |
| SD-XL Turbo | Diff. | 0.85 | 0.85 | 0.80 | 0.82 | 0.89 | 0.84 | 0.72 | 0.74 | 0.70 | 0.52 | 0.65 | 0.65 |
| DeepFlow44F Saluzzo et al. (2022) | Diff. | 0.83 | 0.85 | 0.81 | 0.82 | 0.89 | 0.84 | 0.74 | 0.74 | 0.71 | 0.53 | 0.68 | 0.66 |
| Midjourney v6 | Diff. | 0.88 | 0.87 | 0.87 | 0.87 | 0.91 | 0.87 | 0.78 | 0.78 | 0.79 | 0.50 | 0.76 | 0.69 |
| DALL-E 3 Betker et al. (2023) | Diff. | 0.91 | 0.90 | 0.92 | 0.89 | 0.91 | 0.90 | 0.82 | 0.78 | 0.82 | 0.48 | 0.80 | 0.70 |
| LlamaGen Sun et al. (2024a) | AR | 0.75 | 0.75 | 0.74 | 0.76 | 0.75 | 0.74 | 0.63 | 0.68 | 0.69 | 0.48 | 0.63 | 0.59 |
| Lmanian-mGPT-TB Liu et al. (2024) | AR | 0.84 | 0.85 | 0.82 | 0.84 | 0.93 | 0.83 | 0.75 | 0.69 | 0.73 | 0.47 | 0.69 | 0.63 |
| EMU3 Wang et al. (2024b) | AR | 0.78 | 0.81 | 0.77 | 0.78 | 0.87 | 0.78 | 0.69 | 0.62 | 0.70 | 0.45 | 0.69 | 0.60 |
| SEED-X Ge et al. (2024) | AR+Diff. | 0.86 | 0.88 | 0.85 | 0.85 | 0.90 | 0.86 | 0.79 | 0.77 | 0.77 | 0.56 | 0.73 | 0.70 |
| Token-Shuffle | AR | 0.78 | 0.77 | 0.80 | 0.76 | 0.83 | 0.78 | 0.76 | 0.74 | 0.74 | 0.58 | 0.64 | 0.67 |
| Token-Shuffle $\dagger$ | AR | 0.88 | 0.88 | 0.88 | 0.87 | 0.91 | 0.88 | 0.81 | 0.82 | 0.81 | 0.68 | 0.78 | 0.77 |
VQAScore evaluation of image generation on GenAI-Bench. "$\dagger$" indicates that images are generated by Llama3-rewritten prompts to match the caption length in the training data, for training-inference consistency.
On GenAI-Bench, Token-Shuffle outperforms LlamaGen by 0.14 on "basic" prompts and 0.18 on "hard" prompts. It even surpasses DALL-E 3 by 0.07 on "hard" prompts.
Results on the GenEval benchmark further demonstrate Token-Shuffle's capabilities compared to both AR and diffusion models:
| Method | Type | # Params | Single Obj. | Two Obj. | Counting | Colors | Position | Color Attri. | Overall $\dagger$ |
|---|---|---|---|---|---|---|---|---|---|
| LDM Rombach et al. (2022) | Diff. | 1.4 B | 0.92 | 0.29 | 0.23 | 0.70 | 0.02 | 0.05 | 0.37 |
| SDv1.5 Rombach et al. (2022) | Diff. | 0.9 B | 0.97 | 0.38 | 0.35 | 0.76 | 0.04 | 0.06 | 0.43 |
| PixArt-alpha Chen et al. (2024) | Diff. | 0.6 B | 0.98 | 0.50 | 0.44 | 0.80 | 0.08 | 0.07 | 0.48 |
| SDv2.1 Rombach et al. (2022) | Diff. | 0.9 B | 0.98 | 0.51 | 0.44 | 0.85 | 0.07 | 0.17 | 0.50 |
| DALL-E 2 Ramesh et al. (2022) | Diff. | 6.5 B | 0.94 | 0.66 | 0.49 | 0.77 | 0.10 | 0.19 | 0.52 |
| SDXL Podell et al. (2023) | Diff. | 2.6 B | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 | 0.55 |
| SD3 Esser et al. (2024) | Diff. | 2 B | 0.98 | 0.74 | 0.63 | 0.67 | 0.34 | 0.36 | 0.62 |
| Show-o Xie et al. (2024b) | AR. + Diff. | 1.3 B | 0.95 | 0.52 | 0.49 | 0.82 | 0.11 | 0.28 | 0.53 |
| SEED-X Ge et al. (2024) | AR. + Diff. | 17 B | 0.97 | 0.58 | 0.26 | 0.80 | 0.19 | 0.14 | 0.49 |
| Transfusion Zhou et al. (2024) | AR. + Diff. | 7.3 B | - | - | - | - | - | - | 0.63 |
| LlamaGen Sun et al. (2024a) | AR. | 0.8 B | 0.71 | 0.34 | 0.21 | 0.58 | 0.07 | 0.04 | 0.32 |
| Chameleon Teum (2024) | AR. | 7 B | - | - | - | - | - | - | 0.39 |
| EMU3 Wang et al. (2024b) | AR. | 8 B | - | - | - | - | - | - | 0.66 |
| EMU3-DPO Wang et al. (2024b) | AR. | 8 B | - | - | - | - | - | - | 0.64 |
| Enni3-Gen Wang et al. (2024b) | AR. | 8 B | 0.98 | 0.71 | 0.34 | 0.81 | 0.17 | 0.21 | 0.54 |
| Janus Wu et al. (2024) | AR. | 1.3 B | 0.97 | 0.68 | 0.30 | 0.84 | 0.46 | 0.42 | 0.61 |
| Token-Shuffle $\dagger$ | AR. | 2.7 B | 0.96 | 0.81 | 0.37 | 0.78 | 0.40 | 0.39 | 0.62 |
Evaluation on the GenEval benchmark. Similar to ours results, EMU3 and EMU3-DPO also consider prompt rewriting, and results of EMU3-Gen are from Janus Wu et al. (2024). These results indicate Token-Shuffle can also present promising generation quality besides high-resolution.
Human Evaluation
Beyond automated metrics, the researchers conducted large-scale human evaluations on the GenAI-bench prompts, focusing on three key aspects:
- Text alignment (accuracy in reflecting prompts)
- Visual flaws (checking for logical consistency)
- Visual appearance (aesthetic quality)
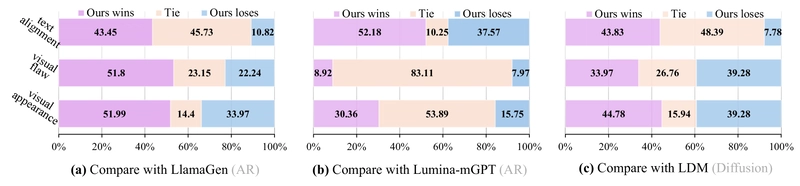
Human evaluation comparing Token-Shuffle with LlamaGen (AR-based model without text), Lumina-mGPT (AR-based model with text) and LDM (diffusion-based model) on text alignment, visual flaws, and visual appearance.
Token-Shuffle consistently outperformed AR-based models LlamaGen and Lumina-mGPT across all aspects. This suggests that Token-Shuffle effectively preserves aesthetic details and closely adheres to textual guidance even with reduced token count. Compared to diffusion-based LDM, Token-Shuffle performed comparably or better in terms of visual appearance and text alignment, though slightly worse in visual flaws.
Visual Comparisons
Visual comparisons with other models - including diffusion-based LDM and Pixart-LCM, and autoregressive LlamaGen - demonstrated Token-Shuffle's strengths in text alignment and visual quality.

Visual comparison with other open-source diffusion-based and AR-based models (zoom in for details).
Token-Shuffle aligned more closely with text prompts than other models, likely due to joint training of text and image within a unified MLLM-style model. Compared to LlamaGen, Token-Shuffle achieved higher resolution at the same inference cost, offering improved visual quality and text alignment.
Analyzing Token-Shuffle Design Choices
The researchers explored several variations of Token-Shuffle to determine optimal configurations:
Shuffle Window Sizes
Different Token-Shuffle window sizes offer varying trade-offs between efficiency and generation quality. Larger window sizes further reduce token count but impact generation quality.

Visual comparison of different Token-Shuffle window sizes. We tested each prompt with fixed random seeds and reported the VQAScore Lin et al. (2024) in the bottom-right corner.
As shown in the figure, window sizes of 2 provide a good balance between efficiency and quality, while window sizes of 4 noticeably degrade quality.
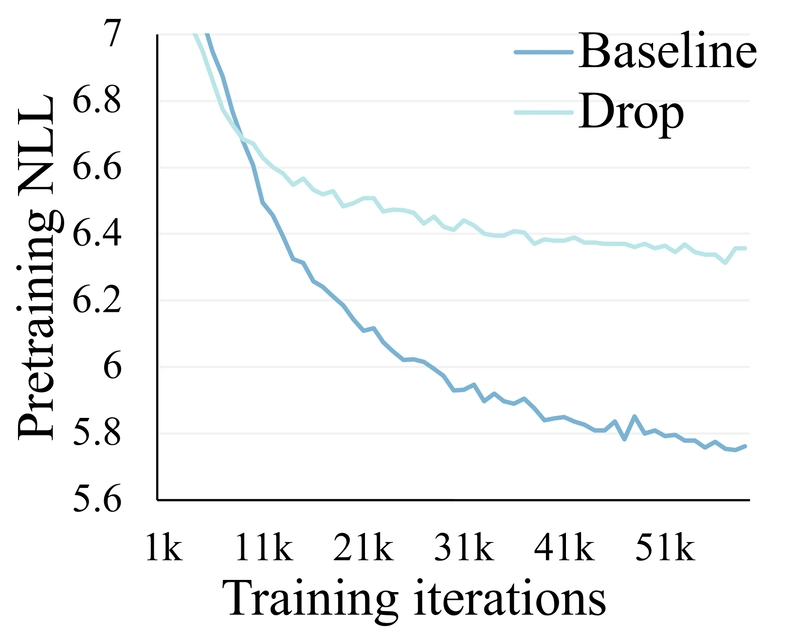
Training losses for different shuffle window sizes.
Increasing window size leads to higher training loss and reduced generation quality, which is expected as a single fused token represents more visual tokens and reduces computation in the Transformer.
MLP Block Variations
The researchers tested different configurations of MLP blocks within Token-Shuffle:
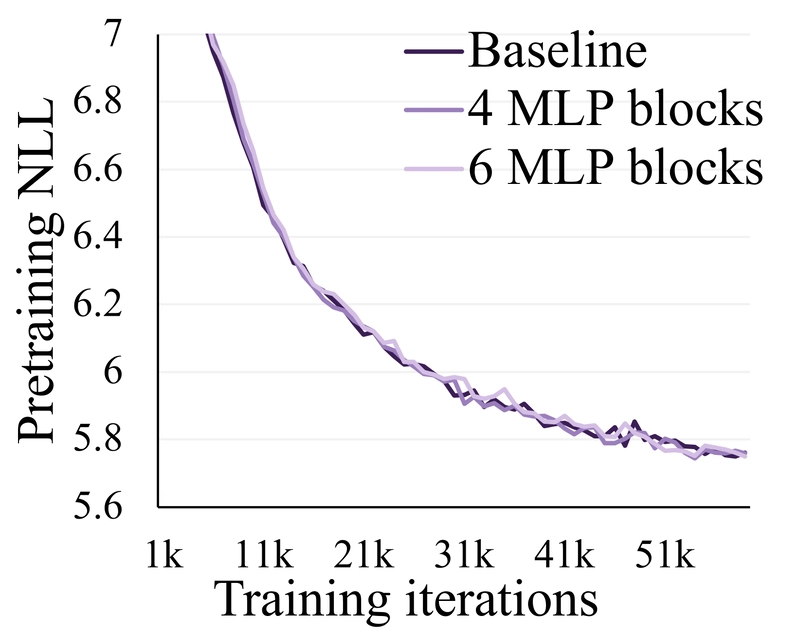
Effectiveness comparison of various Token-Shuffle implementations with different numbers of MLP blocks.
Adding more MLP blocks in Token-Shuffle operations did not lead to noticeable improvements. Other experiments revealed that retaining all visual tokens is crucial, and additional positional embeddings don't enhance performance.
Alternative approaches like Re-sampler and simplified versions performed worse than the standard Token-Shuffle implementation, highlighting the effectiveness of the chosen design, as explored in D2C: Unlocking the Potential of Continuous Autoregressive Image Generation.
Comparing with High-Compression VQGAN
The researchers also compared Token-Shuffle with a high-compression VQGAN approach - another strategy for reducing token count in image generation as studied in ControLAR: Controllable Image Generation with Autoregressive Models:
| Model | "Basic" prompts | "Hard" prompts | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Attribute | Scene | Relation | Overall | Count | Differ | Compare | Logical | Overall | ||||
| Spatial | Action | Part | Negate | Universal | ||||||||
| D16 | 0.80 | 0.82 | 0.79 | 0.79 | 0.86 | 0.80 | 0.72 | 0.71 | 0.73 | 0.65 | 0.75 | 0.71 |
| D8+TS | 0.82 | 0.85 | 0.82 | 0.82 | 0.84 | 0.82 | 0.77 | 0.77 | 0.77 | 0.66 | 0.74 | 0.72 |
VQAScore evaluation comparing high-compression VQGAN (D16) with Token-Shuffle approach (D8+TS). D16 indicates a high-compress VQGAN with a down-sampling ratio of 16, while D8+TS indicates a low-compress VQGAN with a down-sampling ratio of 8 and Token-Shuffle window size of 2.
Token-Shuffle consistently outperformed the high-compression VQGAN approach in both automatic evaluation and human assessment, providing better generation quality with the same computational cost.
Key Implementation Details and Practical Considerations
High-Resolution Training Challenges
Training at very high resolutions (2048×2048) presented unique challenges. Unlike stable training at lower resolutions, the 2048×2048 resolution training became unstable after several thousand iterations, with loss increasing significantly.
The researchers explored several solutions:
- Reducing learning rate (ineffective)
- Applying loss weights to visual tokens (ineffective)
- Adding QK-Norm to each attention layer (partially effective)
- Incorporating z-loss (most effective)
The final solution combined QK-Norm and z-loss to stabilize training at the highest resolution.
Inference Implementation
During inference, the model needed to consistently generate complete images rather than continuing with text or producing mixed text-image tokens. The researchers addressed this by:
- Introducing a special token
<|start_of_image|>to ensure image generation after the prompt - Enforcing structural generation by restricting tokens following this special token to the visual vocabulary
This approach ensured reliable, complete image generation.
Additional Insights on Token-Shuffle
CFG Scheduler Optimization
Classifier-free guidance (CFG) enhances generation quality by balancing prompt fidelity with visual coherence. The researchers systematically evaluated different CFG scales from 1.0 to 11.0, finding that a value of 7.5 struck the optimal balance between performance and visual quality.
The half-linear CFG scheduler they developed improved both visual aesthetics and text alignment compared to a constant CFG value.
Causal Attention Masks
Token-Shuffle maintains the standard next-token prediction mechanism without altering the original causal mask used in LLMs. However, it introduces a modified approach where the disentangled tokens have mutual interactions within the spatial local window.
This design strikes a balance between bi-directional approaches that allow global token interactions and strict causal approaches, enabling better local details while preserving the AR framework.
Visual Flaws in AR Models
Despite Token-Shuffle's improvements, AR-based models still produce occasional visual flaws compared to diffusion models. These stem not from information loss in VQGAN but from limited global interaction inherent to causal masking and the next-token prediction framework.
While Token-Shuffle introduces local mutual interactions, it still faces this fundamental limitation. Exploring approaches that maintain the next-token prediction framework while enabling global interactions remains an important direction for future research.
Limitations and Future Directions
Token-Shuffle represents a significant advance in AR-based image generation, but several limitations and future directions remain:
- Model scaling - The current implementation uses a 2.7B parameter model, but scaling to larger models (7B, 30B) could yield further improvements
- Flexible resolutions and aspect ratios - Supporting variable image shapes similar to EMU3 would enhance versatility
- Global interactions - AR models still struggle with global coherence due to causal attention constraints
Despite these limitations, Token-Shuffle serves as a foundational design for efficient high-resolution image generation within MLLMs, pushing the boundaries of what's possible with autoregressive text-to-image generation.


