






























































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)







































































































































































































































































































































































![Hostinger Horizons lets you effortlessly turn ideas into web apps without coding [10% off]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/IMG_1551.png?resize=1200%2C628&quality=82&strip=all&ssl=1)


![This new Google TV streaming dongle looks just like a Chromecast [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/04/thomson-cast-150-google-tv-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Drops New Immersive Adventure Episode for Vision Pro: 'Hill Climb' [Video]](https://www.iclarified.com/images/news/97133/97133/97133-640.jpg)

![Most iPhones Sold in the U.S. Will Be Made in India by 2026 [Report]](https://www.iclarified.com/images/news/97130/97130/97130-640.jpg)






























































































































SRPO: LLM Reinforcement Learning Breakthrough - 20% Better, Faster Training!
This is a Plain English Papers summary of a research paper called SRPO: LLM Reinforcement Learning Breakthrough - 20% Better, Faster Training!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview Novel SRPO (Scalable Reinforcement Learning for LLMs) method introduced Focuses on cross-domain implementation and scalability Builds on GRPO (General Reinforcement Learning for LLMs) Shows significant performance improvements across tasks Introduces efficient training template system Plain English Explanation Reinforcement learning helps AI systems learn from experience, like how humans learn from trial and error. SRPO makes this process work better for large language models across different ... Click here to read the full summary of this paper
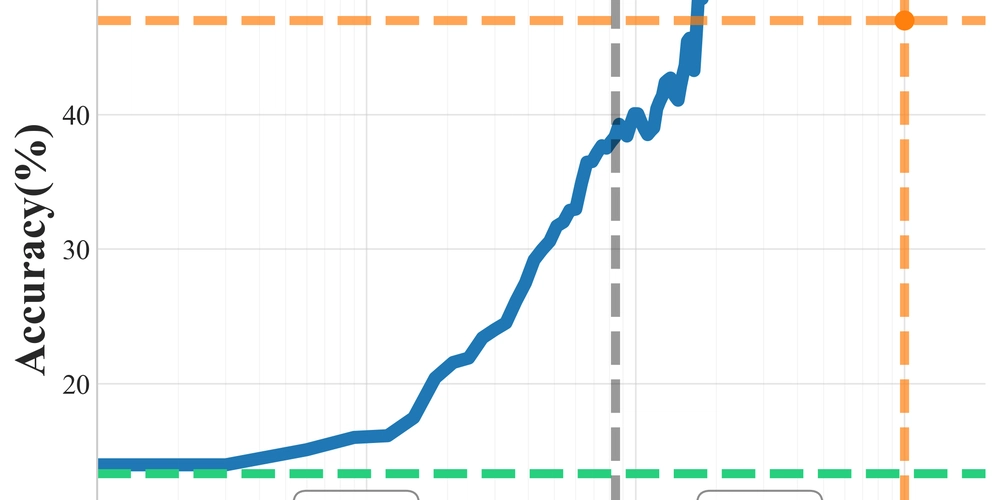
This is a Plain English Papers summary of a research paper called SRPO: LLM Reinforcement Learning Breakthrough - 20% Better, Faster Training!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- Novel SRPO (Scalable Reinforcement Learning for LLMs) method introduced
- Focuses on cross-domain implementation and scalability
- Builds on GRPO (General Reinforcement Learning for LLMs)
- Shows significant performance improvements across tasks
- Introduces efficient training template system
Plain English Explanation
Reinforcement learning helps AI systems learn from experience, like how humans learn from trial and error. SRPO makes this process work better for large language models across different ...


