![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)





































































































































































































































































































































































![Hostinger Horizons lets you effortlessly turn ideas into web apps without coding [10% off]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/IMG_1551.png?resize=1200%2C628&quality=82&strip=all&ssl=1)




![This new Google TV streaming dongle looks just like a Chromecast [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/04/thomson-cast-150-google-tv-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)












![Apple Drops New Immersive Adventure Episode for Vision Pro: 'Hill Climb' [Video]](https://www.iclarified.com/images/news/97133/97133/97133-640.jpg)

![Most iPhones Sold in the U.S. Will Be Made in India by 2026 [Report]](https://www.iclarified.com/images/news/97130/97130/97130-640.jpg)





























































































































New Dataset: LLM Guardrails Beat GPT-4o by 21%!
This is a Plain English Papers summary of a research paper called New Dataset: LLM Guardrails Beat GPT-4o by 21%!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Why LLM Pipelines Need Better Guardrails Large language models (LLMs) have become essential components in specialized data processing pipelines across finance, marketing, and e-commerce. However, when running in production environments, they frequently fail to follow instructions or meet developer expectations. To improve reliability, developers need assertions or guardrails for LLM outputs — but determining the right set of assertions that capture requirements for a specific task is challenging. A new dataset called PROMPTEVALS addresses this need, providing 2087 LLM pipeline prompts with 12623 corresponding assertion criteria sourced from developers using open-source LLM pipeline tools. This collection is five times larger than previous datasets and can support further research in LLM reliability, alignment, and prompt engineering. Notably, the researchers' fine-tuned Mistral and Llama 3 models outperform GPT-4o by nearly 21% on average, while offering reduced latency and improved performance. The dataset serves as a benchmark to evaluate how effectively LLMs can generate assertion criteria for prompts, addressing a critical gap in LLM evaluation methods. Understanding the Context: Related Work Prompt Engineering Challenges Prompt engineering is crucial for steering LLMs toward following instructions for specific tasks. Techniques like chain-of-thought and few-shot prompting improve model performance, but despite these advancements, LLMs still hallucinate and make mistakes. No technique ensures consistent adherence to instructions, especially in diverse production environments. As developers iterate on prompts in integrated development environments or use code-completion tools, the ability to quickly generate and update assertion criteria becomes crucial. The computational cost and time required to use large models like GPT-4 for generating assertion criteria with each prompt modification significantly slows development and increases operational costs. Evolution of LLM Evaluation Methods Traditional LLM evaluation compares outputs against human-generated benchmarks across tasks like coding and reasoning, including specialized architectures like retrieval-augmented generation and agentic systems. However, benchmarks often miss task-specific needs, such as conciseness or clarity. Even with explicit instructions in prompts, LLMs often fail to adhere to them consistently. Existing benchmarks for instruction-following evaluation are limited in scope, typically involving small sets of instructions either generated by LLMs or meticulously curated by researchers. The PROMPTEVALS dataset addresses these limitations by being five times larger than previous datasets, featuring developer-contributed real-world prompts with the corresponding assertion criteria. This advancement builds on prior work in multimodal LLM evaluation, extending evaluation to task-specific criteria. Assertions Improve LLM Reliability In instruction-following evaluations, assertion criteria are typically implemented as functions that check whether output matches specific patterns or requirements (using regular expressions). These code-based assertions often struggle with more nuanced or "fuzzy" criteria. Recent approaches have employed LLMs themselves as judges to evaluate outputs, with some developing specialized judge LLMs fine-tuned on human preference data. While LLMs as judges offer scalable evaluation, they struggle to align with human preferences across diverse tasks. Developing domain-specific assertions for areas like education or medicine is one approach, but doesn't scale easily across thousands of domains and applications. Even within domains, criteria may vary significantly. The PROMPTEVALS work complements research in efficient prompt evaluation by providing assertion criteria grounded in real-world prompts and constraints, essential for production environments. Criteria Good/Bad Explanation Response Length: The response should not list more than five highlights as re- quested. Good Mentioned in the prompt, and easy to mea- sure. Professional Tone: The response should maintain a professional and business- neutral tone throughout. Good Mentioned in the prompt template as a rule that the output should follow. No Repetition: The response should avoid repeating the same highlight or presenting the same information in different ways. Good While the criterion was not explicitly men- tioned in the prompt, it can be tied back to the prompt. Specificity: The highlights should be spe- cific and not overly broad or generic. Bad Vague, and difficult to measure. Grammar and Spelling: The response should be free from grammatical errors and spelling
This is a Plain English Papers summary of a research paper called New Dataset: LLM Guardrails Beat GPT-4o by 21%!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Why LLM Pipelines Need Better Guardrails
Large language models (LLMs) have become essential components in specialized data processing pipelines across finance, marketing, and e-commerce. However, when running in production environments, they frequently fail to follow instructions or meet developer expectations. To improve reliability, developers need assertions or guardrails for LLM outputs — but determining the right set of assertions that capture requirements for a specific task is challenging.
A new dataset called PROMPTEVALS addresses this need, providing 2087 LLM pipeline prompts with 12623 corresponding assertion criteria sourced from developers using open-source LLM pipeline tools. This collection is five times larger than previous datasets and can support further research in LLM reliability, alignment, and prompt engineering. Notably, the researchers' fine-tuned Mistral and Llama 3 models outperform GPT-4o by nearly 21% on average, while offering reduced latency and improved performance.
The dataset serves as a benchmark to evaluate how effectively LLMs can generate assertion criteria for prompts, addressing a critical gap in LLM evaluation methods.
Understanding the Context: Related Work
Prompt Engineering Challenges
Prompt engineering is crucial for steering LLMs toward following instructions for specific tasks. Techniques like chain-of-thought and few-shot prompting improve model performance, but despite these advancements, LLMs still hallucinate and make mistakes. No technique ensures consistent adherence to instructions, especially in diverse production environments.
As developers iterate on prompts in integrated development environments or use code-completion tools, the ability to quickly generate and update assertion criteria becomes crucial. The computational cost and time required to use large models like GPT-4 for generating assertion criteria with each prompt modification significantly slows development and increases operational costs.
Evolution of LLM Evaluation Methods
Traditional LLM evaluation compares outputs against human-generated benchmarks across tasks like coding and reasoning, including specialized architectures like retrieval-augmented generation and agentic systems. However, benchmarks often miss task-specific needs, such as conciseness or clarity.
Even with explicit instructions in prompts, LLMs often fail to adhere to them consistently. Existing benchmarks for instruction-following evaluation are limited in scope, typically involving small sets of instructions either generated by LLMs or meticulously curated by researchers. The PROMPTEVALS dataset addresses these limitations by being five times larger than previous datasets, featuring developer-contributed real-world prompts with the corresponding assertion criteria.
This advancement builds on prior work in multimodal LLM evaluation, extending evaluation to task-specific criteria.
Assertions Improve LLM Reliability
In instruction-following evaluations, assertion criteria are typically implemented as functions that check whether output matches specific patterns or requirements (using regular expressions). These code-based assertions often struggle with more nuanced or "fuzzy" criteria. Recent approaches have employed LLMs themselves as judges to evaluate outputs, with some developing specialized judge LLMs fine-tuned on human preference data.
While LLMs as judges offer scalable evaluation, they struggle to align with human preferences across diverse tasks. Developing domain-specific assertions for areas like education or medicine is one approach, but doesn't scale easily across thousands of domains and applications. Even within domains, criteria may vary significantly.
The PROMPTEVALS work complements research in efficient prompt evaluation by providing assertion criteria grounded in real-world prompts and constraints, essential for production environments.
| Criteria | Good/Bad | Explanation |
|---|---|---|
| Response Length: The response should not list more than five highlights as re- quested. |
Good | Mentioned in the prompt, and easy to mea- sure. |
| Professional Tone: The response should maintain a professional and business- neutral tone throughout. |
Good | Mentioned in the prompt template as a rule that the output should follow. |
| No Repetition: The response should avoid repeating the same highlight or presenting the same information in different ways. |
Good | While the criterion was not explicitly men- tioned in the prompt, it can be tied back to the prompt. |
| Specificity: The highlights should be spe- cific and not overly broad or generic. |
Bad | Vague, and difficult to measure. |
| Grammar and Spelling: The response should be free from grammatical errors and spelling mistakes. |
Bad | Not uniquely relevant to the task or prompt. |
Table 1: Examples of Good and Bad Assertion Criteria
Building the PROMPTEVALS Dataset
The Fundamentals: LLM Pipelines and Assertions
An LLM pipeline typically consists of three main components: a prompt template, input data, and the LLM itself. A prompt template includes instructions for the LLM to perform a specific task, plus placeholders for input data provided at runtime. For example, a template for summarization might look like: "Summarize the following text in three sentences: {text_to_summarize}".
An assertion in LLM pipelines is a programmatic check or evaluation criterion applied to the LLM's output. For the summarization example, an assertion might verify that the output contains exactly three sentences, as specified in the prompt.
Developers implementing LLM pipelines care about various assertions depending on their specific requirements. Based on interviews with 51 developers, a taxonomy was developed that includes six categories of output constraints: structured output, multiple choice, length constraints, semantic constraints, stylistic constraints, and hallucination prevention.
What's in the Dataset
The PROMPTEVALS dataset derives from the LangChain Prompt Hub, a publicly available collection of prompt templates shared by community developers. The researchers froze a snapshot of the prompt templates in May 2024, selecting templates that could have one or more assertion criteria (they weren't empty or trivial strings).
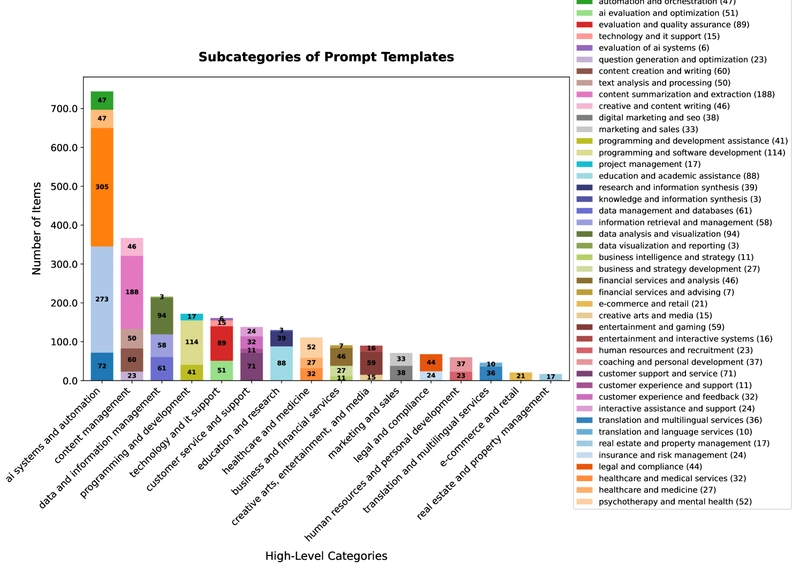
The dataset includes 2087 prompt templates spanning fields like IT and programming, finance, healthcare, and education. A hierarchical categorization process assisted by GPT-4o created a three-level categorization system. The top domains represented are general-purpose chatbots, question-answering, and workflow automation.
| Domain | Count | Percentage |
|---|---|---|
| General-purpose chatbots | 181 | $8.67 \%$ |
| Question-answering | 91 | $4.36 \%$ |
| Workflow automation | 63 | $3.02 \%$ |
| Text summarization | 57 | $2.73 \%$ |
| Education | 40 | $1.92 \%$ |
| Prompt engineering | 33 | $1.58 \%$ |
| Information retrieval | 31 | $1.49 \%$ |
| Horse racing analytics | 29 | $1.39 \%$ |
| Programming | 20 | $0.96 \%$ |
| Customer support | 18 | $0.86 \%$ |
| Database querying | 18 | $0.86 \%$ |
| Journalism | 17 | $0.81 \%$ |
| Task automation | 15 | $0.72 \%$ |
Table 2: Distribution of domains in the PROMPTEVALS dataset. The top three domains are general-purpose chatbots, question-answering, and workflow automation.
This diverse collection of prompt templates provides an excellent foundation for large-scale prompt exploration across various domains.
Figure 1: Distribution of Domains and Subdomains of Tasks Represented in PROMPTEVALS showing the hierarchical organization of prompt templates across different fields.
Creating High-Quality Assertion Criteria
For each prompt template, the researchers generated a set of ground truth criteria following a three-step process:
Generate Initial Criteria: GPT-4o generated an initial list of assertion criteria for each prompt template, guided by the taxonomy of LLM output constraints. Each criterion was tagged with its corresponding constraint type.
Add Missing Criteria: Two authors manually reviewed 200 criteria, finding an average of 1.35 missing criteria per prompt. They achieved a Cohen's Kappa score of 0.91, indicating strong inter-reviewer agreement. GPT-4o then re-examined prompt templates to identify explicitly stated criteria absent from its initial analysis.
Refine Criteria: In the final step, GPT-4o refined the list by removing any criteria that were incorrect, redundant, irrelevant, or difficult to validate.
This process resulted in high agreement between the LLM-generated outputs and human evaluators, with less than 0.02 criteria added and less than 0.2 criteria removed per list on average during final verification.
Benchmarking with PROMPTEVALS
The dataset was split into three parts: 60% (1252 prompts) for training, 20% (418 prompts) for validation, and 20% (419 prompts) for testing. The PROMPTEVALS benchmark evaluates an LLM's effectiveness at generating accurate assertion criteria given a prompt template.
How to Measure Success: Benchmark Metrics
The primary metric is Semantic F1, which addresses a key challenge: semantically equivalent assertions can be expressed in various ways. For example, "The response should be concise" and "The output should be brief" convey essentially the same constraint using different words.
To compute Semantic F1, each criterion (both predicted and ground truth) is transformed into vector representations using OpenAI's text-embedding-3-large model. Then recall and precision scores are calculated based on the cosine similarity between these embedding vectors.
The recall score quantifies how well the predicted criteria cover the semantic content of the ground truth criteria, while the precision score measures how accurately the predicted criteria align with ground truth. These scores are combined into the F1 score.
A secondary metric is the number of criteria generated per prompt template, compared against ground truth values.

Figure 2: Examples of criteria pairs with varying semantic similarity scores. High similarity scores indicate constraints explicitly stated or logically derived from the prompt, while low scores often represent vague or generic constraints.
This semantic evaluation approach builds on previous work in guardrails for custom LLM pipelines.
Evaluating LLMs for Assertion Generation
Testing Approach: Models and Methodology
The researchers established baselines using three models: GPT-4o, Llama-3-8b, and Mistral-7b. They selected the Llama and Mistral models for their relatively compact size (8 billion and 7.3 billion parameters respectively), which leads to faster inference times.
Initial results showed suboptimal performance from baseline models, so they fine-tuned the same Mistral and Llama architectures on a dataset comprising LLM pipeline prompts and ground truth criteria derived from the PROMPTEVALS training split.
The fine-tuning process used:
- Sequence length of 4096
- 4 epochs with batch size of 8
- AdamW optimizer with 0.0001 learning rate
- Cosine learning rate scheduler
- Low-Rank Adaptation (LoRA) with rank of 16
Training was completed in under one hour with two 80GB A100 GPUs, with no hyperparameter search.
Numbers Don't Lie: Performance Results
Fine-tuning on PROMPTEVALS resulted in substantial improvements in the quality of generated assertion criteria. The fine-tuned Mistral model achieved an average semantic F1 score of 0.8199, which is 20.43% higher than GPT-4o's 68.08%, and 100.32% higher than its base model. Similarly, the fine-tuned Llama3 model achieved a semantic F1 score of 0.8240, outperforming GPT-4o by 21.03% and its base model by 128.42%.
| Base Mistral | Mistral (FT) | Base Llama | Llama (FT) | GPT-4o | |
|---|---|---|---|---|---|
| p25 | 0.3608 | 0.7919 | 0.3211 | 0.7922 | 0.6296 |
| p50 | 0.4100 | 0.8231 | 0.3577 | 0.8233 | 0.6830 |
| Mean | 0.4093 | 0.8199 | 0.3607 | 0.8240 | 0.6808 |
| p75 | 0.4561 | 0.8553 | 0.3978 | 0.8554 | 0.7351 |
Table 3: Semantic F1 scores for generated assertion criteria. Percentiles and mean values are shown for base models, fine-tuned (FT) versions, and GPT-4o. Bold indicates highest scores.
Analyzing the Results: Qualitative Improvements
Analysis of base and fine-tuned model outputs for 25 randomly selected prompt templates showed significant improvements in five main categories:
Format Adherence: Base models struggled with formatting consistency, with Llama3 showing errors in nearly all cases. Fine-tuned models maintained consistent formatting.
Relevance: Base models included extraneous content or unnecessary commentary. Fine-tuned models maintained strict focus on requested criteria.
Conciseness: Base models significantly over-generated assertions, with redundant or overlapping criteria. Fine-tuned models generated more distinct, non-overlapping assertions.
Completeness: Base models often produced incomplete outputs due to token limits. Fine-tuning effectively addressed these completion issues.
Output Length: Ground truth contained about 6 assertions per prompt template. Base models exceeded this significantly (Mistral averaged 14.5 assertions, Llama 28.24), while fine-tuned models produced outputs more aligned with ground truth.
| Average | Median | p75 | p90 | |
|---|---|---|---|---|
| Base Mistral | 14.5012 | 14 | 18.5 | 23 |
| Mistral (FT) | 6.28640 | 5 | 8 | 10 |
| Base Llama | 28.2458 | 26 | 33.5 | 46 |
| Llama (FT) | 5.47255 | 5 | 6 | 9 |
| GPT-4o | 7.59189 | 6 | 10 | 14.2 |
| Ground Truth | 5.98568 | 5 | 7 | 10 |
Table 4: Number of Criteria Generated by Models. Metrics show average, median, and percentile values. Bold indicates closest to ground truth.
Additionally, fine-tuned models demonstrated improved latency compared to GPT-4o:
| Mistral (FT) | Llama (FT) | GPT-4o | |
|---|---|---|---|
| p25 | 1.8717 | 2.3962 | 6.5596 |
| p50 | 2.3106 | 3.0748 | 8.2542 |
| Mean | 2.5915 | 3.6057 | 8.7041 |
| p75 | 2.9839 | 4.2716 | 10.1905 |
Table 5: Latency for criteria generation in seconds. The fine-tuned Mistral model had the lowest runtime for all metrics.
Why This Matters: Implications for Production
The smaller, fine-tuned models achieve assertions comparable to the three-phase GPT-4o process while significantly outperforming single-phase GPT-4o. This demonstrates that carefully curated datasets and targeted fine-tuning can enable smaller models to match or exceed larger models in specific tasks.
It also underscores the importance of multi-step refinement when using state-of-the-art general-purpose LLMs for generating assertion criteria, as evidenced by the low single-step GPT-4o performance. While effective, this refinement process can lead to increased latency in non-interactive settings.
The ability to generate high-quality assertion criteria quickly and cost-effectively has significant implications for LLM pipeline development:
- Enables more frequent iterations
- Supports faster debugging
- Creates more robust quality assurance processes
- Eliminates prohibitive costs or delays
This is particularly valuable as prompts become longer and more complex, making the use of GPT-4o to generate assertions for every iteration increasingly impractical.
The researchers are integrating these fine-tuned assertion generation models into LLM pipeline development tools, focusing on evaluation and monitoring capabilities. This will allow developers to automatically generate task-specific assertion criteria for any given prompt or pipeline and continuously monitor output quality in production environments.
The Road Ahead: Conclusions and Applications
The PROMPTEVALS dataset comprises over 2,000 human-contributed prompt templates and 12,000 assertion criteria, making it more than five times larger than previous prompt collections. This diverse dataset represents a significant contribution to LLM pipeline development, offering a robust tool for evaluating and improving task-specific output constraints.
Using PROMPTEVALS, the researchers benchmarked several models including GPT-4o and additionally fine-tuned open-source models for assertion generation. Their experiments demonstrate PROMPTEVALS' utility in assessing and comparing performance across different approaches.
By making PROMPTEVALS and fine-tuned models publicly available, the goal is to encourage development of more reliable and task-specific LLM applications across various domains.
Understanding the Limitations
The benchmark scores rely on OpenAI's text-embedding-3-large model, introducing a risk of inconsistency in results over time due to potential model updates. Establishing a versioning system or exploring more stable embedding methods could mitigate this issue.
Currently, the benchmark is restricted to text prompts, excluding other modalities like images and audio. Expanding the dataset to incorporate multi-modal inputs would increase its applicability and better reflect the diverse range of real-world LLM tasks.
Finally, while the criteria are grounded in a taxonomy derived from developer preferences, they are ultimately generated by an LLM. This approach may not capture the full nuance of developer intentions for every specific use case. Ideally, criteria would be developed through direct collaboration with developers for each prompt template.
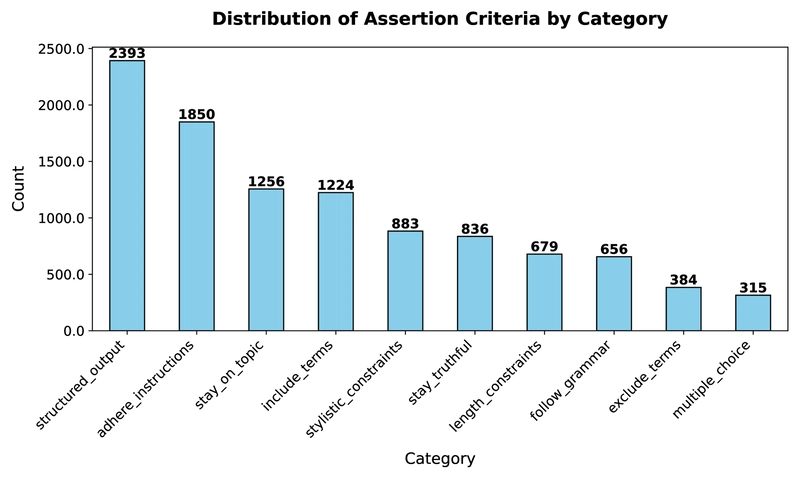
Figure 3: Distribution of Ground Truth Criteria by Type showing the prevalence of different constraint categories in the dataset.
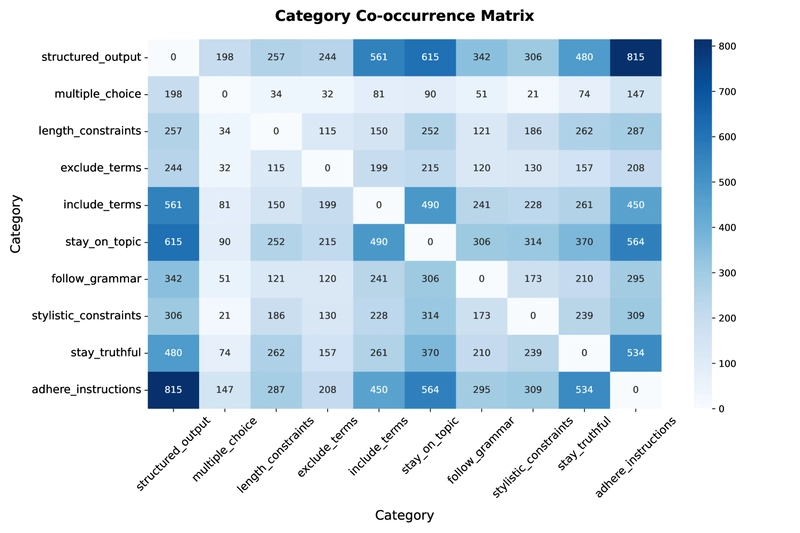
Figure 4: Constraint Type Co-Occurrence Matrix showing how different types of constraints frequently appear together in prompt templates.