












































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)























































































































































![API design for precomputation cache [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)























































































































_NicoElNino_Alamy.png?width=1280&auto=webp&quality=80&disable=upscale#)
_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




























































































![Apple appealing $570M EU fine, White House says it won’t be tolerated [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/Apple-says-570M-EU-fine-is-unfair-White-House-says-it-wont-be-tolerated.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)
















![At Least Three iPhone 17 Models to Feature 12GB RAM [Kuo]](https://www.iclarified.com/images/news/97122/97122/97122-640.jpg)

![Dummy Models Showcase 'Unbelievably' Thin iPhone 17 Air Design [Images]](https://www.iclarified.com/images/news/97114/97114/97114-640.jpg)

























































































































System Design Interview: Replacing Redis with Own Application in Spring Boot
It was a Wednesday afternoon when I stepped into the virtual meeting room for my senior Java backend developer interview. After the usual introductions and technical questions, the lead architect leaned forward with a challenging gleam in her eye. “Let’s discuss a system design problem,” she said. “Imagine we’re looking to replace our Redis caching layer with a solution built directly into our Spring Boot microservices. How would you approach this?” I took a moment to gather my thoughts, recognizing this as an opportunity to demonstrate my architectural thinking. “Before diving into implementation details,” I started, “could you tell me more about the current microservices ecosystem and how Redis is being used?” “Good question,” she replied. “We have about a dozen microservices, each responsible for specific business domains. Redis currently acts as a centralized caching layer accessed by all services for performance optimization and to reduce database load. We’re particularly interested in exploring alternatives that might reduce operational complexity.” I nodded and began outlining my solution. Understanding the Microservice Caching Requirements “First, let’s identify what we need from our replacement caching solution in a microservices context,” I said. Distributed consistency — Ensuring cache coherence across service instances Independent scaling — Each service managing its own cache needs Resilience — Preventing cascading failures if caching issues arise Performance — Maintaining similar or better performance than Redis Observability — Monitoring cache effectiveness across services The Architecture Approach “I propose a two-tiered architecture,” I continued. “Each microservice will maintain its own local cache, but we’ll implement a synchronization mechanism to maintain consistency where needed.” I sketched out a diagram showing: Individual Spring Boot microservices with embedded caching components An event-driven synchronization layer for cross-service cache invalidation Optional persistence mechanisms per service Core Implementation “For the foundation, we’ll use Spring’s cache abstraction,” I explained. “This gives us flexibility to implement different caching strategies per microservice based on their specific needs.” @Configuration @EnableCaching public class CachingConfig { @Bean public CacheManager cacheManager() { CaffeineCacheManager cacheManager = new CaffeineCacheManager(); cacheManager.setCaffeine(Caffeine.newBuilder() .expireAfterWrite(Duration.ofMinutes(30)) .maximumSize(10000) .recordStats()); return cacheManager; } @Bean public CacheMetrics cacheMetrics(CacheManager cacheManager) { return new CacheMetrics(cacheManager, meterRegistry); } “I’m using Caffeine as the local cache provider since it offers excellent performance characteristics similar to Redis,” I explained. “Each microservice can configure its own cache policies based on its specific access patterns and data freshness requirements.” Distributed Cache Invalidation “The key challenge in a microservices architecture is maintaining cache consistency,” I continued. “When one service updates data, other services’ caches might become stale.” “For this, I recommend an event-driven approach using a lightweight message broker like RabbitMQ or Kafka, which you likely already have in your microservices ecosystem.” @Service public class CacheInvalidationService { @Autowired private CacheManager cacheManager; @Autowired private EventPublisher eventPublisher; public void invalidateCache(String cacheName, String key) { // Local invalidation Cache cache = cacheManager.getCache(cacheName); if (cache != null) { cache.evict(key); } // Publish invalidation event for other services eventPublisher.publish(new CacheInvalidationEvent(cacheName, key)); } @EventListener public void handleInvalidationEvent(CacheInvalidationEvent event) { Cache cache = cacheManager.getCache(event.getCacheName()); if (cache != null) { cache.evict(event.getKey()); } } } “This approach allows for targeted cache invalidation across services. Only the specific keys that have changed are invalidated, rather than flushing entire caches.” Service-Specific Caching Strategies “A key advantage of moving caching into each microservice is the ability to tailor caching strategies to each service’s needs,” I explained. “For example, a product catalog service might cache items with long TTLs, while a pricing service might use shorter TTLs or implement cache-aside with database triggers for invalidation. @Service public class ProductCatalogService { @Cacheable(value = "products", key = "#productId", unless = "#result == null") public Product getProdu
It was a Wednesday afternoon when I stepped into the virtual meeting room for my senior Java backend developer interview. After the usual introductions and technical questions, the lead architect leaned forward with a challenging gleam in her eye.
“Let’s discuss a system design problem,” she said. “Imagine we’re looking to replace our Redis caching layer with a solution built directly into our Spring Boot microservices. How would you approach this?”
I took a moment to gather my thoughts, recognizing this as an opportunity to demonstrate my architectural thinking.
“Before diving into implementation details,” I started, “could you tell me more about the current microservices ecosystem and how Redis is being used?”
“Good question,” she replied.
“We have about a dozen microservices, each responsible for specific business domains. Redis currently acts as a centralized caching layer accessed by all services for performance optimization and to reduce database load. We’re particularly interested in exploring alternatives that might reduce operational complexity.”
I nodded and began outlining my solution.
Understanding the Microservice Caching Requirements
“First, let’s identify what we need from our replacement caching solution in a microservices context,” I said.
- Distributed consistency — Ensuring cache coherence across service instances
- Independent scaling — Each service managing its own cache needs
- Resilience — Preventing cascading failures if caching issues arise
- Performance — Maintaining similar or better performance than Redis
- Observability — Monitoring cache effectiveness across services
The Architecture Approach
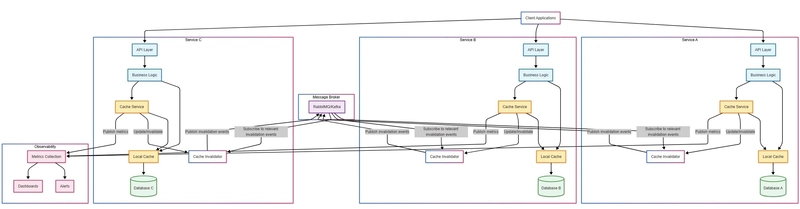
“I propose a two-tiered architecture,” I continued. “Each microservice will maintain its own local cache, but we’ll implement a synchronization mechanism to maintain consistency where needed.”
I sketched out a diagram showing:
- Individual Spring Boot microservices with embedded caching components
- An event-driven synchronization layer for cross-service cache invalidation
- Optional persistence mechanisms per service
Core Implementation
“For the foundation, we’ll use Spring’s cache abstraction,” I explained. “This gives us flexibility to implement different caching strategies per microservice based on their specific needs.”
@Configuration
@EnableCaching
public class CachingConfig {
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
cacheManager.setCaffeine(Caffeine.newBuilder()
.expireAfterWrite(Duration.ofMinutes(30))
.maximumSize(10000)
.recordStats());
return cacheManager;
}
@Bean
public CacheMetrics cacheMetrics(CacheManager cacheManager) {
return new CacheMetrics(cacheManager, meterRegistry);
}
“I’m using Caffeine as the local cache provider since it offers excellent performance characteristics similar to Redis,” I explained. “Each microservice can configure its own cache policies based on its specific access patterns and data freshness requirements.”
Distributed Cache Invalidation
“The key challenge in a microservices architecture is maintaining cache consistency,” I continued. “When one service updates data, other services’ caches might become stale.”
“For this, I recommend an event-driven approach using a lightweight message broker like RabbitMQ or Kafka, which you likely already have in your microservices ecosystem.”
@Service
public class CacheInvalidationService {
@Autowired
private CacheManager cacheManager;
@Autowired
private EventPublisher eventPublisher;
public void invalidateCache(String cacheName, String key) {
// Local invalidation
Cache cache = cacheManager.getCache(cacheName);
if (cache != null) {
cache.evict(key);
}
// Publish invalidation event for other services
eventPublisher.publish(new CacheInvalidationEvent(cacheName, key));
}
@EventListener
public void handleInvalidationEvent(CacheInvalidationEvent event) {
Cache cache = cacheManager.getCache(event.getCacheName());
if (cache != null) {
cache.evict(event.getKey());
}
}
}
“This approach allows for targeted cache invalidation across services. Only the specific keys that have changed are invalidated, rather than flushing entire caches.”
Service-Specific Caching Strategies
“A key advantage of moving caching into each microservice is the ability to tailor caching strategies to each service’s needs,” I explained.
“For example, a product catalog service might cache items with long TTLs, while a pricing service might use shorter TTLs or implement cache-aside with database triggers for invalidation.
@Service
public class ProductCatalogService {
@Cacheable(value = "products", key = "#productId", unless = "#result == null")
public Product getProduct(String productId) {
return productRepository.findById(productId);
}
@CachePut(value = "products", key = "#product.id")
public Product updateProduct(Product product) {
Product updated = productRepository.save(product);
// Notify other services about this update
cacheInvalidationService.notifyUpdate("products", product.getId());
return updated;
}
}
Near Cache Pattern Implementation
“For frequently accessed data that’s shared across services, I’d implement a near cache pattern,” I suggested.
“Each service maintains its local cache, but also subscribes to a topic for updates from authoritative services. This gives us the best of both worlds: local cache speed with reasonable consistency.”
@Service
public class NearCacheService {
@Autowired
private CacheManager cacheManager;
@Autowired
private MessageListener messageListener;
@PostConstruct
public void init() {
// Subscribe to cache update events for domains this service cares about
messageListener.subscribe("cache.updates.products", this::handleProductUpdate);
}
private void handleProductUpdate(CacheUpdateEvent event) {
// Update local cache with fresh data
Cache cache = cacheManager.getCache("products");
if (cache != null) {
cache.put(event.getKey(), event.getValue());
}
}
}
Resilience Patterns
“In a distributed system, we need to ensure cache failures don’t impact service availability,” I noted. “I’d implement circuit breakers around cache operations to gracefully degrade to direct database access if needed.”
@Service
public class ResilientCacheService {
@Autowired
private CacheManager cacheManager;
@Autowired
private CircuitBreakerFactory circuitBreakerFactory;
public Object getWithFallback(String cacheName, String key, Supplier<Object> dataLoader) {
CircuitBreaker circuitBreaker = circuitBreakerFactory.create("cache");
return circuitBreaker.run(() -> {
Cache cache = cacheManager.getCache(cacheName);
Object value = cache.get(key);
if (value != null) {
return value;
}
// Cache miss or error, load from source
Object freshData = dataLoader.get();
if (freshData != null) {
cache.put(key, freshData);
}
return freshData;
}, throwable -> {
// Circuit open or error, direct fallback to data source
return dataLoader.get();
});
}
}
Monitoring and Observability
“For monitoring, we’ll implement comprehensive metrics collection,” I continued. “This is especially important in a distributed caching system to identify inefficiencies or inconsistencies.”
@Component
public class CacheMetrics {
private final CacheManager cacheManager;
private final MeterRegistry meterRegistry;
public CacheMetrics(CacheManager cacheManager, MeterRegistry meterRegistry) {
this.cacheManager = cacheManager;
this.meterRegistry = meterRegistry;
registerMetrics();
}
private void registerMetrics() {
cacheManager.getCacheNames().forEach(cacheName -> {
Cache cache = cacheManager.getCache(cacheName);
if (cache instanceof CaffeineCache) {
com.github.benmanes.caffeine.cache.Cache nativeCache =
((CaffeineCache) cache).getNativeCache();
// Register various metrics for this cache
Gauge.builder("cache.size", nativeCache, c -> c.estimatedSize())
.tag("cache", cacheName)
.register(meterRegistry);
// Add more metrics for hits, misses, etc.
}
});
}
}
Migration Strategy
“Replacing Redis across a microservices ecosystem requires careful planning,” I said. “I recommend a phased approach:
- Implement the new caching solution alongside Redis in non-critical services first
- Use feature flags to control traffic between the two caching systems
- Monitor performance, errors, and consistency issues closely
- Gradually migrate services from least to most critical
- Maintain Redis as a fallback until confidence is high in the new solution
Conclusion
This approach offers several advantages in a microservices context,
I summarized:
- Reduced operational complexity — No separate Redis cluster to maintain
- Service autonomy — Each service controls its own caching behavior
- Improved resilience — No single point of failure for the entire caching system
- Tailored performance — Cache configurations aligned with specific service needs
- Simplified deployment — No external cache dependencies for development or testing
The interviewer nodded thoughtfully.
What about the drawbacks? When would you recommend keeping Redis instead?
“Great question,” I replied. “I’d recommend keeping Redis if:
- Your services need advanced data structures like sorted sets or geospatial indexes
- The volume of cached data is extremely large and would strain service memory
- You need centralized rate limiting or distributed locking features
- Your architecture requires centralized caching policies for compliance reasons
- The overhead of implementing and maintaining cache synchronization exceeds Redis operational costs”
Okay, … part of the interview, wait for good results from me.
original my article from Medium


