










































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)



































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.jpg?#)

































_ArtemisDiana_Alamy.jpg?#)


 (1).webp?#)








































































-xl.jpg)












![Yes, the Gemini icon is now bigger and brighter on Android [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/02/Gemini-on-Galaxy-S25.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Rushes Five Planes of iPhones to US Ahead of New Tariffs [Report]](https://www.iclarified.com/images/news/96967/96967/96967-640.jpg)
![Apple Vision Pro 2 Allegedly in Production Ahead of 2025 Launch [Rumor]](https://www.iclarified.com/images/news/96965/96965/96965-640.jpg)
























































































































SlimUUID: The Compact, Memory-Efficient Alternative to Standard UUIDs
Table of contents : Introduction Problems Faced with UUID SlimUUID 3.1 Phase 1 3.2 Phase 2 3.3 Final Build Testing Miscellaneous 1. Introduction You guys have lot to read so , I shall get to the point directly. A few days back I was working on a Database Model which involved below defination type Mcq struct { gorm.Model ID string `gorm:"type:uuid,primaryKey"` Answer string `gorm:"not null"` StudentID string `gorm:"type:uuid,index:idx,composite"` ContestID string `gorm:"type:uuid,index:idx,composite" Student Student Contest Contest } As you can see there are ID , ContestID , StudentID 3 UUIDs are present . and these all are indexed . ID as primary Key (btree default ) ContestID , StudentID (composite can't be hashed in hash table !!) Now while calculating and maintaining my DB's space I encountered a sad :(((( , no worse :(((( , actually evil fact that out of my table's total . single entry : ( 36 + 36 + 36 + 10 : base) + (64 + 64 + 64 : index) : 310 most of this is index index calculation : 36 (string) + 8 (pointer) + 16 (node) + 4 (pad) Isnt all this making my DB slow ? Isnt is taking lot of space ? Why do i need time stamped ? Can't I do something ? All of these questions , I answered for myself , and some of you who would have encountered something similar . 2. First Lets see what is the problem that i faced with UUID We will cover it in pace and in short , if you wanna read more about code and functions go to : Github Unique Identifier , Made by google Have different versions v3,v4,v6 for various reasons , like V4 for random generation for a little faster experience , least time consuming one . But do not have time stamped generation . Have 32 characters , 4 hyphens => total 36 length string Problems I encountered : Takes a lot of time if compositely indexed with other attribute as already large string contributes to more and more space for indexing . Do not accept hash types like type-pattern ops , cids , any available in pg admin . 3. SlimUUID So here is the solution in two phases that i thought Phase1 : Integer hashes , query is fastest just make Time.Now() timestamp for milliseconds or nanoseconds till now simple , fast retrieval . Problem in this approach : Clock Synchronization in Different systems Sql generates data in microseconds , so even if we consodered microseconds => 13-14 digits and increasing digits every microsecond , loose control of fix size primary key (for hashing) Phase2 : So why not take any MD5 hash or something that can help , unique always (Yes!!!!!!!!) Right ??? Problem : Not at all MD5 hashes and most of the cryptographic hashes are even larger than 32 characters so it would be needed to truncated leading to exponentially high collision risk . Finalle : Then I saw the created at timestamp with my id in DB . Then I came with the ID why not just make something with mixing phase1 , and phase2 : Then I thought of a solution : Timetamp + MD5 hash This is same the way how uuids by google are made 32 character have blocks of different time stamps and needs . Problems : timestamp for 30 years or more already consume 13-15 digits . MD5 hashes takes time to build and also truncating it too . Then at that moment slimUUID was made as I clicked two things for corresponding problem , each character in timestamp was taking '0-9' chracters potentially it could hold more ..... Huh... _Eureka !!! Eureka !!!!! I found the answer So, I changed it and created my own format (as shown in the code window). This new format directly reduced the 13 characters to 7-8 (depending on the precision needed). I had plenty of space left, so I generated another hash using MD5 from the remaining 12 characters. However, MD5 was cryptographic, but after reading about it, I came across Murmur3 which is fast but not cryptographically secure backward (and I didn't need that security either Heheheheeh). So murmur3 is used to generate has with two parts , which are then combined with conversion into binary encoding , after these two timestamp and murmur3hash has been a combined a 19 character string is formed . This hash can not clash after a millisecond has passed . But in micro , nano second time line it can be clashed but that is mitigated byr Random hash generated by Murmur3's truncated part. This brought down my generation time from about 50 microseconds to 20 microseconds. Then, with the increasing number of systems, what to do? So, I added a character for each machine, which now can handle up to 62 concurrent machines uniquely . Character Set: Base-62: 0-9 (10 chars) + a-z (26 chars) + A-Z (26 chars) = 62 total. Structure: Year (1 char, 62 possible values, starting from 2025). Month (1 char, up to 12 possible values). Day (1 char, up to 31 possible values). Hour (1 char, up to 24 possible values). Minute (1 char, up to

Table of contents :
- Introduction
- Problems Faced with UUID
- SlimUUID 3.1 Phase 1 3.2 Phase 2 3.3 Final Build
- Testing
- Miscellaneous
1. Introduction
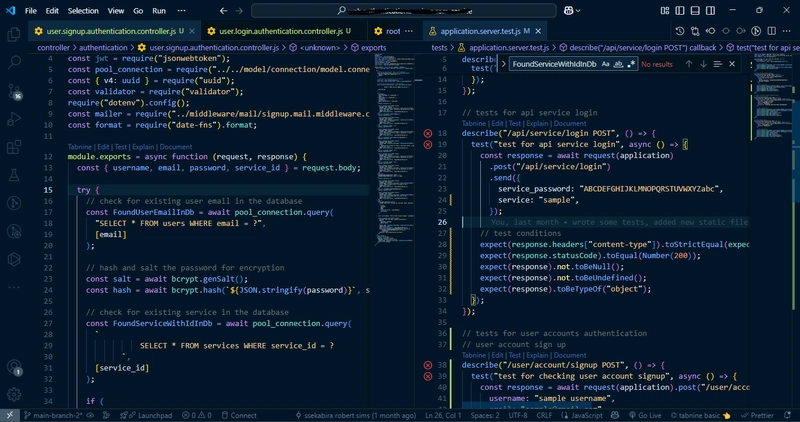
You guys have lot to read so , I shall get to the point directly. A few days back I was working on a Database Model which involved below defination
type Mcq struct {
gorm.Model
ID string `gorm:"type:uuid,primaryKey"`
Answer string `gorm:"not null"`
StudentID string `gorm:"type:uuid,index:idx,composite"`
ContestID string `gorm:"type:uuid,index:idx,composite"
Student Student
Contest Contest
}
As you can see there are ID , ContestID , StudentID 3 UUIDs are present . and these all are indexed .
- ID as primary Key (btree default )
- ContestID , StudentID (composite can't be hashed in hash table !!)
Now while calculating and maintaining my DB's space I encountered a sad :(((( , no worse :(((( , actually evil fact that out of my table's total .
single entry : ( 36 + 36 + 36 + 10 : base) + (64 + 64 + 64 : index)
: 310 most of this is index
index calculation : 36 (string) + 8 (pointer) + 16 (node) + 4 (pad)
- Isnt all this making my DB slow ?
- Isnt is taking lot of space ?
- Why do i need time stamped ?
- Can't I do something ?
All of these questions , I answered for myself , and some of you who would have encountered something similar .
2. First Lets see what is the problem that i faced with UUID
We will cover it in pace and in short , if you wanna read more about code and functions go to : Github
- Unique Identifier , Made by google
- Have different versions v3,v4,v6 for various reasons , like V4 for random generation for a little faster experience , least time consuming one . But do not have time stamped generation .
- Have 32 characters , 4 hyphens => total 36 length string
Problems I encountered :
- Takes a lot of time if compositely indexed with other attribute as already large string contributes to more and more space for indexing .
- Do not accept hash types like type-pattern ops , cids , any available in pg admin .
3. SlimUUID
So here is the solution in two phases that i thought
Phase1 :
Integer hashes , query is fastest just make Time.Now() timestamp for milliseconds or nanoseconds till now simple , fast retrieval .
Problem in this approach :
- Clock Synchronization in Different systems
- Sql generates data in microseconds , so even if we consodered microseconds => 13-14 digits and increasing digits every microsecond , loose control of fix size primary key (for hashing)
Phase2 :
So why not take any MD5 hash or something that can help , unique always (Yes!!!!!!!!) Right ???
Problem :
- Not at all MD5 hashes and most of the cryptographic hashes are even larger than 32 characters so it would be needed to truncated leading to exponentially high collision risk .
Finalle :
Then I saw the created at timestamp with my id in DB . Then I came with the ID why not just make something with mixing phase1 , and phase2 :
Then I thought of a solution :
Timetamp + MD5 hash
This is same the way how uuids by google are made 32 character have blocks of different time stamps and needs .
Problems :
- timestamp for 30 years or more already consume 13-15 digits .
- MD5 hashes takes time to build and also truncating it too .
Then at that moment slimUUID was made as I clicked two things for corresponding problem , each character in timestamp was taking '0-9' chracters potentially it could hold more ..... Huh...
_Eureka !!! Eureka !!!!! I found the answer
So, I changed it and created my own format (as shown in the code window). This new format directly reduced the 13 characters to 7-8 (depending on the precision needed). I had plenty of space left, so I generated another hash using MD5 from the remaining 12 characters. However, MD5 was cryptographic, but after reading about it, I came across Murmur3 which is fast but not cryptographically secure backward (and I didn't need that security either Heheheheeh).
So murmur3 is used to generate has with two parts , which are then combined with conversion into binary encoding , after these two timestamp and murmur3hash has been a combined a 19 character string is formed . This hash can not clash after a millisecond has passed . But in micro , nano second time line it can be clashed but that is mitigated byr Random hash generated by Murmur3's truncated part.
This brought down my generation time from about 50 microseconds to 20 microseconds. Then, with the increasing number of systems, what to do? So, I added a character for each machine, which now can handle up to 62 concurrent machines uniquely .
Character Set:
Base-62: 0-9 (10 chars) + a-z (26 chars) + A-Z (26 chars) = 62 total.
Structure:
Year (1 char, 62 possible values, starting from 2025).
Month (1 char, up to 12 possible values).
Day (1 char, up to 31 possible values).
Hour (1 char, up to 24 possible values).
Minute (1 char, up to 60 possible values).
Millisecond (2 chars, derived from current second + millisecond).
Optional Machine ID (1 char, up to 60 devices).
Murmur3 Hash (12 chars).
Total Characters:
19 characters (without machine ID).
20 characters (with optional machine ID).
For whole code and testing u can use
import "github.com/theMitcondria/slimuuid"
func main(){
id := slimuuid.Generate()
// output example : 2mV5F7b6y0fHXJK9tz
}
// or visit github for the code base
4. Testing
I started writing the code , began testing on a code base to see how much better it was performing. I had a simple setup where there was just one ID and one foreign key, along with other attributes , without this adjustment of my hashed key the statistics were ,
70k entries took 2-3ms
Fast Forward to 7lakh entries (10 times ) with hashed 19 character slimuuid :

)
Last but not at all the Least : Memory-Efficiency
type Mcq struct {
gorm.Model
ID string `gorm:"type:uuid,primaryKey"`
Answer string `gorm:"not null"`
StudentID string `gorm:"type:uuid,index:idx,composite"`
ContestID string `gorm:"type:uuid,index:idx,composite"
Student Student
Contest Contest
}
// same model which neede 310 bytes now needs:
=> (19 + 19 + 19 + 10 Base) + (39 + 39 + 39 ) : 184
// index size
=> 19 + 8 (pointer) + 4(collision mitigation ) + 8 (hash value): 39
// Memory Efficiency
=> 184/310 : 60%
Collison Probabilty
Then for surety I checked on various models for collision probabilty with birtthday formula :
Results :

Huhhh !!! Stillllll , I thought I need an exact number ....

5. Miscellaneous Benefits
- Was able to implement hash with slimUUID with pattern-ops which UUID with postgres didn't allow .
- After changing to hashed , a sudden performance increase of 15% on average was seen in response time when calculated for searching.
Do check out : Github SlimUUID
Any suggestions or pull requests are appreciated .
This is my first blog and I am an amateur in DBs , and optimization so if any of this can be rewritten or changes needs to be done i will be highly obliged to do so .
Thanks a lot for giving it a read



