











































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)





























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)









































































































.png?#)




.jpg?#)































_Christophe_Coat_Alamy.jpg?#)































































































![Rapidus in Talks With Apple as It Accelerates Toward 2nm Chip Production [Report]](https://www.iclarified.com/images/news/96937/96937/96937-640.jpg)

































































































































Running Ollama on Docker: A Quick Guide
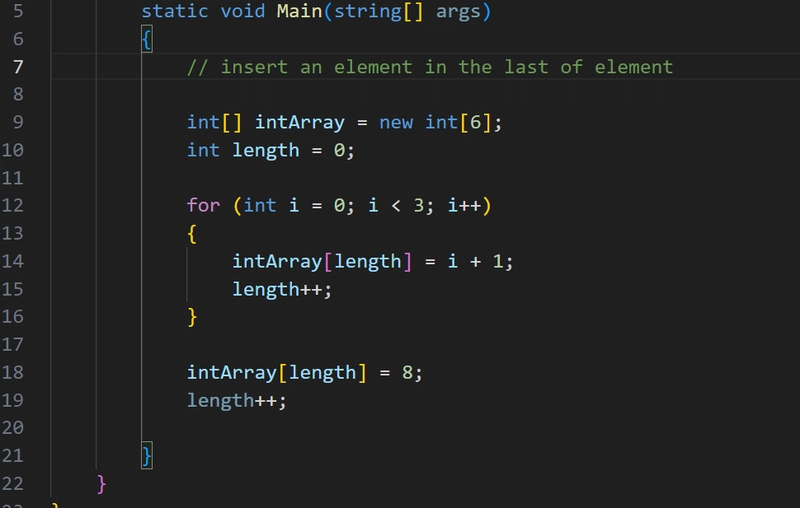
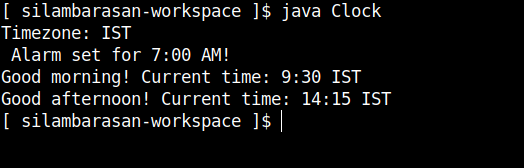
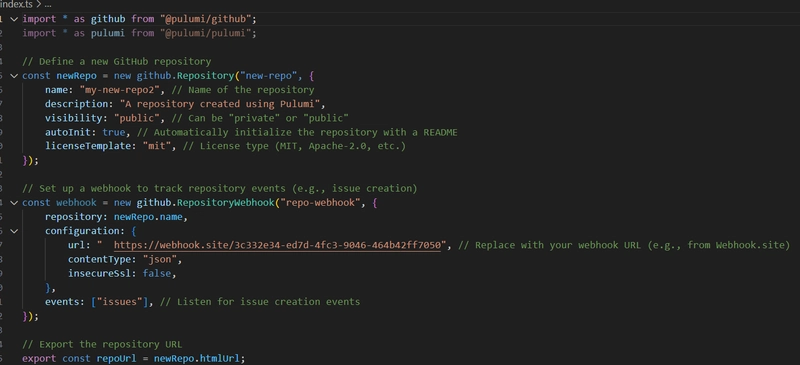
Hi it's me again! Over the past few days, I've been testing multiples ways to work with LLMs locally, and so far, Ollama was the best tool (ignoring UI and other QoL aspects) for setting up a fast environment to test code and features. I've tried GPT4ALL and other tools before, but they seem overly bloated when the goal is simply to set up a running model to connect with a LangChain API (on Windows with WSL). Ollama provides an extremely straightforward experience. Because of this, today I decided to install and use it via Docker containers — and it's surprisingly easy and powerful.. With just five commands, we can set up the environment. Let's take a look. Step 1 - Pull the latest Ollama Docker image docker pull ollama/ollama If you want to download an older version, you can specify the corresponding tag after the container name. By default, the :latest tag is downloaded. You can check a list of available Ollama tags here. Step 2 - Create a Docker network Since we'll typically use and connect multiple containers, we need to specify a shared communication channel. To achieve this, it's a good practice create a Docker network. docker network create You can check a list of created Docker networks by running the following command: docker network list Step 3 - Run the Ollama container In this tutorial, we're going to run Ollama with CPU only. If you need to use GPU, the official documentation provide a step-by-step guide. The command to run the container is also listed in the documentation, but we need to specify which network it should connect to, so we must add the --network parameter. docker run -d --netowk -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama Step 4 - Run commands inside the Ollama container To download Ollama models, we need to run ollama pull command. To do this, we simply execute the command below, which enables the execution inside the container by enabling the interative mode (-it parameter). Then, we run ollama pull to download the llama3.2:latest (3B), quantized model: docker exec -it ollama ollama pull llama3.2 Visit the Ollama website to check the list of available models. Now, wait for the download to finish. You'll get this: Step 5 - Check the downloaded models To list the locally available models, just run: ollama list You should get this output: So you're done! Now you have Ollama running (using only the CPU), with the llama3.2:latest model available locally. To run it with a GPU, check the documentation link in Step 3. I'll share more short notes on working with Ollama and LangChain in the next few days. Stay tuned!
Hi it's me again! Over the past few days, I've been testing multiples ways to work with LLMs locally, and so far, Ollama was the best tool (ignoring UI and other QoL aspects) for setting up a fast environment to test code and features.
I've tried GPT4ALL and other tools before, but they seem overly bloated when the goal is simply to set up a running model to connect with a LangChain API (on Windows with WSL).
Ollama provides an extremely straightforward experience. Because of this, today I decided to install and use it via Docker containers — and it's surprisingly easy and powerful..
With just five commands, we can set up the environment. Let's take a look.
Step 1 - Pull the latest Ollama Docker image
docker pull ollama/ollama
If you want to download an older version, you can specify the corresponding tag after the container name. By default, the :latest tag is downloaded. You can check a list of available Ollama tags here.
Step 2 - Create a Docker network
Since we'll typically use and connect multiple containers, we need to specify a shared communication channel. To achieve this, it's a good practice create a Docker network.
docker network create
You can check a list of created Docker networks by running the following command:
docker network list
Step 3 - Run the Ollama container
In this tutorial, we're going to run Ollama with CPU only. If you need to use GPU, the official documentation provide a step-by-step guide.
The command to run the container is also listed in the documentation, but we need to specify which network it should connect to, so we must add the --network parameter.
docker run -d --netowk -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Step 4 - Run commands inside the Ollama container
To download Ollama models, we need to run ollama pull command.
To do this, we simply execute the command below, which enables the execution inside the container by enabling the interative mode (-it parameter).
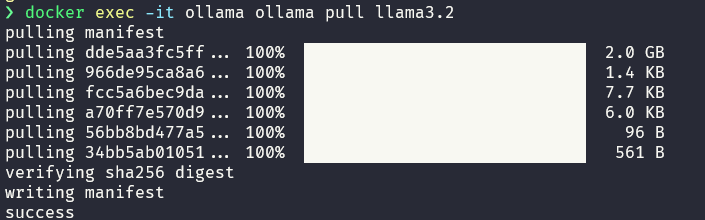
Then, we run ollama pull to download the llama3.2:latest (3B), quantized model:
docker exec -it ollama ollama pull llama3.2
Visit the Ollama website to check the list of available models. Now, wait for the download to finish.
You'll get this:
Step 5 - Check the downloaded models
To list the locally available models, just run:
ollama list
You should get this output:

So you're done! Now you have Ollama running (using only the CPU), with the llama3.2:latest model available locally. To run it with a GPU, check the documentation link in Step 3.
I'll share more short notes on working with Ollama and LangChain in the next few days. Stay tuned!