![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)



























































































































































































































































































































































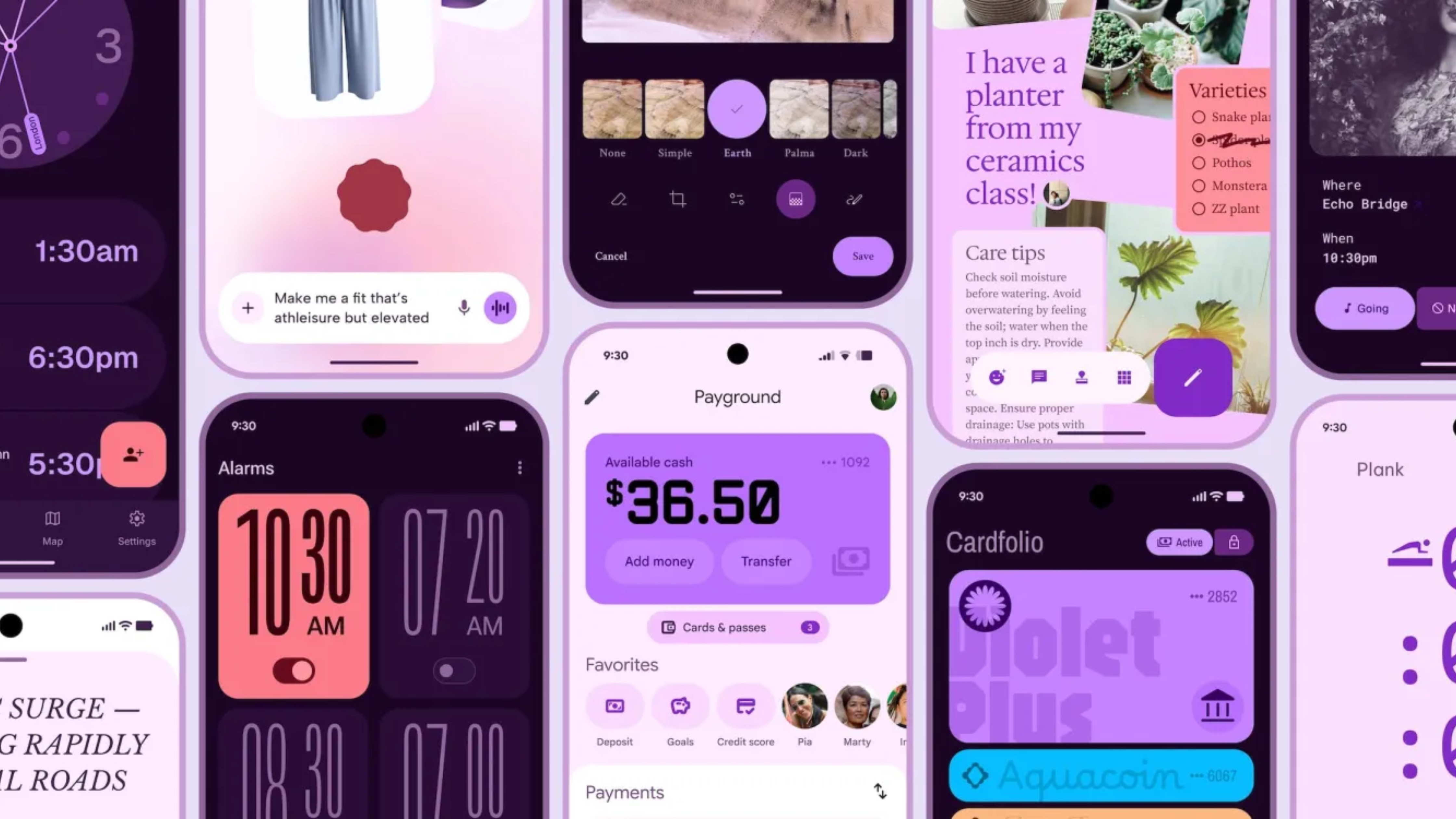





















![Apple Shares Official Teaser for 'Highest 2 Lowest' Starring Denzel Washington [Video]](https://www.iclarified.com/images/news/97221/97221/97221-640.jpg)

![Under-Display Face ID Coming to iPhone 18 Pro and Pro Max [Rumor]](https://www.iclarified.com/images/news/97215/97215/97215-640.jpg)
![New Powerbeats Pro 2 Wireless Earbuds On Sale for $199.95 [Lowest Price Ever]](https://www.iclarified.com/images/news/97217/97217/97217-640.jpg)
































































































Rethinking Scaling: Robustness Tradeoffs in Parameter-Matched NLP Models
Abstract “Benchmarking should no longer reward the model that climbs highest. It should reveal the one that falls slowest. What matters is not peak performance — but how gracefully we fail.” This paper confronts the madness of modern NLP benchmarking — a race funded by VC dollars, gamified by leaderboards, and seduced by scale. We reject the premise that bigger is better, and instead ask: What survives when the numbers are stripped away? We compare two parameter-matched models — a 123 k-parameter Tiny BERT and a 123 k-parameter ElasticFourierTransformer (EFT) — under structured character-level corruption. While EFT proves more resilient at scale (~5 M parameters), both models degrade similarly when compressed. The gains from 40× more parameters? A few points of whipped-cream accuracy that melt under pressure. These findings expose a central fraud in model evaluation: that small improvements, purchased with massive compute, are passed off as innovation. The result isn’t progress — it’s expensive stasis. This paper offers not a solution, but a refusal: a refusal to pretend that overfitting to scale is robustness. 1. Experimental Design “We didn’t rig the floorboards — we used the same dataset, the same tokenizer, and the same task definition trusted by hundreds of published works. If this collapses, it’s not our setup. It’s the system.” Before we go further: maybe our model setup is flawed, or maybe the dataset isn’t perfect. That’s a fair concern. But here’s what we used — nothing exotic, just industry-standard defaults: from datasets import load_dataset from transformers import BertTokenizer def prepare_data(): ds = load_dataset("glue", CFG["task"]) tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") This is the same GLUE SST-2 setup used across hundreds of papers and the same tokenizer backed by countless benchmarks. So if everything sucks, it’s not because we rigged the floorboards. It’s because the house was already built on sand. To ensure fairness and transparency — especially for readers who suspect we sabotaged BERT to favor our custom model — we explicitly document the configuration used to construct the parameter-matched Tiny BERT model: from transformers import BertConfig, BertForSequenceClassification # Honest 123 k-param BERT bert_cfg = BertConfig( hidden_size=4, num_hidden_layers=4, num_attention_heads=2, intermediate_size=8, vocab_size=tokenizer.vocab_size, max_position_embeddings=128, num_labels=2 ) model = BertForSequenceClassification(bert_cfg) model.load_state_dict(torch.load("EFT/bert_acc79.pth", map_location="cpu")) This is not a crippled strawman. This is a legitimate transformer architecture, scaled down precisely to match the parameter count of the Tiny EFT. If anything, this configuration flatters BERT. Phase I: Mid-Scale Evaluation (~5 M parameters) We first benchmarked ElasticFourierTransformer (EFT) and BERT at approximately 5 million trainable parameters. The goal was to evaluate robustness under noise in a setting where both architectures have sufficient capacity to manifest their inductive biases. EFT was configured with a deeper spectral stack, and BERT used a trimmed-down transformer backbone with similar hidden width. This stage replicated conventional benchmarking setups, allowing us to confirm prior findings that EFT outperforms BERT in generalization under perturbation — particularly in the 10–30% noise band. Phase II: Compression to 123 k Parameters In the second phase, we reduced both models to ~123 k parameters. Here, EFT’s advantages narrowed or reversed. With limited dimensionality and depth, BERT’s hard-coded token-aligned attention proved more resilient than EFT’s frequency-domain abstractions. By holding model size constant across architectures, this phase exposed the nonlinear nature of scaling, and tested which design degrades more gracefully under stress. Task: Binary sentiment classification using the GLUE SST-2 benchmark. Dataset: SST-2 train and validation splits as canonical clean text corpus. Perturbation Strategy: Character-level noise introduced post-tokenization at uniform rates of 10%, 20%, 30%, and 45%. Architectures Compared: Tiny BERT: A minimal transformer with 4 encoder layers, 4-dimensional hidden states, 2 attention heads, ~123 k trainable parameters. Tiny EFT: A frequency-aware ElasticFourierTransformer with matched layer depth and hidden width, also ~123 k parameters. Evaluation Metric: Classification accuracy on corrupted validation sets, focusing on the trajectory of degradation as model capacity is held constant. 2. Results “It wasn’t about who scored higher. It was about how insultingly little the score changed when we added 40× more parameters.” 2.1 Parameter-Matched (123 k) Results Perturbation BERT Acc (%) EFT Acc (%) 10% 59.98 58.37 20% 54.59 57.11 30% 49.54 49

Abstract
“Benchmarking should no longer reward the model that climbs highest. It should reveal the one that falls slowest. What matters is not peak performance — but how gracefully we fail.”
This paper confronts the madness of modern NLP benchmarking — a race funded by VC dollars, gamified by leaderboards, and seduced by scale. We reject the premise that bigger is better, and instead ask: What survives when the numbers are stripped away?
We compare two parameter-matched models — a 123 k-parameter Tiny BERT and a 123 k-parameter ElasticFourierTransformer (EFT) — under structured character-level corruption. While EFT proves more resilient at scale (~5 M parameters), both models degrade similarly when compressed. The gains from 40× more parameters? A few points of whipped-cream accuracy that melt under pressure.
These findings expose a central fraud in model evaluation: that small improvements, purchased with massive compute, are passed off as innovation. The result isn’t progress — it’s expensive stasis. This paper offers not a solution, but a refusal: a refusal to pretend that overfitting to scale is robustness.
1. Experimental Design
“We didn’t rig the floorboards — we used the same dataset, the same tokenizer, and the same task definition trusted by hundreds of published works. If this collapses, it’s not our setup. It’s the system.”
Before we go further: maybe our model setup is flawed, or maybe the dataset isn’t perfect. That’s a fair concern.
But here’s what we used — nothing exotic, just industry-standard defaults:
from datasets import load_dataset
from transformers import BertTokenizer
def prepare_data():
ds = load_dataset("glue", CFG["task"])
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
This is the same GLUE SST-2 setup used across hundreds of papers and the same tokenizer backed by countless benchmarks. So if everything sucks, it’s not because we rigged the floorboards. It’s because the house was already built on sand.
To ensure fairness and transparency — especially for readers who suspect we sabotaged BERT to favor our custom model — we explicitly document the configuration used to construct the parameter-matched Tiny BERT model:
from transformers import BertConfig, BertForSequenceClassification
# Honest 123 k-param BERT
bert_cfg = BertConfig(
hidden_size=4,
num_hidden_layers=4,
num_attention_heads=2,
intermediate_size=8,
vocab_size=tokenizer.vocab_size,
max_position_embeddings=128,
num_labels=2
)
model = BertForSequenceClassification(bert_cfg)
model.load_state_dict(torch.load("EFT/bert_acc79.pth", map_location="cpu"))
This is not a crippled strawman. This is a legitimate transformer architecture, scaled down precisely to match the parameter count of the Tiny EFT. If anything, this configuration flatters BERT.
Phase I: Mid-Scale Evaluation (~5 M parameters)
We first benchmarked ElasticFourierTransformer (EFT) and BERT at approximately 5 million trainable parameters. The goal was to evaluate robustness under noise in a setting where both architectures have sufficient capacity to manifest their inductive biases. EFT was configured with a deeper spectral stack, and BERT used a trimmed-down transformer backbone with similar hidden width.
This stage replicated conventional benchmarking setups, allowing us to confirm prior findings that EFT outperforms BERT in generalization under perturbation — particularly in the 10–30% noise band.
Phase II: Compression to 123 k Parameters
In the second phase, we reduced both models to ~123 k parameters. Here, EFT’s advantages narrowed or reversed. With limited dimensionality and depth, BERT’s hard-coded token-aligned attention proved more resilient than EFT’s frequency-domain abstractions.
By holding model size constant across architectures, this phase exposed the nonlinear nature of scaling, and tested which design degrades more gracefully under stress.
Task: Binary sentiment classification using the GLUE SST-2 benchmark.
Dataset: SST-2 train and validation splits as canonical clean text corpus.
Perturbation Strategy: Character-level noise introduced post-tokenization at uniform rates of 10%, 20%, 30%, and 45%.
Architectures Compared:
- Tiny BERT: A minimal transformer with 4 encoder layers, 4-dimensional hidden states, 2 attention heads, ~123 k trainable parameters.
- Tiny EFT: A frequency-aware ElasticFourierTransformer with matched layer depth and hidden width, also ~123 k parameters.
Evaluation Metric: Classification accuracy on corrupted validation sets, focusing on the trajectory of degradation as model capacity is held constant.
2. Results
“It wasn’t about who scored higher. It was about how insultingly little the score changed when we added 40× more parameters.”
2.1 Parameter-Matched (123 k) Results
| Perturbation | BERT Acc (%) | EFT Acc (%) |
|---|---|---|
| 10% | 59.98 | 58.37 |
| 20% | 54.59 | 57.11 |
| 30% | 49.54 | 49.89 |
| 45% | 49.20 | 48.97 |
2.2 Mid-Scale (5 M+) Results
| Perturbation | BERT Acc (%) | EFT Acc (%) |
|---|---|---|
| 10% | 64.33 | 64.68 |
| 20% | 54.36 | 56.65 |
| 30% | 52.41 | 54.47 |
| 45% | 49.54 | 48.05 |
At this scale, EFT maintains a consistent edge over BERT from 10% through 30% noise. At 45% perturbation, performance converges. This confirms EFT’s structural generalization improves with capacity — the Fourier layers need room to breathe.
3. Discussion
“You paid 40× more — in FLOPs, in time, in budget — and what did you get? A tablespoon of whipped cream on the same brittle cake.”
The margins don’t lie — but they do insult our intelligence.
You pay 40× more — in parameters, in FLOPs, in dollars — and what do you get? A tablespoon of extra accuracy foam. A few single-digit wins under sterile conditions that evaporate the moment real-world perturbation enters the picture.
We’re told 5 million parameters is "small" in the age of LLMs. Fine. But if 123 k parameters can hold nearly the same ground under chaos, we’re not underestimating the small model — we’re overestimating the large one.
What does it mean when a 40× increase in parameter count yields a single-digit change in corrupted accuracy? It means the entire scaling premise collapses under stress. The 5 M model is not smarter — just bloated. The 123 k model is not overfitting — it’s surviving.
BERT improves from 59.9% to 64.3%. EFT goes from 58.3% to 64.6%. That’s less than 6 percentage points across an order-of-magnitude of compute. If this is what progress looks like, then we need to question what we’ve defined as success.
This isn’t just diminishing returns — it’s regression disguised as growth. Benchmarks have become rituals, rewarding architectures that memorize just enough to win clean validation sets, but collapse when perturbation enters the room.
The truth is harsh: scaling made us lazy. It made us forget that model quality isn’t a product of quantity — it’s a function of how that quantity breaks. And when 5 M parameters break as easily as 123 k, the spell is broken.
We didn’t just benchmark models. We undressed the myth of scale and caught it selling snake oil.
And before anyone says “hey, 6% is still progress” — no. For god’s sake, it’s not. That’s just the result of the big numbers game. Throw 400× more parameters at a problem, and statistically, something is bound to click. One of those neurons will land on the right side of the margin. That’s not intelligence. That’s brute-force averaging.
This isn’t progress. It’s precision inflation. It’s renting a nuclear plant to toast your bread and calling it culinary innovation.
4. Implications
“Scaling doesn’t just fail to fix fragility — it conceals it behind marginal gains and press-release decimals.”
This isn’t about selling one model over another. It’s about the realization that all our models, at all scales, are subject to a warped incentive structure. We reward brute force over graceful failure. We celebrate marginal gains bought at exponential cost.
Let’s stop pretending this is about architectural innovation. When 400× more compute yields less than a 6% bump in noisy conditions, that’s not advancement — that’s academic theater. And when the benchmarks used to justify billion-dollar infrastructure ignore how models degrade under stress, we’re not evaluating intelligence — we’re laundering inefficiency.
Yes, our tiny models survived longer than they should have. Yes, our 5 M models barely earned their existence. But the real story isn’t about which line is higher. It’s about how absurdly flat the curve is across two orders of magnitude.
5. Recommendation
“We don’t need better benchmarks. We need honest ones. Ones that show the crack before the collapse.”
Scrap the leaderboard mindset. Stop optimizing for the peak when the trough tells you more. We propose a shift toward Degradation-First Evaluation — not to celebrate failures, but to measure how models handle inevitable breakdowns.
- If a model fails, we want to know how soon, how steep, and how stupidly.
- If a model scales, we want to know what it cost and what it hid.
Metrics must include not just accuracy, but slope of decay, parameter efficiency under noise, and failure modes under constraint. Until that becomes standard, we’re benchmarking delusions.
6. Conclusion
“We don’t need bigger models — we need models that break with dignity.”
This study reveals a deeper narrative beneath the surface of performance metrics. The question is no longer “Who performs best?” but rather “Whose design degrades with intention, not collapse?”
We witnessed BERT’s compact form exhibit surprising robustness — not as a triumph of architecture, but as a testimony to well-aligned inductive bias under strict constraint. We saw EFT’s spectral mechanism falter under compression, yet thrive in higher dimensions, reaffirming that design philosophies require adequate expressive bandwidth to manifest.
What we benchmark today is not only accuracy — it is resilience. And what we discover, if we look honestly, is not which model to bet on next quarter, but which principles deserve our long-term trust. Scaling does not merely amplify performance; it amplifies fragility, rigidity, or elegance depending on what the architecture carries at its core.
If we care about building models that generalize, we must stop worshipping those that only scale. Our future does not belong to the biggest — it belongs to the most stable, the most interpretable, and the most justifiable when the data falls apart.