












































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)













































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)























































































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)












































































































![Apple Drops New Immersive Adventure Episode for Vision Pro: 'Hill Climb' [Video]](https://www.iclarified.com/images/news/97133/97133/97133-640.jpg)

![Most iPhones Sold in the U.S. Will Be Made in India by 2026 [Report]](https://www.iclarified.com/images/news/97130/97130/97130-640.jpg)
![Apple to Shift Robotics Unit From AI Division to Hardware Engineering [Report]](https://www.iclarified.com/images/news/97128/97128/97128-640.jpg)






















































































































Reactive Polling: Efficient Data Monitoring
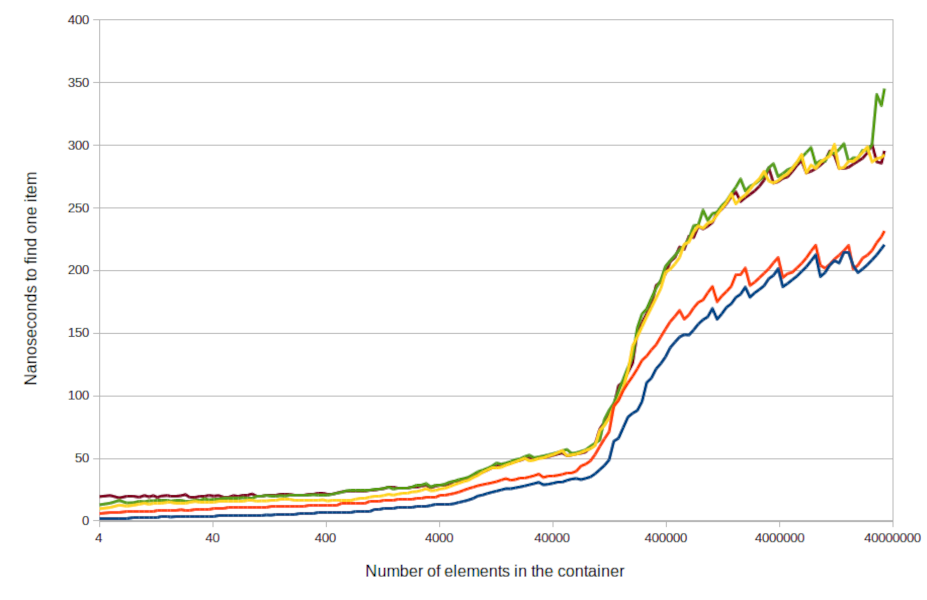
In the landscape of modern software systems, efficient data monitoring remains a crucial aspect for ensuring real-time responsiveness, minimizing resource use, and maintaining system stability. Reactive polling emerges as an innovative technique that blends the benefits of traditional polling with reactive programming principles to create an adaptive, resource-efficient approach to data retrieval. As developers and architects grapple with high-volume, asynchronous data streams, understanding reactive polling - especially within the context of reactive polling Java implementations - becomes essential. Alex Nguyen dives deep into the core concepts, mechanisms, implementations, and best practices surrounding reactive polling, positioning it as a pivotal strategy in contemporary event-driven architectures. Why traditional polling can be wasteful? Traditional polling involves periodically checking a data source at fixed intervals to determine if new information is available. While straightforward, this approach often leads to significant inefficiencies. The fixed frequency means that systems frequently query data sources regardless of whether changes have occurred, resulting in unnecessary network traffic, increased server load, and higher latency for change detection when implemented naively. For example, in a scenario where data updates are infrequent, polling every few seconds may generate dozens or hundreds of redundant requests per minute. These requests not only consume bandwidth but also strain servers, especially when scaled across large distributed systems. Moreover, fixed interval polling cannot adapt to varying data change patterns, leading to either missed opportunities for rapid update detection or wasted resources during quiet periods. This inefficiency becomes more pronounced in applications such as dashboards, log monitoring, or IoT sensor data collection, where timely updates are critical but frequent polling can cause bottlenecks or cost escalations. Thus, the need for smarter, more adaptive strategies arises - enter reactive polling. When push-based systems (WebSockets, SSE) aren’t an option? Push-based architectures like WebSockets and Server-Sent Events (SSE) facilitate real-time communication by establishing persistent connections where servers actively send updates to clients. They are highly efficient for many scenarios, reducing unnecessary network chatter and providing low-latency data delivery. However, these systems aren’t always feasible. Some legacy infrastructures lack support for persistent connections, or firewalls and security policies restrict open ports required for WebSockets. In environments with strict compliance requirements or intermittent connectivity, maintaining persistent channels might be impractical. Additionally, certain cloud or serverless platforms impose constraints that hinder long-lived connections, making push models less suitable. Furthermore, not all systems require constant updates; some may only occasionally change, rendering a push-based method overly complex or resource-consuming. For these cases, a hybrid approach that retains some of the benefits of reactive programming while avoiding the limitations of push-based systems is necessary. Reactive polling as a hybrid, adaptive approach? Reactive polling provides a compelling middle ground, combining elements of traditional polling and reactive programming paradigms. Instead of blindly querying data sources at fixed intervals, reactive polling employs lightweight checks to detect potential changes before initiating costly fetches, adapting its behavior based on observed data patterns. Through this hybrid, adaptive nature, reactive polling minimizes unnecessary load and optimizes response times. It leverages concepts like data streams, event handling, and observer pattern principles, creating a push-like experience without requiring persistent connections. This makes it particularly valuable in scenarios where push isn’t practical but near-real-time responsiveness is still desired. By integrating reactive extensions and emphasizing non-blocking, asynchronous data flows, reactive polling aligns with modern reactive programming ecosystems. Its ability to intelligently balance resource use and timeliness positions it as a versatile approach for dynamic, data-driven applications. Reactive Polling: Definition and Core Principles Formal definition of reactive polling Reactive polling is an approach to data monitoring where a client performs periodic, lightweight checks to determine if a more resource-intensive data fetch is necessary. It incorporates the principles of reactive programming, emphasizing asynchronous, non-blocking interactions, and adapts its polling interval based on data change signals. Unlike traditional polling, which executes full data fetches at predetermined intervals regardless of data state, reactive polling employs a dual-function architecture: a lightweight check functi
In the landscape of modern software systems, efficient data monitoring remains a crucial aspect for ensuring real-time responsiveness, minimizing resource use, and maintaining system stability. Reactive polling emerges as an innovative technique that blends the benefits of traditional polling with reactive programming principles to create an adaptive, resource-efficient approach to data retrieval.
As developers and architects grapple with high-volume, asynchronous data streams, understanding reactive polling - especially within the context of reactive polling Java implementations - becomes essential. Alex Nguyen dives deep into the core concepts, mechanisms, implementations, and best practices surrounding reactive polling, positioning it as a pivotal strategy in contemporary event-driven architectures.
Why traditional polling can be wasteful?
Traditional polling involves periodically checking a data source at fixed intervals to determine if new information is available. While straightforward, this approach often leads to significant inefficiencies. The fixed frequency means that systems frequently query data sources regardless of whether changes have occurred, resulting in unnecessary network traffic, increased server load, and higher latency for change detection when implemented naively.
For example, in a scenario where data updates are infrequent, polling every few seconds may generate dozens or hundreds of redundant requests per minute. These requests not only consume bandwidth but also strain servers, especially when scaled across large distributed systems. Moreover, fixed interval polling cannot adapt to varying data change patterns, leading to either missed opportunities for rapid update detection or wasted resources during quiet periods.
This inefficiency becomes more pronounced in applications such as dashboards, log monitoring, or IoT sensor data collection, where timely updates are critical but frequent polling can cause bottlenecks or cost escalations. Thus, the need for smarter, more adaptive strategies arises - enter reactive polling.
When push-based systems (WebSockets, SSE) aren’t an option?
Push-based architectures like WebSockets and Server-Sent Events (SSE) facilitate real-time communication by establishing persistent connections where servers actively send updates to clients. They are highly efficient for many scenarios, reducing unnecessary network chatter and providing low-latency data delivery.
However, these systems aren’t always feasible. Some legacy infrastructures lack support for persistent connections, or firewalls and security policies restrict open ports required for WebSockets. In environments with strict compliance requirements or intermittent connectivity, maintaining persistent channels might be impractical. Additionally, certain cloud or serverless platforms impose constraints that hinder long-lived connections, making push models less suitable.
Furthermore, not all systems require constant updates; some may only occasionally change, rendering a push-based method overly complex or resource-consuming. For these cases, a hybrid approach that retains some of the benefits of reactive programming while avoiding the limitations of push-based systems is necessary.
Reactive polling as a hybrid, adaptive approach?
Reactive polling provides a compelling middle ground, combining elements of traditional polling and reactive programming paradigms. Instead of blindly querying data sources at fixed intervals, reactive polling employs lightweight checks to detect potential changes before initiating costly fetches, adapting its behavior based on observed data patterns.
Through this hybrid, adaptive nature, reactive polling minimizes unnecessary load and optimizes response times. It leverages concepts like data streams, event handling, and observer pattern principles, creating a push-like experience without requiring persistent connections. This makes it particularly valuable in scenarios where push isn’t practical but near-real-time responsiveness is still desired.
By integrating reactive extensions and emphasizing non-blocking, asynchronous data flows, reactive polling aligns with modern reactive programming ecosystems. Its ability to intelligently balance resource use and timeliness positions it as a versatile approach for dynamic, data-driven applications.
Reactive Polling: Definition and Core Principles
Formal definition of reactive polling
Reactive polling is an approach to data monitoring where a client performs periodic, lightweight checks to determine if a more resource-intensive data fetch is necessary. It incorporates the principles of reactive programming, emphasizing asynchronous, non-blocking interactions, and adapts its polling interval based on data change signals.
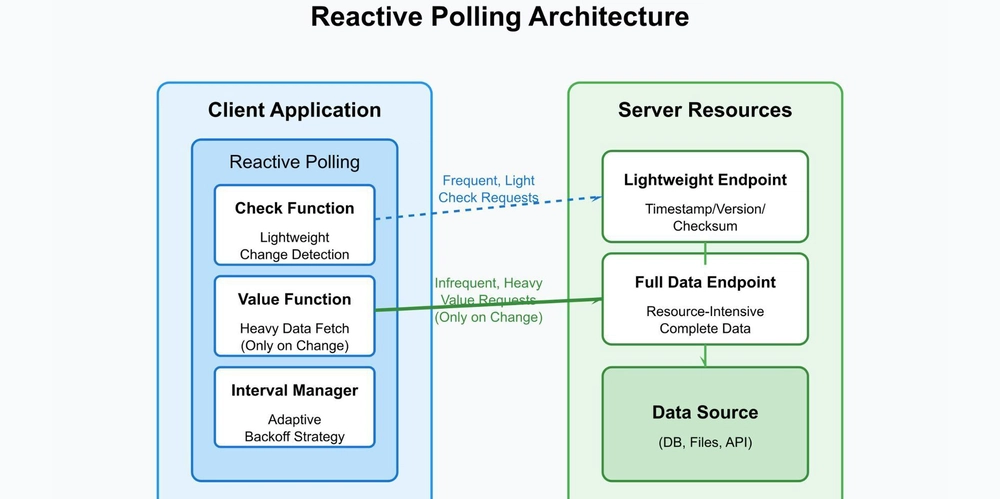
Unlike traditional polling, which executes full data fetches at predetermined intervals regardless of data state, reactive polling employs a dual-function architecture: a lightweight check function and a heavier value fetch function. The check function detects possible changes efficiently, triggering the value function only when necessary. This process results in reduced network load, lowered server stress, and faster detection of relevant updates - all aligned with reactive extensions' push-based architecture.
The core idea is built on the concept of observable sequences: data streams that can be observed, filtered, and reacted upon. By combining this with event handling and data streams, reactive polling forms a robust framework for maintaining synchronization with changing data sources in an efficient, scalable manner.
Dual-function architecture
Check function (lightweight change detector)
The check function serves as an initial filter that quickly assesses whether the data has changed since the last inspection. It’s designed to be minimal in resource consumption, utilizing simple metadata such as timestamps, version numbers, or checksums.
For example, the check function might return a timestamp indicating the last modification date or a checksum hash of the current dataset. Its purpose is to provide an inexpensive indicator of potential updates, thereby avoiding unnecessary heavy fetches when data remains unchanged.
In reactive polling, this component is critical because it reduces the number of expensive calls, enabling the system to operate efficiently even under high load. Its implementation varies depending on the data source but should prioritize speed and low overhead.
Value function (resource-intensive data fetch)
Once the check function signals a potential change, the value function is invoked to retrieve the actual data. This operation often involves complex database queries, API calls, or file reads, which are comparatively costly in terms of processing time and network bandwidth.
The design principle here is to limit these expensive operations to instances when they are genuinely needed, thus conserving resources and improving overall system responsiveness. When combined with reactive programming, the value function’s invocation can be integrated into observable sequences, allowing seamless data flow and event-driven reactions.
Adaptive interval strategies (static vs. dynamic)
A key feature of reactive polling is its ability to adapt polling intervals based on recent data activity. Static intervals - fixed delays between checks - are simple to implement but often inefficient. Dynamic strategies adjust the interval based on signals from the check function, balancing promptness with resource conservation.
- Static intervals: The simplest form, where checks occur at regular, preset durations irrespective of data change probability.
- Exponential backoff: The polling interval increases exponentially during periods of inactivity, reducing load during quiet times and ramping up responsiveness when activity resumes.
- Reset-on-change: When a change is detected, the interval resets to a shorter duration to allow quick follow-up checks.
- Repeat-when-empty with timeout: Continues checking at predefined rates until a change is confirmed, then adjusts accordingly.
These strategies are vital for tuning the system's responsiveness against resource constraints, especially in reactive polling java implementations, where adjusting intervals dynamically plays a central role.
Caching of last-seen value
To prevent redundant operations and improve performance, reactive polling typically maintains a cache of the last known value or change indicator. When the check function signals no change, the cached data remains valid, avoiding unnecessary re-fetches.
This caching mechanism ensures that the system only performs heavy value fetches when truly needed. Integrating cache invalidation logic carefully aligns with the observer pattern, where subscribers only react to genuine updates, maintaining data consistency and reducing jitter in data streams.
Integration with reactive programming paradigms
Finally, reactive polling naturally aligns with broader reactive programming principles. It leverages data streams, push-based architecture, and observable sequences to encapsulate asynchronous data flows.
By embedding reactive extensions such as RxJava, Reactor, or Spring WebFlux, developers can craft pipelines where change detection seamlessly propagates through the system, enabling real-time, scalable, event-driven applications. The fusion of reactive polling with these frameworks empowers systems that are both efficient and highly responsive.
Reactive Polling Mechanics: How It Works
Step 1: lightweight “check” (timestamp, version, checksum)
The first step in reactive polling involves executing a check function that performs a minimal operation to determine if data has changed. Typically, this involves retrieving a simple piece of metadata, such as a timestamp, version number, checksum, or a small indicator variable.
This lightweight check replaces a full data fetch, drastically reducing resource consumption, especially when data doesn’t change frequently. For instance, polling a file's last modified timestamp or a version number stored in a cache can serve as effective indicators.
Implementing this step correctly requires choosing a reliable, unique, and easily retrievable change indicator associated with the data source. It should be inexpensive to obtain and guarantees a high signal-to-noise ratio - meaning it should accurately reflect whether the data has been altered.
Step 2: heavy “value” fetch only on change
When the check function detects a change, the next step is to invoke the value function. This function performs the actual data retrieval, which could involve complex queries, REST API calls, or file reads.
The key advantage is that this fetch occurs only when necessary, significantly reducing unnecessary load. If the check indicates no change, the system can safely skip the expensive operation, relying on cached data or previous outputs.
In reactive programming, this behavior can be modeled using observable sequences, where the emission of new data depends on change signals. Properly designing this flow ensures minimal latency in detecting updates while maintaining system efficiency.
Interval adjustment patterns
To optimize the polling process further, various interval adjustment patterns are employed. These patterns govern how the system modulates its polling frequency based on data activity, combining reactiveness with resource awareness.
Exponential backoff
In this pattern, the interval between checks increases exponentially during periods of inactivity. After each check indicating no change, the delay doubles up to a maximum limit. This approach reduces network and server load during quiet times, conserving resources.
When a change is finally detected, the interval resets to a shorter duration, ensuring rapid detection of subsequent updates. Exponential backoff is widely used in network protocols and adaptive systems owing to its simplicity and effectiveness.
Reset-on-change
Here, whenever a change is signaled by the check function, the polling interval is reset to a predefined shorter period. This ensures prompt detection of subsequent changes after an initial update, balancing responsiveness with efficiency.
Repeat-when-empty with timeout
This strategy involves repeatedly polling at fixed intervals until a change is detected. If no change occurs within a specified timeout, the cycle repeats. This pattern is useful in environments with unpredictable change patterns, maintaining a baseline level of vigilance.
Each of these strategies enhances the core reactive polling mechanism, tailoring its behavior to specific application needs, data change characteristics, and system constraints.
Reactive Polling Implementations by Framework
R Shiny (reactivePoll)
Signature and arguments
In R Shiny, reactivePoll is a built-in function enabling reactive data polling tailored to Shiny apps. Its signature includes parameters such as the polling interval, a "check" function to determine if data has changed, and a "value" function to fetch updated data.
The general syntax is:
reactivePoll(
intervalMillis,
session = getDefaultReactiveDomain(),
checkFunc,
valueFunc
)-
intervalMillis: default interval in milliseconds for polling. -
checkFunc: returns a simple indicator (timestamp, checksum). -
valueFunc: retrieves the full dataset when a change is detected.
This design allows developers to specify custom logic for both change detection and data retrieval, fostering flexible, efficient monitoring.
CSV-file monitoring example
Imagine monitoring a CSV file for changes. The check function could read the file's last modified timestamp:
checkFunc checkFunction())
.distinctUntilChanged()
.flatMap(changed -> changed ? fetchValue() : Mono.empty());This setup polls every five seconds, but only triggers data fetches when the check function signals a change. The method supports fully asynchronous, non-blocking execution compatible with reactive systems.
Wrapping blocking API in Mono
For blocking APIs, reactive adapters like Mono.fromCallable() are used:
Mono.defer(() -> Mono.justBlocking(() -> fetchFromHeavyAPI()))
.subscribeOn(Schedulers.boundedElastic());This pattern enables integration of existing, blocking data sources into reactive workflows without sacrificing responsiveness or scalability.
Spring WebFlux (Java)
webClient polling endpoint example
In Spring WebFlux, WebClient facilitates asynchronous, non-blocking HTTP requests ideal for reactive polling. A polling loop can be structured as:
WebClient client = WebClient.create();
Flux.interval(Duration.ofSeconds(10))
.flatMap(tick -> client.get()
.uri("/api/data")
.retrieve()
.bodyToMono(Data.class))
.subscribe(data -> processData(data));This code polls an API endpoint every 10 seconds, seamlessly integrating into the reactive stream. Combining this with change detection logic yields an efficient, scalable reactive polling solution.
Python asyncio
asyncio.Condition + periodic wakeup
In Python, asyncio offers primitives like Condition objects to implement custom reactive polling loops. A typical pattern involves waiting for a condition or periodic wakeup:
async def poll(interval):
while True:
await asyncio.sleep(interval)
if check_change():
data = fetch_value()
handle_data(data)Enhancing this with event-driven triggers and backoff strategies can produce sophisticated reactive polling systems in Python’s async ecosystem.
RxJS / Node.js
In Node.js, RxJS enables reactive streams with operators like interval(), distinctUntilChanged(), and switchMap(). Example:
import from 'rxjs';
import from 'rxjs/operators';
const polling$ = interval(5000).pipe(
switchMap(() => checkForChange()),
distinctUntilChanged()
);
polling$.subscribe(changeDetected => {
if (changeDetected) {
fetchData().then(data => updateUI(data));
}
});This pattern creates a resource-efficient, composable pipeline for reactive polling, suitable for frontend or server-side Node.js applications.
RxJava (.NET, C# Reactive Extensions)
RxJava and other Reactive Extensions, such as in .NET, provide powerful operators for implementing reactive polling. Typical usage involves combining timers with change signals:
Observable.Interval(TimeSpan.FromSeconds(5))
.SelectMany(_ => checkForChange())
.DistinctUntilChanged()
.Subscribe(changeDetected =>
{
if (changeDetected)
{
FetchValue();
}
});This pattern supports complex, multi-source data flows with minimal overhead and high scalability.
Mutiny on Quarkus
Mutiny, integrated into Quarkus, offers a modern reactive API for Java microservices:
Multi.interval(Duration.ofSeconds(5))
.onItem().transformToUni(tick -> checkFunction().onItem().ifTrue().call(() -> fetchValue()))
.subscribe().with(data -> processData(data));This simplifies reactive polling implementation, providing native support for adaptive, non-blocking data streams.
Common Application Scenarios
File-change monitoring (logs, configs)
Monitoring file changes is common in configuration management and log analysis. Traditional approaches involve polling file modification timestamps; reactive polling improves efficiency by only fetching and processing files when changes occur.
Imagine a system that watches a configuration file to reload settings dynamically. Using reactive polling, the system checks the file's timestamp periodically. When a change is detected, it loads the new configuration, minimizing downtime and resource use.
Database polling (new rows, updates)
Databases often require polling mechanisms to detect new data or updates, especially when real-time triggers aren’t available. Reactive polling allows systems to poll minimally, reducing database load while maintaining up-to-date views.
For example, a dashboard displaying stock prices might poll a database for new entries every few seconds, but only fetch detailed data when an update occurs, using lightweight checks like row versioning.
Legacy API integration
Many enterprises rely on legacy APIs that do not support real-time pushes. Reactive polling provides a way to integrate these systems by periodically polling endpoints, but with adaptive intervals and change detection to avoid unnecessary requests.
This approach balances compatibility with efficiency, extending legacy systems’ usability in modern architectures without overwhelming servers or networks.
Real-time dashboards (stock quotes, metrics)
Dashboards visualizing live data must update promptly without overloading backend services. Reactive polling facilitates this by performing intelligent, event-driven data refreshes aligned with data change signals, not fixed schedules.
For instance, a stock trading application polls for quote updates, only fetching detailed data when price changes exceed thresholds, improving responsiveness and reducing bandwidth.
Message-queue polling (Kafka, SQS)
Polling message queues like Kafka or SQS for new messages is common in event-driven architectures. While pull models are less ideal than consumers listening passively, reactive polling allows controlled, adaptive checks, reducing unnecessary load and enabling backpressure handling.
This pattern ensures applications remain responsive, scalable, and resilient under varying load conditions.
IoT sensor polling
IoT devices often operate with constrained resources. Reactive polling helps by checking sensors at adaptive intervals, increasing frequency during active states and decreasing during quiescent periods, conserving power and bandwidth.
Such systems can swiftly respond to environmental changes while minimizing energy consumption - a critical factor for battery-powered sensors.
Microservice health/config updates
Monitoring service health, configurations, or feature flags across distributed microservices benefits from reactive polling. Systems can perform lightweight health checks at appropriate intervals, reacting immediately to failures or changes, ensuring high availability.
This strategy supports scalable, resilient architectures with minimal overhead.
Reactive Polling Advantages
Reduced network/server load
One of the most compelling benefits of reactive polling is its ability to prevent unnecessary requests. By performing lightweight checks first, it avoids redundant data transfers and server processing, leading to lower bandwidth consumption and server resource utilization.
This advantage is particularly important in cloud environments where costs correlate with data transfer and compute hours. It also contributes to improved system stability during peak loads, preventing overload due to frequent full data fetches.
Lower average latency vs. fixed polling
Adaptive check intervals mean that reactive polling can detect updates more rapidly than fixed-interval methods. When a change occurs, the system can respond immediately, reducing the window of stale data.
Overall, this results in lower average latency for data updates, enhancing user experience in real-time dashboards, alerts, and interactive applications.
Backpressure and non-blocking I/O support
Built on reactive programming principles, reactive polling inherently supports backpressure - controlling data flow to match system capacity - and non-blocking I/O operations. This is essential for scalable applications dealing with high volumes of asynchronous data streams.
Frameworks like Reactor or RxJava make integrating backpressure handling straightforward, ensuring that data producers do not overwhelm consumers.
Works with non-pushable legacy systems
Many older systems lack support for push notifications or persistent connections. Reactive polling provides an easy-to-implement, non-intrusive method to keep such systems integrated into modern, event-driven architectures.
It extends the lifespan and utility of legacy APIs, databases, and file systems by enabling efficient, adaptive data synchronization.
Declarative integration into reactive streams
Since reactive polling aligns with reactive extensions and observable sequences, it can be declaratively composed into complex data pipelines. This promotes cleaner, more maintainable code and easier integration with other reactive components.
Developers can leverage familiar operators, error handling, and transformation patterns, enhancing productivity and system robustness.
Limitations of Reactive Polling and When to Avoid It
Residual cost of periodic checks
Although reactive polling reduces unnecessary load compared to naive polling, the lightweight checks still incur some overhead, especially at very high frequencies or with high volumes of data sources. For extremely sensitive environments, this residual cost might outweigh benefits.
Complexity vs. simple polling
Implementing reactive polling involves additional complexity in managing check and value functions, interval adjustments, caching, and event propagation. For simple or low-frequency applications, traditional polling may suffice and be more straightforward.
Unsuitable for ultra-high-frequency data
While adaptable, reactive polling may struggle to keep pace with ultra-high-frequency data updates, such as high-frequency trading or real-time analytics. In such cases, dedicated push-based or streaming solutions are preferable.
Dependence on a cheap, reliable check function
The effectiveness of reactive polling hinges on the check function being inexpensive and reliable. If the check itself is costly or unreliable, the entire approach diminishes in efficiency or accuracy.
Edge-case risks: polling storms, eventual consistency
Misconfiguration, poor interval tuning, or flawed check logic can lead to polling storms, where multiple systems flood the data source simultaneously, or races causing data inconsistencies. Proper safeguards, error handling, and rate limiting are essential.
Comparison of Reactive Polling to Traditional Polling
| Aspect | Traditional Polling | Reactive Polling |
|---|---|---|
| Mechanism | Full data fetch every interval | Light check, fetch only on change |
| Resource use | High, often redundant requests | Optimized, cache-backed, adaptive |
| Latency behavior | Fixed delay | Adaptive, potentially lower latency |
| Complexity | Simple | Higher, with backoff/error handling |
Reactive polling advances beyond basic fixed-interval polling by incorporating intelligence and adaptability, leading to more efficient data monitoring suited for modern demands.
Best Practices for Reactive Polling
Strict separation: checkFunc vs. valueFunc
Clear separation of duties ensures maintainability and clarity. The check function should be quick and reliable, whereas the value function handles heavyweight data fetching. Avoid coupling these responsibilities to prevent confusion and errors.
Tune initial and max intervals to data frequency
Start with intervals matching expected data change rates, then adjust dynamically based on observed activity. Fine-tuning prevents unnecessary checks and maximizes responsiveness.
Exponential backoff + reset-on-change
Combine backoff strategies to minimize load during idle periods, resetting intervals upon detecting changes for prompt response. This synergy optimizes system efficiency and timeliness.
Robust error handling and retries
Network failures, timeouts, or exceptions should trigger retries with exponential backoff to ensure resilience. Incorporate logging and alerting for anomaly detection.
Caching and idempotent fetch functions
Cache previous values and design fetch operations to be idempotent. This guarantees consistency and simplifies recovery after failures.
Logging & metrics for check/value executions
Monitor check and value function performance to identify issues, optimize parameters, and ensure correctness. Metrics inform better tuning and debugging.
Randomized jitter to prevent storms
Add random jitter to intervals to avoid synchronized polling across distributed nodes, mitigating storm risks and uneven load.
Challenges & Solutions
False positives, use checksums or versioning
Simple metadata can sometimes mislead. Employ checksums or version tags to accurately detect substantive changes, reducing unnecessary fetches.
Synchronizing state across clients, share last-seen token
Shared tokens or identifiers enable multiple clients to stay synchronized, preventing duplicate work or inconsistent views.
Debugging complexity, detailed logs, metrics
Instrument check and fetch functions with comprehensive logging, enabling troubleshooting and performance analysis.
Polling storms, jitter, rate-limit
Implement randomized delays and enforce rate limits to prevent cascading overloads during high-change periods.
Handling long-running value fetches, timeouts, circuit breakers
Use timeouts and circuit breakers to prevent long fetches from blocking or degrading system performance, restoring stability quickly.
Detailed Example: Shiny App
Full R code listing (UI + server)
library(shiny)
ui <- fluidPage(
titlePanel("File Change Monitor"),
mainPanel(
tableOutput("fileData")
)
)
server <- function(input, output, session) {
data <- reactivePoll(
5000,
# check every 5 seconds
checkFunc = function() {
file.info("data.csv")$mtime
},
valueFunc = function() {
read.csv("data.csv")
}
)
output$fileData <- renderTable({
data()
})
}
shinyApp(ui, server)Explanation of each part
- The
reactivePollmonitors thedata.csvfile's modification time. - When a change is detected, the data is reloaded and displayed.
- The UI reacts automatically due to Shiny’s reactive model, providing near real-time updates without unnecessary data loads.
Behavior under file-update scenarios
When the file is modified externally, the system detects the timestamp change within 5 seconds, triggers a re-read, and updates the display seamlessly. During periods of no change, system resources are conserved by skipping expensive fetches.
Theoretical Context
Polling vs. interrupt-driven I/O in OS design
Traditionally, operating systems favor interrupt-driven I/O for efficiency, alerting applications when data is available. Polling, conversely, repeatedly checks for data, wasting CPU resources during idle periods.
Reactive polling echoes the benefits of interrupt-driven models by adopting adaptive, event-driven checks, thus bridging the gap in environments where hardware-level interrupt mechanisms are unavailable or impractical.
Reactive programming fundamentals (data streams, propagation)
Reactive programming revolves around data streams and event propagation, enabling systems to process asynchronous events efficiently. It simplifies handling complex scenarios like live updates, error propagation, and backpressure management.
By leveraging observable sequences and operators, reactive polling becomes a natural extension of these principles, facilitating scalable, responsive applications.
Where reactive polling fits in asynchronous paradigms
Reactive polling complements asynchronous, non-blocking workflows common in modern architectures. It supports reactive extensions, publish-subscribe models, and backpressure handling, making it well-suited for microservices, cloud-native, and event-driven systems.
It acts as a flexible, adaptive layer atop traditional data sources, aligning with reactive programming goals of efficiency and scalability.
Trade-offs vs. push-based (SSE, WebSockets)
Compared with push-based models like SSE and WebSockets, reactive polling is more versatile, especially when infrastructure constraints prohibit persistent connections. However, it generally introduces higher latency and complexity.
Reactive polling excels in environments where push isn’t available or reliable, providing a balanced, adaptive approach suited to diverse operational contexts.
Alternative & Complementary Techniques
| Technique | Description | When to use |
|---|---|---|
| Short Polling | Fixed-interval full fetch | Low change rate, simplicity |
| Long Polling | Server holds request until data/timeout | Moderate scale, reduced load |
| SSE | Unidirectional push from server | One-way real-time updates |
| WebSockets | Bidirectional, persistent connection | Interactive, high-frequency data |
Reactive polling often complements these techniques, enabling flexible, resource-conscious data monitoring strategies tailored to application needs.
Future Directions
Standards for reactive streams & polling patterns
Emerging standards aim to formalize reactive streams and polling behaviors, promoting interoperability, best practices, and tooling support. Initiatives like Reactive Streams Specification and ReactiveX continue evolving, shaping the future of adaptive data monitoring.
Serverless/edge-optimized polling strategies
Integrating reactive polling with serverless architectures and edge computing offers opportunities for ultra-scalable, low-latency monitoring. Lightweight, adaptive checks are ideal for constrained environments, reducing costs and latency.
AI/ML-driven adaptive interval prediction
Applying machine learning to predict optimal polling intervals based on historical data and context could enhance responsiveness and efficiency, automating tuning processes and improving accuracy.
Built-in support in cloud-native frameworks
Major cloud platforms and frameworks are beginning to incorporate reactive polling features, simplifying integration, and enabling widespread adoption in microservices, IoT, and big data applications.
Final Thoughts on Reactive Polling
Reactive polling embodies an intelligent, adaptive approach to data monitoring, harmonizing the immediacy of real-time updates with resource efficiency. By leveraging lightweight change detection, dynamic interval adjustments, and seamless integration with reactive programming practices, it offers a scalable, flexible solution for applications ranging from dashboards to IoT networks.
Its compatibility with legacy systems, support for backpressure, and alignment with modern asynchronous paradigms make it indispensable for architects and developers aiming to build resilient, efficient data-driven systems. As technology progresses, the evolution of reactive polling promises even more sophisticated, autonomous, and integrated data monitoring capabilities, shaping the future of event-driven architectures.


