.jpg)




































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)

















































































































![[Research] Starting Web App in 2025: Vibe-coding, AI Agents….](https://media2.dev.to/dynamic/image/width%3D1000,height%3D500,fit%3Dcover,gravity%3Dauto,format%3Dauto/https:%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fby8z0auultdpyfrx5tx8.png)



























































-RTAガチ勢がSwitch2体験会でゼルダのラスボスを撃破して世界初のEDを流してしまう...【ゼルダの伝説ブレスオブザワイルドSwitch2-Edition】-00-06-05.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)






























































































_roibu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


.webp?#)









































































































![M4 MacBook Air Drops to Just $849 - Act Fast! [Lowest Price Ever]](https://www.iclarified.com/images/news/97140/97140/97140-640.jpg)
![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)






























































































Open Source Image Editing Rivals GPT-4o: Step1X-Edit Framework Revealed
This is a Plain English Papers summary of a research paper called Open Source Image Editing Rivals GPT-4o: Step1X-Edit Framework Revealed. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Closing the Gap Between Open-Source and Closed-Source Image Editing Recent advancements in multimodal models like GPT-4o and Gemini2 Flash have revolutionized image editing capabilities. These proprietary systems excel at fulfilling user editing requests, but a significant gap exists between these closed-source models and their open-source counterparts. Step1X-Edit aims to bridge this divide by providing a state-of-the-art open-source image editing solution with comparable performance to leading closed-source systems. The model combines a Multimodal Large Language Model (MLLM) with a diffusion image decoder to process reference images and user editing instructions effectively. This integration enables accurate interpretation of editing requests and generates high-quality modified images. To achieve this, the researchers developed a comprehensive data generation pipeline producing over a million high-quality training examples. Figure 1: Overview of Step1X-Edit, showing its comprehensive editing capabilities with proprietary-level performance. Step1X-Edit makes three key contributions to the field of image editing: An open-source model that narrows the performance gap between proprietary and publicly available image editing systems A sophisticated data generation pipeline that produces diverse, high-quality training data GEdit-Bench, a novel benchmark based on real-world user editing needs for more authentic evaluation The system demonstrates significant improvements over existing open-source baselines like Prompt-to-Prompt, approaching the performance of leading proprietary models while maintaining full transparency and reproducibility. Image Editing Technology Landscape The Evolution of Image Generation and Editing Image editing technologies have evolved along two primary paths: autoregressive (AR) models and diffusion models, each with distinct strengths and limitations. Autoregressive models treat images as sequences of discrete tokens, enabling structured control through conditioning mechanisms. Works like ControlAR, ControlVAR, and CAR incorporate spatial guidance such as edges and segmentation masks into the decoding process. However, these models often struggle with high-resolution, photorealistic results due to their reliance on discrete visual tokens and sequence length limitations. Diffusion models have emerged as the dominant approach for high-fidelity image synthesis, offering superior photorealism and structural consistency. Starting with DDPM and evolving through Stable Diffusion and ControlNet, these models operate in latent spaces for improved efficiency. Despite their strengths, diffusion models typically depend on static prompts and lack the capacity for multi-turn reasoning, limiting their flexibility in complex editing scenarios. These limitations have driven interest in unified frameworks that combine AR models' symbolic control with diffusion models' generative fidelity, aiming to create more versatile, user-friendly editing systems. Unified Approaches to Instruction-Based Image Editing Unified image editing models aim to bridge semantic understanding with precise visual manipulation in a coherent framework. Early approaches used modular designs connecting MLLMs with diffusion models, as seen in Prompt-to-Prompt, InstructEdit, and BrushEdit. InstructPix2Pix trained a conditional diffusion model using synthetic instruction-image pairs, while MagicBrush improved real-world applicability through high-quality human annotations. Recent developments have enhanced interaction between language and vision components. AnyEdit introduced task-aware routing within a unified diffusion model, while OmniGen adopted a single transformer backbone to jointly encode text and images. General-purpose multimodal models like Gemini and GPT-4o demonstrate strong visual capabilities through joint vision-language training. Despite these advances, existing approaches face significant limitations: Most methods are task-specific rather than general-purpose They typically don't support incremental editing or fine-grained region correspondence Architectural coupling remains shallow in many designs Step1X-Edit addresses these challenges by tightly integrating MLLM-based multimodal reasoning with diffusion-based controllable synthesis, enabling scalable, interactive, and instruction-faithful image editing across diverse editing scenarios. Inside Step1X-Edit: Architecture and Data Building a Massive, High-Quality Dataset for Image Editing Creating an effective image editing model requires large-scale, high-quality training data. The researchers developed a sophisticated data pipeline to address limitations in

This is a Plain English Papers summary of a research paper called Open Source Image Editing Rivals GPT-4o: Step1X-Edit Framework Revealed. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Closing the Gap Between Open-Source and Closed-Source Image Editing
Recent advancements in multimodal models like GPT-4o and Gemini2 Flash have revolutionized image editing capabilities. These proprietary systems excel at fulfilling user editing requests, but a significant gap exists between these closed-source models and their open-source counterparts. Step1X-Edit aims to bridge this divide by providing a state-of-the-art open-source image editing solution with comparable performance to leading closed-source systems.
The model combines a Multimodal Large Language Model (MLLM) with a diffusion image decoder to process reference images and user editing instructions effectively. This integration enables accurate interpretation of editing requests and generates high-quality modified images. To achieve this, the researchers developed a comprehensive data generation pipeline producing over a million high-quality training examples.
Figure 1: Overview of Step1X-Edit, showing its comprehensive editing capabilities with proprietary-level performance.
Step1X-Edit makes three key contributions to the field of image editing:
- An open-source model that narrows the performance gap between proprietary and publicly available image editing systems
- A sophisticated data generation pipeline that produces diverse, high-quality training data
- GEdit-Bench, a novel benchmark based on real-world user editing needs for more authentic evaluation
The system demonstrates significant improvements over existing open-source baselines like Prompt-to-Prompt, approaching the performance of leading proprietary models while maintaining full transparency and reproducibility.
Image Editing Technology Landscape
The Evolution of Image Generation and Editing
Image editing technologies have evolved along two primary paths: autoregressive (AR) models and diffusion models, each with distinct strengths and limitations.
Autoregressive models treat images as sequences of discrete tokens, enabling structured control through conditioning mechanisms. Works like ControlAR, ControlVAR, and CAR incorporate spatial guidance such as edges and segmentation masks into the decoding process. However, these models often struggle with high-resolution, photorealistic results due to their reliance on discrete visual tokens and sequence length limitations.
Diffusion models have emerged as the dominant approach for high-fidelity image synthesis, offering superior photorealism and structural consistency. Starting with DDPM and evolving through Stable Diffusion and ControlNet, these models operate in latent spaces for improved efficiency. Despite their strengths, diffusion models typically depend on static prompts and lack the capacity for multi-turn reasoning, limiting their flexibility in complex editing scenarios.
These limitations have driven interest in unified frameworks that combine AR models' symbolic control with diffusion models' generative fidelity, aiming to create more versatile, user-friendly editing systems.
Unified Approaches to Instruction-Based Image Editing
Unified image editing models aim to bridge semantic understanding with precise visual manipulation in a coherent framework. Early approaches used modular designs connecting MLLMs with diffusion models, as seen in Prompt-to-Prompt, InstructEdit, and BrushEdit. InstructPix2Pix trained a conditional diffusion model using synthetic instruction-image pairs, while MagicBrush improved real-world applicability through high-quality human annotations.
Recent developments have enhanced interaction between language and vision components. AnyEdit introduced task-aware routing within a unified diffusion model, while OmniGen adopted a single transformer backbone to jointly encode text and images. General-purpose multimodal models like Gemini and GPT-4o demonstrate strong visual capabilities through joint vision-language training.
Despite these advances, existing approaches face significant limitations:
- Most methods are task-specific rather than general-purpose
- They typically don't support incremental editing or fine-grained region correspondence
- Architectural coupling remains shallow in many designs
Step1X-Edit addresses these challenges by tightly integrating MLLM-based multimodal reasoning with diffusion-based controllable synthesis, enabling scalable, interactive, and instruction-faithful image editing across diverse editing scenarios.
Inside Step1X-Edit: Architecture and Data
Building a Massive, High-Quality Dataset for Image Editing
Creating an effective image editing model requires large-scale, high-quality training data. The researchers developed a sophisticated data pipeline to address limitations in existing datasets, which often suffer from either scale or quality constraints.
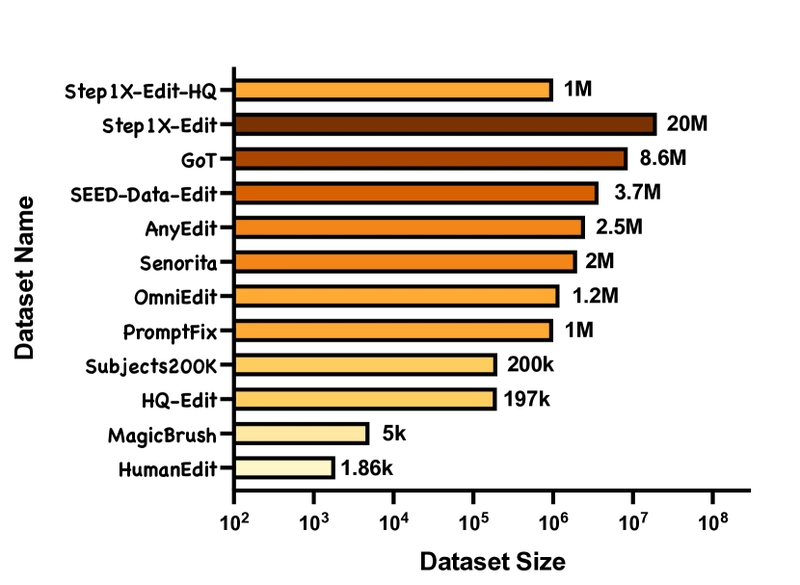
Figure 2: Comparison showing Step1X-Edit's dataset size relative to other image editing datasets.
Through analysis of web-crawled editing examples, the team categorized image editing into 11 distinct types. This taxonomy guided the creation of a comprehensive data pipeline that generated over 20 million instruction-image triplets. After rigorous filtering using both Multimodal LLMs and human annotators, the final dataset contained more than 1 million high-quality examples.
The data creation process incorporated specialized pipelines for each editing category:
Subject Addition & Removal: Images were annotated using Florence-2 for semantic understanding, segmented with SAM-2, and processed with ObjectRemovalAlpha for inpainting
Subject Replacement & Background Change: Similar preprocessing steps were followed, but using Qwen2.5-VL and Recognize-Anything Model for target identification, with Flux-Fill for content-aware inpainting
Color Alteration & Material Modification: After object detection, Zeodepth estimated depth to understand object geometry, while ControlNet with diffusion models generated new images preserving object identity but altering appearance
Text Modification: PPOCR recognized characters, while Step-1o distinguished correct and incorrect text regions, followed by human post-processing
Motion Change: Video frames from Koala-36M were processed with optical flow estimation to identify foreground motion, with GPT-4o providing motion change annotations
Portrait Editing and Beautification: Combined public beautification pairs with human-edited examples, all manually validated
Style Transfer: Handled bidirectionally depending on target style, using edge extraction and controlled diffusion
As shown in Figure 2, the Step1X-Edit dataset substantially exceeds the scale of all existing editing datasets. Even after filtering, the high-quality subset remains comparable to other datasets in absolute magnitude.
How Step1X-Edit Works: A Multimodal Approach
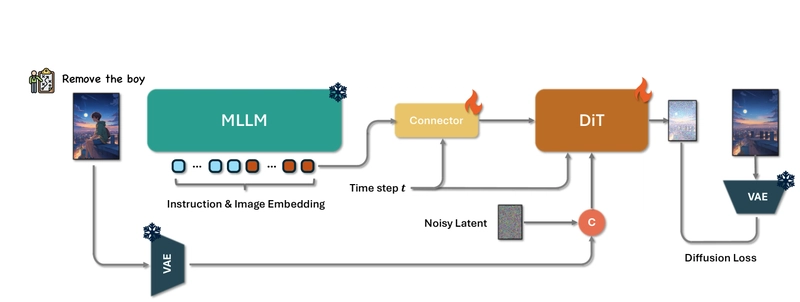
Figure 4: The Step1X-Edit framework, showing how MLLMs process instructions and generate editing tokens that are decoded into images.
Step1X-Edit integrates three key components into a unified architecture:
Multimedia Large Language Model (MLLM): The system uses Qwen-VL to process both the reference image and editing instruction in a single forward pass. This captures semantic relationships between the instruction and visual content.
Connector Module: A lightweight token refiner restructures the embeddings from the MLLM into a compact textual feature representation, replacing the text embedding normally generated by the T5 encoder in the downstream network.
Diffusion in Transformer (DiT): A FLUX-based diffusion model generates the final edited image based on the refined embeddings.
The model also calculates the mean of all output embeddings from Qwen, projects it through a linear layer, and generates a global visual guidance vector. This enhances the network's semantic comprehension capabilities, enabling more accurate and context-aware editing.
During training, both target and reference images are processed by encoding them through a VAE, with noise added to the target image to promote generalization. The resulting image tokens are concatenated to form a fused feature, creating a rich cross-modal conditioning mechanism.
The connector and DiT components are trained jointly, initialized with pretrained weights from in-house Qwen and DiT text-to-image models. This approach significantly boosts the system's ability to perform high-fidelity, semantically aligned image edits across diverse user instructions.
Evaluation and Performance Analysis
GEdit-Bench: A Real-World Evaluation Benchmark
To authentically evaluate image editing models, the researchers created GEdit-Bench, a benchmark based on real-world user editing requests. Unlike existing benchmarks that rely on synthetic or curated examples, GEdit-Bench collects genuine editing needs from platforms like Reddit.

Figure 5: The de-identification process used to protect privacy while maintaining the integrity of editing examples.
More than 1,000 user editing instances were collected and manually categorized into 11 distinct groups. After filtering for diversity, the final benchmark contained 606 testing examples using real-world images, making it uniquely representative of practical applications.
| Benchmarks | Size | Real Image | Genuine Instruction | Human Filtering | #Sub-tasks | Public Availability |
|---|---|---|---|---|---|---|
| EditBench [47] | 240 | ✓ | ✗ | ✗ | 1 | ✓ |
| EmsEdit [40] | 3,055 | ✓ | ✗ | ✗ | 7 | ✓ |
| HIVE [60] | 1,000 | ✓ | ✗ | ✓ | 1 | ✓ |
| HQ-Edit [18] | 1,640 | ✗ | ✗ | ✗ | 7 | ✓ |
| MagicBrush [57] | 1,053 | ✓ | ✗ | ✓ | 7 | ✓ |
| AnyEdit [39] | 1,250 | ✓ | ✗ | ✗ | 25 | ✓ |
| ICE-Bench [30] | 6,538 | ✓ | ✗ | ✓ | 31 | ✗ |
| GEdit-Bench(Ours) | 606 | ✓ | ✓ | ✓ | 11 | ✓ |
Table 1: Key Attributes of Open-source Edit Benchmarks. GEdit-Bench uniquely features genuine user instructions, unlike other benchmarks that rely on synthetic prompts.
To protect privacy, a comprehensive de-identification protocol was implemented. For each original image, reverse image searches identified publicly accessible alternatives with visual and semantic similarity. When alternatives couldn't be found, editing instructions were carefully modified to maintain fidelity to the original user intent while using anonymized images.
The benchmark features both English and Chinese instructions for each image, enabling evaluation across languages. This approach allows for comprehensive assessment of model capabilities in multilingual settings.
Results: Step1X-Edit vs. State-of-the-Art Systems
Using GEdit-Bench, the researchers evaluated Step1X-Edit against both open-source alternatives (OmniGen, AnyEdit, InstructPix2Pix, MagicBrush) and proprietary systems (GPT-4o, Gemini2 Flash, Doubao).
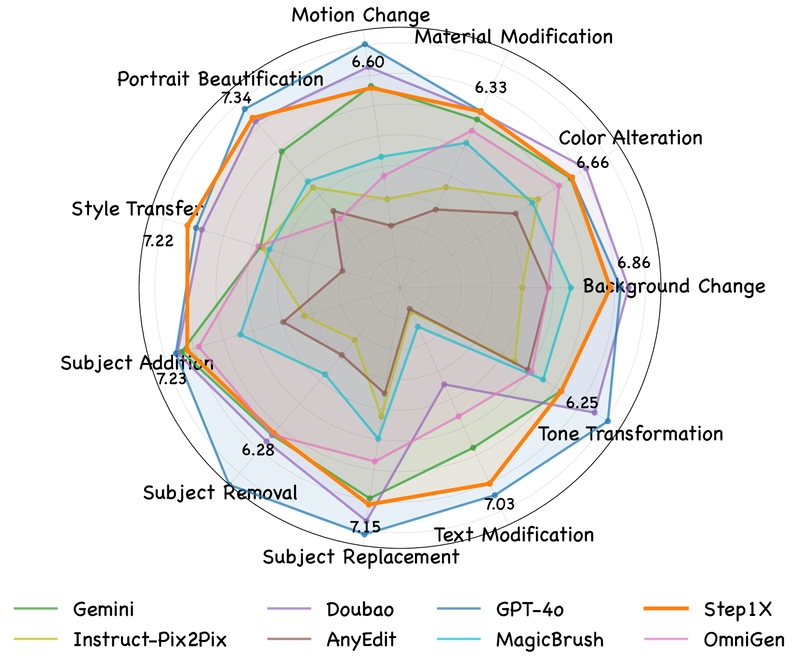
Figure 6: VIEScore results across different subtasks for the intersection subset, evaluated by GPT-4o.
Performance was assessed using VIEScore, which measures three key metrics:
- Semantic Consistency (SC): How well the edited results match the editing instruction
- Perceptual Quality (PQ): The naturalness of the image and absence of artifacts
- Overall Score (O): A combined evaluation of both aspects
The evaluation used both GPT-4.1 and Qwen2.5-VL-72B for scoring to ensure robustness. Results were reported for both an "Intersection Subset" (where all models successfully returned results) and the "Full Set" (all testing samples).
| Model | GEdit-Bench-EN (Intersection subset) ↑ | GEdit-Bench-EN (Full set) ↑ | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| G_SC | G_PQ | G_O | Q_SC | Q_PQ | Q_O | G_SC | G_PQ | G_O | Q_SC | Q_PQ | Q_O | |
| Instruct-Pix2Pix [8] | 3.473 | 5.601 | 3.631 | 4.836 | 6.948 | 4.655 | 3.575 | 5.491 | 3.684 | 4.772 | 6.870 | 4.576 |
| MagicBrush [57] | 4.646 | 5.800 | 4.578 | 5.806 | 7.162 | 5.632 | 4.677 | 5.656 | 4.518 | 5.733 | 7.066 | 5.536 |
| AnyEdit [55] | 3.177 | 5.856 | 3.231 | 3.583 | 6.751 | 3.498 | 3.178 | 5.820 | 3.212 | 3.438 | 6.729 | 3.361 |
| OmniGen [51] | 6.070 | 5.885 | 5.162 | 7.022 | 6.853 | 6.565 | 5.963 | 5.888 | 5.061 | 6.900 | 6.781 | 6.413 |
| Step1X-Edit | 7.183 | 6.818 | 6.813 | 7.380 | 7.229 | 7.161 | 7.091 | 6.763 | 6.701 | 7.332 | 7.204 | 7.104 |
| Gemini [14] | 6.697 | 6.638 | 6.322 | 7.276 | 7.306 | 6.978 | 6.732 | 6.606 | 6.315 | 7.287 | 7.315 | 6.982 |
| Doubao [41] | 7.004 | 7.215 | 6.828 | 7.417 | 7.635 | 7.273 | 6.916 | 7.188 | 6.754 | 7.382 | 7.639 | 7.241 |
| GPT-4o [29] | 7.844 | 7.592 | 7.517 | 7.873 | 7.690 | 7.694 | 7.850 | 7.620 | 7.534 | 7.826 | 7.689 | 7.646 |
Table 2: Quantitative evaluation on GEdit-Bench-EN. All metrics are higher-is-better (↑). The Intersection subset contains 434 instances where all methods returned valid responses; the Full set includes all 606 instances.
The results demonstrate Step1X-Edit's superior performance compared to existing open-source models. It significantly outperforms OmniGen, the previous state-of-the-art open-source model, and even approaches or exceeds the performance of proprietary systems like Gemini2 Flash in some metrics. While GPT-4o remains the top performer overall, Step1X-Edit effectively narrows the gap between open and closed-source solutions.
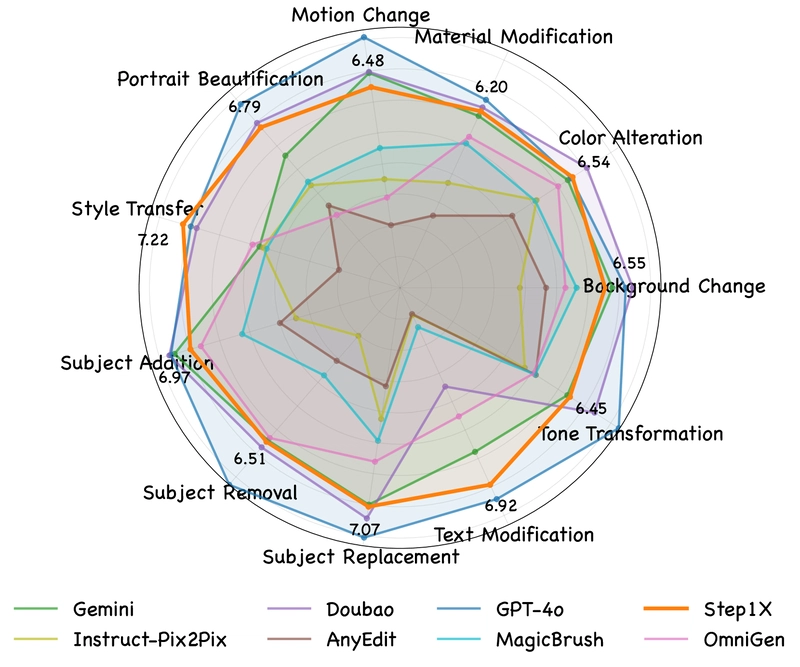
Figure 7: Visual comparison of editing results across different models for English instructions.
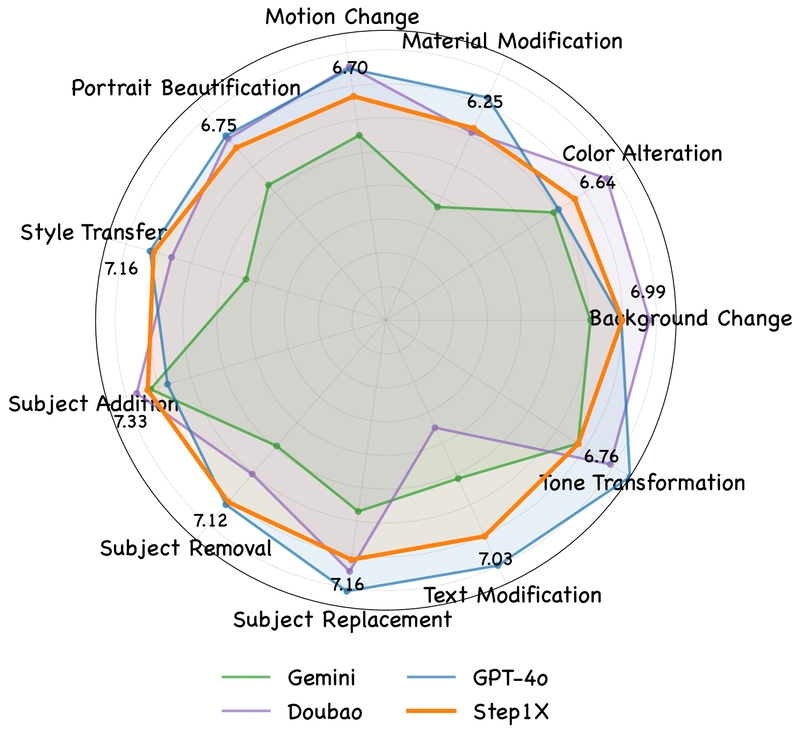
Figure 8: Visual comparison of editing results across different models for Chinese instructions.
The model also demonstrates consistent performance across languages, showing comparable results when handling Chinese editing instructions in the GEdit-Bench-CN benchmark. This multilingual capability highlights the robustness of the approach and its potential for global applications.
A user study with 55 participants further validated these findings. Participants rated editing outputs from Gemini2 Flash, Doubao, GPT-4o, and Step1X-Edit, confirming that Step1X-Edit produces visually pleasing and user-preferred edits comparable to proprietary solutions.
Advancing Open-Source Image Editing
Step1X-Edit represents a significant advancement in open-source image editing technology. By integrating powerful Multimedia Large Language Models with diffusion-based image decoders, it achieves results that substantially outperform existing open-source solutions and approach the quality of leading proprietary systems.
The data generation pipeline developed for this project establishes a new standard for creating high-quality, diverse training data for image editing. By categorizing editing tasks and implementing specialized pipelines for each category, the researchers created a dataset that exceeds the scale and quality of previous collections.
GEdit-Bench provides a valuable resource for authentic evaluation, rooted in real-world user needs rather than synthetic examples. This benchmark enables more meaningful assessment of image editing models across diverse editing scenarios.
The success of Step1X-Edit demonstrates that open-source solutions can deliver competitive performance in complex multimodal tasks. By narrowing the gap between proprietary and publicly available technologies, Step1X-Edit empowers researchers and developers to build on these foundations and accelerate innovation in image editing.
As AI-powered image editing becomes increasingly integrated into creative workflows, open-source alternatives like Step1X-Edit ensure that these capabilities remain accessible, transparent, and adaptable to diverse needs.