![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)






















































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)






















































































































_roibu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)













































































































![M4 MacBook Air Drops to Just $849 - Act Fast! [Lowest Price Ever]](https://www.iclarified.com/images/news/97140/97140/97140-640.jpg)
![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)





























































































AI Automates Code from ML Papers, Boosting Reproducibility by 44%
This is a Plain English Papers summary of a research paper called AI Automates Code from ML Papers, Boosting Reproducibility by 44%. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Bridging the Code Gap: How PaperCoder Transforms Scientific Papers into Working Code Only 21.23% of machine learning papers include their code, creating a massive reproducibility bottleneck for researchers. PaperCoder changes this with an AI framework that automatically converts research papers into fully functional code repositories. PaperCoder overview and the code availability gap in machine learning research. The Reproducibility Challenge in Machine Learning Machine learning research progresses rapidly, but corresponding code implementations frequently remain unavailable. This forces researchers to invest substantial time and effort reverse-engineering methods from papers, significantly slowing scientific innovation. Recent advances in Large Language Models (LLMs) have demonstrated impressive capabilities in code understanding and generation. Models like Llama 3, GPT-4, and Gemini show potential for accelerating scientific workflows by generating high-quality code. However, most current approaches to automating experimentation assume access to existing implementations or well-defined APIs. PaperCoder tackles a more fundamental challenge: generating complete, faithful code implementations solely from research papers without relying on prior code or additional materials. The PaperCoder Framework: A Multi-Stage Approach PaperCoder adopts a structured approach mirroring established software engineering principles. The system decomposes the complex paper-to-code transformation into three sequential stages: planning, analysis, and generation. Comparison between naive direct generation and PaperCoder's structured three-stage approach. Planning Stage: Creating the Blueprint Research papers contain substantial information not directly relevant to implementation. The planning stage distills the paper into structured components essential for code development: Overall Plan: Creates a high-level roadmap outlining core components to implement Architecture Design: Constructs class and sequence diagrams to model relationships between modules Logic Design: Identifies file dependencies and execution orders to guide correct build flows Configuration Files: Enables flexible customization of experimental workflows Analysis Stage: Extracting Implementation Details The analysis stage performs fine-grained interpretation of each file and function, determining: Required inputs and outputs Interactions with other modules Algorithmic and architectural constraints from the paper This critical stage translates the paper's technical content into structured specifications that guide the final code generation. Generation Stage: Writing the Code The final stage synthesizes the entire codebase based on the execution order determined earlier. This approach ensures: Modular code creation Proper handling of dependencies Faithful implementation of the paper's methods By separating these concerns into distinct stages, PaperCoder mirrors how expert developers would approach implementing a research paper. Experimental Validation and Results The researchers evaluated PaperCoder using two benchmark datasets: Paper2Code Benchmark: 90 papers from top ML conferences (ICML, NeurIPS, ICLR) PaperBench Code-Dev: 20 papers from ICML 2024 Evaluation methods included both model-based metrics (with and without reference code) and human evaluations by original paper authors. Comprehensive Performance Advantages PaperCoder consistently outperformed all baselines across conferences and evaluation modes: Reference-based Reference-free Statistics ICML NeurIPS ICLR ICML NeurIPS ICLR # of Tokens # of Files # of Funct ChatDEV 2.97 (0.58) 2.96 (0.69) 2.70(0.63) 4.12 (0.53) 4.01 (0.74) 4.00 (0.65) 6150.54 6.99 23.82 MetaGPT 2.75 (0.70) 2.95 (0.87) 2.48 (0.48) 3.63 (0.75) 3.59 (0.92) 3.52 (0.60) 5405.21 3.24 18.08 Abstract 2.43 (0.49) 2.35 (0.62) 2.28 (0.42) 3.01 (0.60) 2.99 (0.78) 3.03 (0.64) 3376.99 1.28 12.62 Paper 3.28 (0.67) 3.22 (0.80) 3.08 (0.66) 4.30 (0.53) 4.08 (0.84) 4.15 (0.63) 3846.33 1.79 14.84 PaperCoder 3.72 (0.54) 3.83 (0.50) 3.68 (0.52) 4.73 (0.44) 4.77 (0.38) 4.73 (0.32) 14343.38 6.97 35.22 Oracle - - - 4.80 (0.32) 4.83 (0.38) 4.84 (0.26) 32149.04 28.00 122.03 Table 1: Results on the Paper2Code benchmark showing PaperCoder's superior performance across all metrics. While ChatDev generated a comparable number of files (6.99 vs. 6.97), PaperCoder produced significantly more functions (35.22 vs. 23.82), indicating higher granularity and completeness in the generated repositories. The reference-based and reference-free evaluations showed strong correlation (r=0.79), suggesting th

This is a Plain English Papers summary of a research paper called AI Automates Code from ML Papers, Boosting Reproducibility by 44%. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Bridging the Code Gap: How PaperCoder Transforms Scientific Papers into Working Code
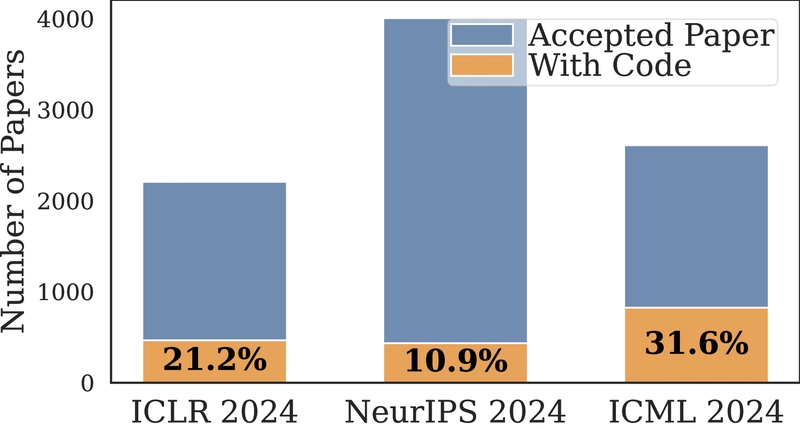
Only 21.23% of machine learning papers include their code, creating a massive reproducibility bottleneck for researchers. PaperCoder changes this with an AI framework that automatically converts research papers into fully functional code repositories.
PaperCoder overview and the code availability gap in machine learning research.
The Reproducibility Challenge in Machine Learning
Machine learning research progresses rapidly, but corresponding code implementations frequently remain unavailable. This forces researchers to invest substantial time and effort reverse-engineering methods from papers, significantly slowing scientific innovation.
Recent advances in Large Language Models (LLMs) have demonstrated impressive capabilities in code understanding and generation. Models like Llama 3, GPT-4, and Gemini show potential for accelerating scientific workflows by generating high-quality code. However, most current approaches to automating experimentation assume access to existing implementations or well-defined APIs.
PaperCoder tackles a more fundamental challenge: generating complete, faithful code implementations solely from research papers without relying on prior code or additional materials.
The PaperCoder Framework: A Multi-Stage Approach
PaperCoder adopts a structured approach mirroring established software engineering principles. The system decomposes the complex paper-to-code transformation into three sequential stages: planning, analysis, and generation.
Comparison between naive direct generation and PaperCoder's structured three-stage approach.
Planning Stage: Creating the Blueprint
Research papers contain substantial information not directly relevant to implementation. The planning stage distills the paper into structured components essential for code development:
- Overall Plan: Creates a high-level roadmap outlining core components to implement
- Architecture Design: Constructs class and sequence diagrams to model relationships between modules
- Logic Design: Identifies file dependencies and execution orders to guide correct build flows
- Configuration Files: Enables flexible customization of experimental workflows
Analysis Stage: Extracting Implementation Details
The analysis stage performs fine-grained interpretation of each file and function, determining:
- Required inputs and outputs
- Interactions with other modules
- Algorithmic and architectural constraints from the paper
This critical stage translates the paper's technical content into structured specifications that guide the final code generation.
Generation Stage: Writing the Code
The final stage synthesizes the entire codebase based on the execution order determined earlier. This approach ensures:
- Modular code creation
- Proper handling of dependencies
- Faithful implementation of the paper's methods
By separating these concerns into distinct stages, PaperCoder mirrors how expert developers would approach implementing a research paper.
Experimental Validation and Results
The researchers evaluated PaperCoder using two benchmark datasets:
- Paper2Code Benchmark: 90 papers from top ML conferences (ICML, NeurIPS, ICLR)
- PaperBench Code-Dev: 20 papers from ICML 2024
Evaluation methods included both model-based metrics (with and without reference code) and human evaluations by original paper authors.
Comprehensive Performance Advantages
PaperCoder consistently outperformed all baselines across conferences and evaluation modes:
| Reference-based | Reference-free | Statistics | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ICML | NeurIPS | ICLR | ICML | NeurIPS | ICLR | # of Tokens | # of Files | # of Funct | |
| ChatDEV | 2.97 (0.58) | 2.96 (0.69) | 2.70(0.63) | 4.12 (0.53) | 4.01 (0.74) | 4.00 (0.65) | 6150.54 | 6.99 | 23.82 |
| MetaGPT | 2.75 (0.70) | 2.95 (0.87) | 2.48 (0.48) | 3.63 (0.75) | 3.59 (0.92) | 3.52 (0.60) | 5405.21 | 3.24 | 18.08 |
| Abstract | 2.43 (0.49) | 2.35 (0.62) | 2.28 (0.42) | 3.01 (0.60) | 2.99 (0.78) | 3.03 (0.64) | 3376.99 | 1.28 | 12.62 |
| Paper | 3.28 (0.67) | 3.22 (0.80) | 3.08 (0.66) | 4.30 (0.53) | 4.08 (0.84) | 4.15 (0.63) | 3846.33 | 1.79 | 14.84 |
| PaperCoder | 3.72 (0.54) | 3.83 (0.50) | 3.68 (0.52) | 4.73 (0.44) | 4.77 (0.38) | 4.73 (0.32) | 14343.38 | 6.97 | 35.22 |
| Oracle | - | - | - | 4.80 (0.32) | 4.83 (0.38) | 4.84 (0.26) | 32149.04 | 28.00 | 122.03 |
Table 1: Results on the Paper2Code benchmark showing PaperCoder's superior performance across all metrics.
While ChatDev generated a comparable number of files (6.99 vs. 6.97), PaperCoder produced significantly more functions (35.22 vs. 23.82), indicating higher granularity and completeness in the generated repositories.
The reference-based and reference-free evaluations showed strong correlation (r=0.79), suggesting that the method works reliably even without access to ground-truth implementations.
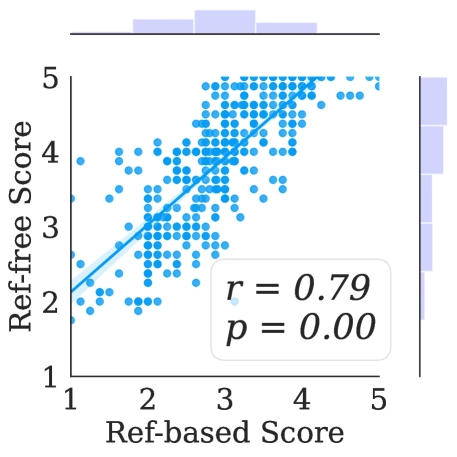
Strong correlation between reference-based and reference-free evaluation metrics, enabling reliable assessment even without access to official code.
PaperBench Results: Dramatic Improvement
On the PaperBench Code-Dev benchmark, PaperCoder achieved a 44.26% replication score, dramatically outperforming the BasicAgent (5.1%) and IterativeAgent (16.4%).
| Model | Replication scores (%) |
|---|---|
| BasicAgent | $5.1 \pm 0.8$ |
| IterativeAgent | $16.4 \pm 1.4$ |
| PaperCoder | $\mathbf{44.26}$ |
Table 2: PaperCoder's performance on the PaperBench Code-Dev benchmark showing substantial improvement over baseline agents.
Human Validation by Paper Authors
Human evaluations by original paper authors confirmed PaperCoder's superior performance. The system consistently ranked first across different comparison groups:
| Score $(\uparrow)$ | Ranking $(\downarrow)$ | |||||
|---|---|---|---|---|---|---|
| Ref-based | Ref-free | Human | Ref-based | Ref-free | Human | |
| Abstract | $2.36(0.34)$ | $2.99(0.53)$ | $1.62(1.26)$ | $3.00(0.00)$ | $3.00(0.00)$ | $2.69(0.63)$ |
| Paper | $3.19(0.44)$ | $4.22(0.52)$ | $3.15(1.28)$ | $1.86(0.36)$ | $1.79(0.43)$ | $1.92(0.64)$ |
| PaperCoder (Ours) | $\mathbf{3 . 7 4}(0.30)$ | $\mathbf{4 . 7 1}(0.27)$ | $\mathbf{4 . 2 3}(1.30)$ | $\mathbf{1 . 1 4}(0.36)$ | $\mathbf{1 . 0 7}(0.27)$ | $\mathbf{1 . 3 8}(0.65)$ |
| ChatDev | $2.67(0.63)$ | $3.87(0.36)$ | $2.69(1.11)$ | $2.50(0.52)$ | $2.36(0.50)$ | $2.15(0.55)$ |
| MetaGPT | $2.65(0.46)$ | $3.38(0.66)$ | $1.77(1.30)$ | $2.07(0.52)$ | $2.14(0.52)$ | $2.61(0.65)$ |
| PaperCoder (Ours) | $\mathbf{3 . 7 4}(0.30)$ | $\mathbf{4 . 7 1}(0.27)$ | $\mathbf{4 . 5 4}(1.20)$ | $\mathbf{1 . 0 0}(0.00)$ | $\mathbf{1 . 0 0}(0.00)$ | $\mathbf{1 . 2 3}(0.60)$ |
Table 3: Human evaluation results confirming PaperCoder's superior performance across all metrics.
The researchers also evaluated different LLM backbones for PaperCoder:
| DS-Coder | Qwen-Coder | DS-Distill-Qwen | o3-mini-high | ||
|---|---|---|---|---|---|
| Score $(\uparrow)$ | Ref-based | $1.63(0.43)$ | $1.8(0.28)$ | $2.07(0.30)$ | $\mathbf{3 . 7 4}(0.30)$ |
| Ref-free | $1.82(0.39)$ | $2.1(0.28)$ | $2.29(0.29)$ | $\mathbf{4 . 7 1}(0.27)$ | |
| Human | $1.41(0.64)$ | $2.74(1.14)$ | $3.05(1.04)$ | $\mathbf{4 . 7 9}(0.74)$ | |
| Ranking $(\downarrow)$ | Ref-based | $3.36(0.93)$ | $2.93(0.62)$ | $2.36(0.63)$ | $\mathbf{1 . 0 0}(0.00)$ |
| Ref-free | $3.36(0.84)$ | $2.86(0.66)$ | $2.14(0.36)$ | $\mathbf{1 . 0 0}(0.00)$ | |
| Human | $3.69(0.48)$ | $2.69(0.85)$ | $2.46(0.78)$ | $\mathbf{1 . 1 5}(0.55)$ |
Table 4: Performance comparison of different model backbones showing o3-mini-high's superior results.
Practical Executability
The system produced code that required minimal modification to run correctly:
| Repo Name | CoLoR | cognitive-behaviors | RADA | Self-Instruct | G-EVAL | Average |
|---|---|---|---|---|---|---|
| Modified lines | 2 | 1 | 1 | 25 | 10 | 6.5 |
| Total lines | 1132 | 2060 | 1609 | 1334 | 1374 | 1251.5 |
| Percentage | 0.18 | 0.05 | 0.06 | 1.87 | 0.73 | 0.48 |
Table 7: Executability results showing minimal modifications needed to run the generated code.
Why PaperCoder Performs Better
Human evaluators identified several key strengths in PaperCoder's output:
| Completeness | Clean Structure | Faithfulness to Paper | Ease of Use | Code Quality | Unique Strengths |
|---|---|---|---|---|---|
| 8 | 6 | 5 | 4 | 2 | 3 |
Table 8: Qualitative analysis showing the main reasons human experts preferred PaperCoder repositories.
The most frequently cited advantages were completeness of implementation, clean code structure, and faithfulness to the original paper.
Implications for Scientific Progress
PaperCoder represents a significant step forward in bridging the gap between research publications and executable code. By automating the labor-intensive process of implementing methods from papers, it can:
- Accelerate research cycles by enabling faster validation and extension of prior work
- Democratize access to cutting-edge methods, especially for researchers with limited resources
- Improve reproducibility in machine learning by creating consistent, high-quality implementations
- Enable easier comparative experimentation across multiple research papers
While there remains a gap between automated implementations and author-released code, PaperCoder demonstrates that structured, multi-agent approaches can produce high-quality repositories that significantly reduce implementation effort.
As LLMs continue to improve in reasoning and code generation capabilities, systems like PaperCoder will become increasingly valuable tools for maintaining the pace of scientific innovation in the face of ever-growing research output.