















































.jpg)



















































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)

















































































































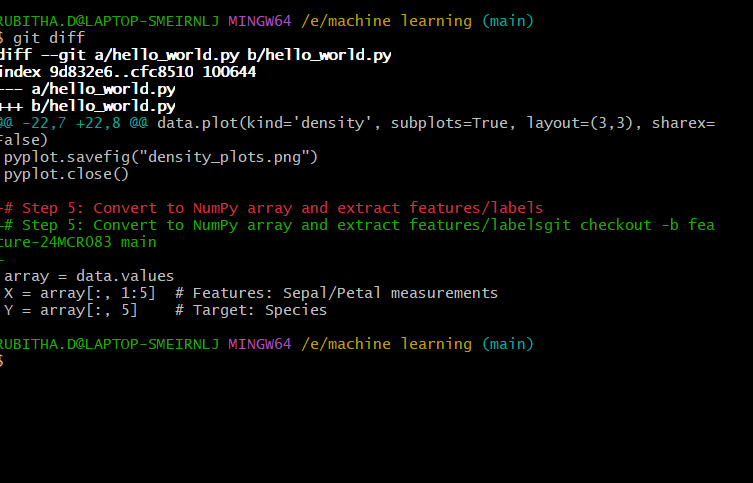

































































































































-RTAガチ勢がSwitch2体験会でゼルダのラスボスを撃破して世界初のEDを流してしまう...【ゼルダの伝説ブレスオブザワイルドSwitch2-Edition】-00-06-05.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)


























_roibu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


.webp?#)








































































































![M4 MacBook Air Drops to Just $849 - Act Fast! [Lowest Price Ever]](https://www.iclarified.com/images/news/97140/97140/97140-640.jpg)
![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)






























































































Skywork R1V2: Hybrid RL Achieves New Multimodal Reasoning Records
This is a Plain English Papers summary of a research paper called Skywork R1V2: Hybrid RL Achieves New Multimodal Reasoning Records. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Balancing Reasoning with Broad Generalization Multimodal AI models have made significant progress in complex reasoning tasks, but maintaining balance between specialized reasoning capabilities and general-purpose understanding remains challenging. While "slow-thinking" models like OpenAI-o1 excel at mathematical and scientific reasoning, they often struggle with everyday visual tasks. Conversely, general-purpose models typically underperform on complex analytical reasoning. Skywork R1V2 addresses this fundamental challenge through a hybrid reinforcement learning approach that harmonizes reward-model guidance with rule-based strategies. The model introduces key innovations including a Selective Sample Buffer (SSB) mechanism that counters the "Vanishing Advantages" dilemma in reinforcement learning, and a calibrated reward threshold system that mitigates visual hallucinations. Extensive evaluations demonstrate R1V2's exceptional performance across multiple benchmarks: 62.6% on OlympiadBench, 79.0% on AIME2024, 63.6% on LiveCodeBench, and 74.0% on MMMU. These results establish new standards for open-source multimodal reasoning models while significantly closing the performance gap with proprietary systems like Gemini 2.5 and OpenAI o4-mini. Evolution of Multimodal Reasoning Approaches Multimodal Reasoning Models Current approaches to multimodal reasoning fall into three main categories: Distillation-based approaches like Claude-3, GPT-4V, and Gemini leverage larger text-only reasoning models to transfer abilities to multimodal contexts through teacher-student frameworks. While effective, this approach relies heavily on large proprietary text models, limiting accessibility for open research. Reinforcement learning techniques employed by models like Qwen-VL, SPHINX, and LLaVA apply methods such as RLHF, DPO, and other preference optimization strategies to align outputs with human preferences. However, most implementations focus on general instruction following rather than specialized reasoning capabilities. Architectural innovations include "slow-thinking" approaches like OpenAI-o1, Gemini-Thinking, and Kimi-1.5, which introduce specialized mechanisms for extended deliberation. The first generation Skywork-R1V pioneered the direct application of text reasoning capabilities to vision through advanced adapter techniques. A common challenge across these approaches is achieving balance between specialized reasoning abilities and general multimodal understanding. Models optimized for mathematical reasoning often show degraded performance on everyday visual tasks, while general-purpose models struggle with complex analytical reasoning. Preference Optimization in Multimodal Models Preference optimization has transformed text-based models through techniques like RLHF and DPO, but extending these methods to multimodal reasoning presents significant challenges. Early multimodal preference work focused primarily on basic instruction following, with models like BLIP-2 and InstructBLIP pioneering instruction tuning for vision-language alignment. Two critical limitations hinder progress in applying preference optimization to complex multimodal reasoning: The binary nature of typical preference pairs fails to capture the nuanced progression of complex reasoning paths, where multiple equally valid solutions may exist with different intermediate steps. Existing reward models predominantly evaluate textual quality in isolation, overlooking the crucial relationship between visual interpretation and logical inference. Skywork R1V2 addresses these limitations through a hybrid optimization framework that integrates preference-based signals with structured rule-based reinforcement, providing more granular guidance for reasoning processes while maintaining general-purpose capabilities across diverse tasks. Skywork R1V2: A New Hybrid Reinforcement Learning Approach Efficient Multimodal Transfer via Modular Reassembly R1V2 employs a modular architecture that decouples visual-language alignment from the preservation of reasoning capabilities. The approach uses a lightweight multilayer perceptron (MLP) adapter to connect a frozen vision encoder (Intern ViT-6B) with a reasoning-capable language model (e.g., qwq-32B). Unlike its predecessor, R1V2 omits the supervised fine-tuning stage. Empirical evidence shows that while supervised fine-tuning improves visual-language alignment, it significantly impairs the original reasoning ability of the language model. Instead, directly combining the pretrained language model with the visual adapter preserves reasoning ability with only a slight reduction in general visual understanding. This modular ap
This is a Plain English Papers summary of a research paper called Skywork R1V2: Hybrid RL Achieves New Multimodal Reasoning Records. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Balancing Reasoning with Broad Generalization
Multimodal AI models have made significant progress in complex reasoning tasks, but maintaining balance between specialized reasoning capabilities and general-purpose understanding remains challenging. While "slow-thinking" models like OpenAI-o1 excel at mathematical and scientific reasoning, they often struggle with everyday visual tasks. Conversely, general-purpose models typically underperform on complex analytical reasoning.
Skywork R1V2 addresses this fundamental challenge through a hybrid reinforcement learning approach that harmonizes reward-model guidance with rule-based strategies. The model introduces key innovations including a Selective Sample Buffer (SSB) mechanism that counters the "Vanishing Advantages" dilemma in reinforcement learning, and a calibrated reward threshold system that mitigates visual hallucinations.
Extensive evaluations demonstrate R1V2's exceptional performance across multiple benchmarks: 62.6% on OlympiadBench, 79.0% on AIME2024, 63.6% on LiveCodeBench, and 74.0% on MMMU. These results establish new standards for open-source multimodal reasoning models while significantly closing the performance gap with proprietary systems like Gemini 2.5 and OpenAI o4-mini.
Evolution of Multimodal Reasoning Approaches
Multimodal Reasoning Models
Current approaches to multimodal reasoning fall into three main categories:
Distillation-based approaches like Claude-3, GPT-4V, and Gemini leverage larger text-only reasoning models to transfer abilities to multimodal contexts through teacher-student frameworks. While effective, this approach relies heavily on large proprietary text models, limiting accessibility for open research.
Reinforcement learning techniques employed by models like Qwen-VL, SPHINX, and LLaVA apply methods such as RLHF, DPO, and other preference optimization strategies to align outputs with human preferences. However, most implementations focus on general instruction following rather than specialized reasoning capabilities.
Architectural innovations include "slow-thinking" approaches like OpenAI-o1, Gemini-Thinking, and Kimi-1.5, which introduce specialized mechanisms for extended deliberation. The first generation Skywork-R1V pioneered the direct application of text reasoning capabilities to vision through advanced adapter techniques.
A common challenge across these approaches is achieving balance between specialized reasoning abilities and general multimodal understanding. Models optimized for mathematical reasoning often show degraded performance on everyday visual tasks, while general-purpose models struggle with complex analytical reasoning.
Preference Optimization in Multimodal Models
Preference optimization has transformed text-based models through techniques like RLHF and DPO, but extending these methods to multimodal reasoning presents significant challenges. Early multimodal preference work focused primarily on basic instruction following, with models like BLIP-2 and InstructBLIP pioneering instruction tuning for vision-language alignment.
Two critical limitations hinder progress in applying preference optimization to complex multimodal reasoning:
The binary nature of typical preference pairs fails to capture the nuanced progression of complex reasoning paths, where multiple equally valid solutions may exist with different intermediate steps.
Existing reward models predominantly evaluate textual quality in isolation, overlooking the crucial relationship between visual interpretation and logical inference.
Skywork R1V2 addresses these limitations through a hybrid optimization framework that integrates preference-based signals with structured rule-based reinforcement, providing more granular guidance for reasoning processes while maintaining general-purpose capabilities across diverse tasks.
Skywork R1V2: A New Hybrid Reinforcement Learning Approach
Efficient Multimodal Transfer via Modular Reassembly
R1V2 employs a modular architecture that decouples visual-language alignment from the preservation of reasoning capabilities. The approach uses a lightweight multilayer perceptron (MLP) adapter to connect a frozen vision encoder (Intern ViT-6B) with a reasoning-capable language model (e.g., qwq-32B).
Unlike its predecessor, R1V2 omits the supervised fine-tuning stage. Empirical evidence shows that while supervised fine-tuning improves visual-language alignment, it significantly impairs the original reasoning ability of the language model. Instead, directly combining the pretrained language model with the visual adapter preserves reasoning ability with only a slight reduction in general visual understanding.
This modular approach reduces computational requirements and enables targeted optimization of cross-modal alignment without disrupting pre-established reasoning capabilities. Notably, capabilities in text and vision exhibit high transferability—improvements in one modality directly benefit the other. While training the vision encoder alone yields limited gains, both adapter-only training and joint LLM+adapter training prove highly effective, suggesting that cross-modal alignment rather than visual encoding represents the critical bottleneck in multimodal reasoning.
Hybrid Optimization with GRPO and MPO
To balance reasoning and generalization, R1V2 employs two core reinforcement learning strategies:
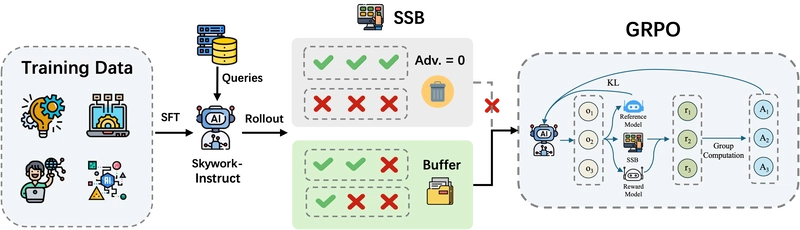
Group Relative Policy Optimization (GRPO) guides the model via intra-group reward comparisons between candidate responses. However, this approach faces the "vanishing advantage" problem—when responses in a group converge to be uniformly correct or incorrect, the relative advantage signal diminishes to near-zero. To address this, R1V2 introduces a Selective Sample Buffer (SSB) that stores and reuses high-value training samples with non-zero advantages.
Mixed Preference Optimization (MPO) integrates preference signals from the R1V-RM reward model with hand-crafted rule-based constraints (e.g., format correctness, factual consistency, step-by-step reasoning completeness). This hybrid reward structure better aligns outputs with both stylistic preferences and factual requirements across modalities.
The combination of GRPO and MPO significantly enhances the model's reasoning and format compliance. After DPO-based fine-tuning, outputs become more stable and coherent, with fewer crashes, while retaining reasonable generalization. The approach prioritizes improvements on reasoning benchmarks while acknowledging the inherent trade-off between reasoning and general-purpose performance.
Selective Sample Buffer (SSB) for Addressing Vanishing Advantages
The "vanishing advantages" problem occurs when all responses within a query group converge to become uniformly correct or incorrect, causing relative advantage signals to diminish and hindering effective gradient-based policy updates.
The Selective Sample Buffer (SSB) mechanism addresses the vanishing advantages problem by preserving and prioritizing high-value samples with non-zero advantages.
To address this issue, the Selective Sample Buffer (SSB) identifies and caches high-quality training examples with non-zero advantages from previous iterations. The approach prioritizes samples based on the absolute value of their advantage signals through weighted sampling, strategically reintroducing these informative samples during policy updates to maintain a gradient-rich training environment.
Empirically, the percentage of effective samples (those with non-zero advantages) decreases dramatically from approximately 60% at the beginning of training to below 10% in later stages, severely impacting training efficiency. The SSB mechanism counteracts this trend by ensuring a consistent supply of informative training signals.
The researchers also observed that while visual reasoning and textual reasoning capabilities show complementary patterns during training, excessive emphasis on visual reasoning can lead to increased hallucination. The SSB helps maintain an appropriate balance between these modalities by preserving diverse learning signals across both domains.
Comprehensive Evaluation and Analysis
Experimental Setup
R1V2 was evaluated on multiple benchmark categories:
Text Reasoning Benchmarks:
- AIME 2024: American Invitational Mathematics Examination problems requiring advanced mathematical competencies
- LiveCodebench: Evaluation framework for coding capabilities across multiple programming languages
- LiveBench: Dynamic reasoning benchmark for everyday reasoning tasks
- IFEVAL: Benchmark for conditional reasoning in large language models
- BFCL: Benchmark for Faithful Chain-of-thought Language reasoning
Multimodal Reasoning Benchmarks:
- MMMU: Massive Multi-discipline Multimodal Understanding benchmark across 30 academic disciplines
- MathVista: Benchmark for mathematical reasoning in visual contexts
- OlympiadBench: Challenging problems adapted from international science and mathematics olympiads
- MathVision: Specialized benchmark focusing on geometric reasoning and spatial understanding
- MMMU-Pro: Extended version of MMMU with more challenging problems
The evaluation used a maximum generation length of 64K tokens and employed a unified evaluation framework using LLM Judge (OpenAI-o4). Performance was measured using the Pass@1 score, averaged across 5 independent runs.
Main Results
Text Reasoning Performance:
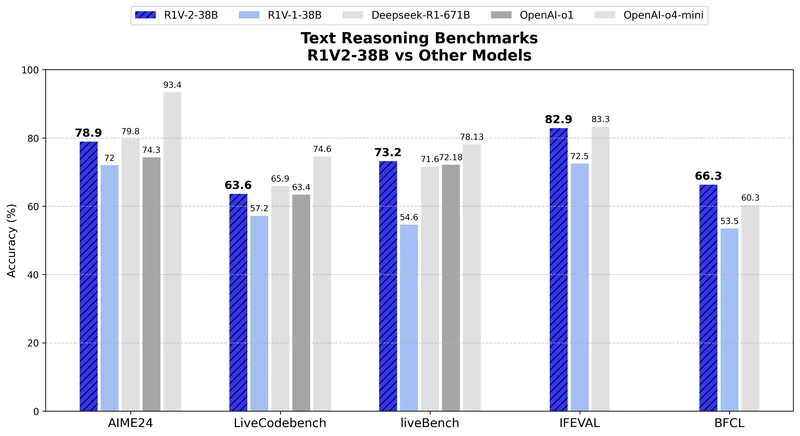
Performance comparison on text reasoning benchmarks.
Skywork R1V2 achieves exceptional reasoning capabilities: 78.9% on AIME24, 63.6% on LiveCodebench, 73.2% on LiveBench, 82.9% on IFEVAL, and 66.3% on BFCL. The model significantly outperforms its predecessor R1V1, with improvements of 6.9 percentage points on AIME24, 6.4 points on LiveCodebench, 18.6 points on LiveBench, 10.4 points on IFEVAL, and 12.8 points on BFCL.
When compared to larger models like Deepseek R1 (671B parameters), R1V2 (38B parameters) achieves competitive results, even outperforming it on LiveBench (73.2% vs. 71.6%) and BFCL (66.3% vs. 60.3%).
Multimodal Reasoning Performance:
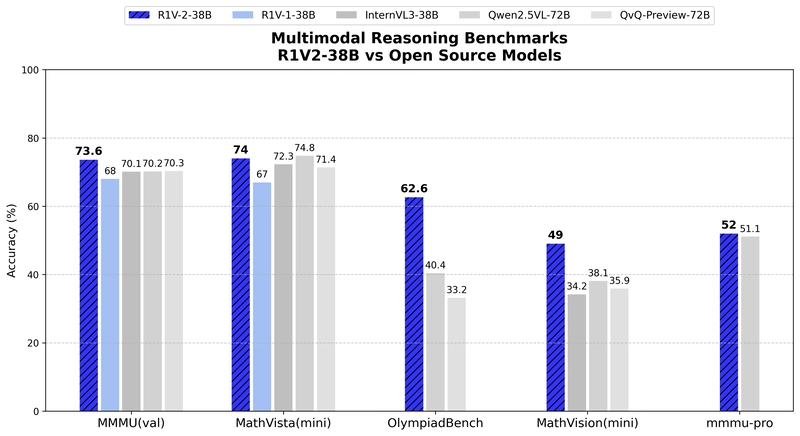
Comparison with open-source models on multimodal reasoning benchmarks.
R1V2 achieves state-of-the-art results among open-source models of similar parameter scale: 73.6% on MMMU, 74.0% on MathVista, 62.6% on OlympiadBench, 49.0% on MathVision, and 52.0% on MMMU-Pro. The improvement over R1V1 is substantial, with a 5.6 percentage point increase on MMMU and a 7.0 point increase on MathVista.
R1V2 outperforms even larger models such as Qwen2.5-VL-72B (70.2% vs. 73.6% on MMMU) and QvQ-Preview-72B (70.3% vs. 73.6% on MMMU). Particularly noteworthy is R1V2's exceptional performance on OlympiadBench (62.6%), substantially outperforming larger models like Qwen2.5-VL-72B (40.4%) and QvQ-Preview-72B (33.2%).
Comparison with Proprietary Models:
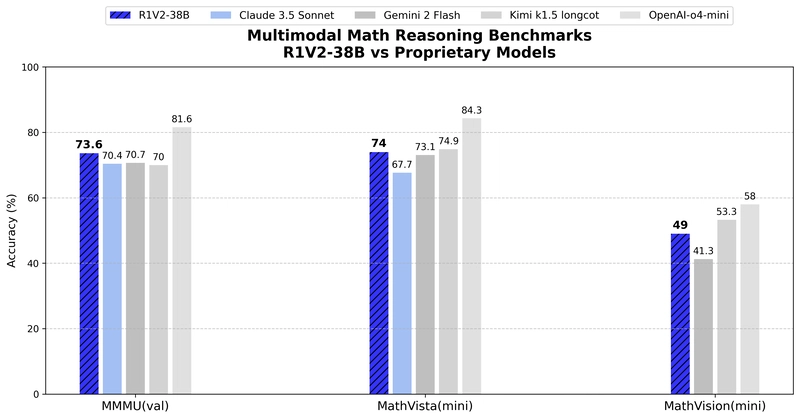
Comparison with proprietary models on multimodal reasoning benchmarks.
Despite having significantly fewer parameters, R1V2 demonstrates competitive or superior performance against several commercial models. On MMMU, R1V2 (73.6%) outperforms Claude 3.5 Sonnet (70.4%), Gemini 2 Flash (70.7%), and Kimi k1.5 longcot (70.0%). Similarly, on MathVista, R1V2's score of 74.0% surpasses Claude 3.5 Sonnet (67.7%) and is competitive with Gemini 2 Flash (73.1%).
While larger proprietary models like OpenAI-o4-mini still maintain an advantage, the gap has significantly narrowed compared to previous open-source efforts.
| Model | MMMU | Math- Vista |
Olympiad Bench |
AIME 24 |
LiveCode bench |
live Bench |
IFEVAL |
|---|---|---|---|---|---|---|---|
| Open-Source Models | |||||||
| Skywork-R1V2 (Ours) | $\mathbf{7 3 . 6}$ | $\mathbf{7 4 . 0}$ | $\mathbf{6 2 . 6}$ | $\mathbf{7 8 . 9}$ | $\mathbf{6 3 . 6}$ | $\mathbf{7 3 . 2}$ | $\mathbf{8 2 . 9}$ |
| Skywork-R1V1 | 68.0 | 67.0 | - | 72.0 | 57.2 | 54.6 | 72.5 |
| DeepseekR1-671B | - | - | - | 79.8 | 65.9 | 71.6 | 83.3 |
| InternVL3-38B | 70.1 | 72.3 | - | - | - | - | - |
| Qwen2.5-VL-72B | 70.2 | 74.8 | 40.4 | - | - | - | - |
| QvQ-Preview-72B | 70.3 | 71.4 | 33.2 | - | - | - | - |
| Proprietary Models | |||||||
| Claude-3.5-Sonnet | 70.4 | 67.7 | - | - | - | - | - |
| Gemini-2-Flash | 70.7 | 73.1 | - | - | - | - | - |
| Kimi-k1.5-longcot | 70.0 | 74.9 | - | - | - | - | - |
| OpenAI-o1 | - | - | - | 74.3 | 63.4 | 72.18 | - |
| OpenAI-o4-mini | 81.6 | 84.3 | - | 93.4 | 74.6 | 78.13 | - |
Table 1: Comprehensive performance comparison across text and multimodal reasoning benchmarks.
Qualitative Analysis

Reasoning Capability of Skywork-R1V2 on Chinese Gaokao Physical Problems.
R1V2 demonstrates sophisticated physics reasoning capabilities through its analysis of electromagnetic problems. When presented with a diagram showing two coils with different numbers of turns positioned perpendicular to each other, the model methodically evaluates each option by applying fundamental electromagnetic principles, correctly identifying that the frequency of induced alternating current depends on the rotational speed of the magnetic core rather than the number of turns.

Reasoning Capability of Skywork-R1V2 on Chinese Gaokao Mathematical Problems.
For mathematical reasoning, R1V2 tackles a complex 3D geometry problem from the Chinese Gaokao by developing a structured solution approach. The model strategically establishes a coordinate system, positions the sphere's center at the origin and the base in the xy-plane, then accurately applies volume formulas. Particularly noteworthy is R1V2's self-verification behavior, where it explicitly checks its steps before confirming its answer.
Ablation Studies
Effect of Selective Sample Buffer (SSB)
| Method | Effective Samples | MMMU | MathVista |
|---|---|---|---|
| Full GRPO w/o SSB | $<40 \%$ | 73.4 | 74.0 |
| GRPO w/ SSB $(10 \%)$ | $>60 \%$ | 73.6 | 74.0 |
Table 2: Ablation study on the effect of Selective Sample Buffer (SSB).
Without SSB, the percentage of effective training samples (those with non-zero advantages) decreases substantially during training, limiting gradient signals for policy updates. With SSB, a consistently high proportion of informative samples is maintained throughout training, leading to more stable optimization dynamics and better final performance. The proportion of effective samples remained above 60% with SSB, compared to below 40% without it.
MPO vs. DPO vs. SFT
| Method | Hallucination Rate |
MMMU | MathVista | Olympiad Bench |
AIME 2024 |
|---|---|---|---|---|---|
| MPO | $\mathbf{8 . 7 \%}$ | $\mathbf{7 3 . 2}$ | $\mathbf{7 3 . 5}$ | $\mathbf{6 0 . 6}$ | $\mathbf{7 9 . 0}$ |
| MPO+GRPO (Ours) | $\mathbf{9 . 1 \%}$ | $\mathbf{7 3 . 6}$ | $\mathbf{7 4 . 0}$ | $\mathbf{6 2 . 6}$ | $\mathbf{7 9 . 2}$ |
Table 3: Comparison of different optimization strategies.
Mixed Preference Optimization (MPO) consistently outperformed both Direct Preference Optimization (DPO) and Supervised Fine-Tuning (SFT) across all metrics, with particularly notable improvements on reasoning-intensive tasks. The hallucination rate using MPO was substantially lower (8.7%) compared to both DPO (12.6%) and SFT (18.4%), indicating that the hybrid optimization approach effectively balances reasoning capability enhancement with factual accuracy.
Component Activation Analysis
| Configuration | MMMU | MathVista | OlympiadBench |
|---|---|---|---|
| LLM + Adapter | 72.1 | 72.0 | 60.8 |
| Adapter + Vision encoder | 72.3 | 71.8 | 60.2 |
| Adapter only | $\mathbf{7 3 . 6}$ | $\mathbf{7 4 . 0}$ | $\mathbf{6 2 . 6}$ |
Table 4: Performance with different component activation configurations.
Adapter-only training delivered the best results across all benchmarks, while LLM + adapter and adapter + vision encoder configurations yielded lower performance. Surprisingly, activating the vision encoder during training provided minimal additional benefits compared to adapter-only training, suggesting that the primary gains come from improving the alignment between visual features and language processing rather than enhancing the visual encoding itself.
Advancing Open-Source Multimodal Reasoning
Skywork R1V2 represents a significant advance in multimodal reasoning through its hybrid reinforcement learning approach. The model addresses the fundamental challenge of balancing specialized reasoning capabilities with broad generalization through key innovations:
- A hybrid reinforcement learning paradigm that combines reward-model guidance with rule-based strategies
- The Selective Sample Buffer (SSB) mechanism that counters the "Vanishing Advantages" dilemma
- Mixed Preference Optimization (MPO) that integrates preference-based and rule-based reinforcement signals
R1V2 establishes new open-source baselines with exceptional performance across multiple benchmarks: 62.6% on OlympiadBench, 78.9% on AIME2024, 63.6% on LiveCodeBench, and 73.6% on MMMU. These results not only outperform existing open-source models but also substantially reduce the gap with proprietary state-of-the-art systems.
An important finding from this research is the trade-off between reasoning capability and visual hallucination. Excessive reinforcement signals can induce visual hallucinations—a phenomenon that requires careful monitoring and mitigation through calibrated reward thresholds throughout the training process.
The Skywork R1V2 model weights have been publicly released to promote openness and reproducibility, providing a valuable resource for researchers and practitioners working on multimodal reasoning systems.


