


































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)
























































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)























































































































_roibu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




 CISO’s Core Focus.webp?#)





































































































![M4 MacBook Air Drops to Just $849 - Act Fast! [Lowest Price Ever]](https://www.iclarified.com/images/news/97140/97140/97140-640.jpg)
![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)
















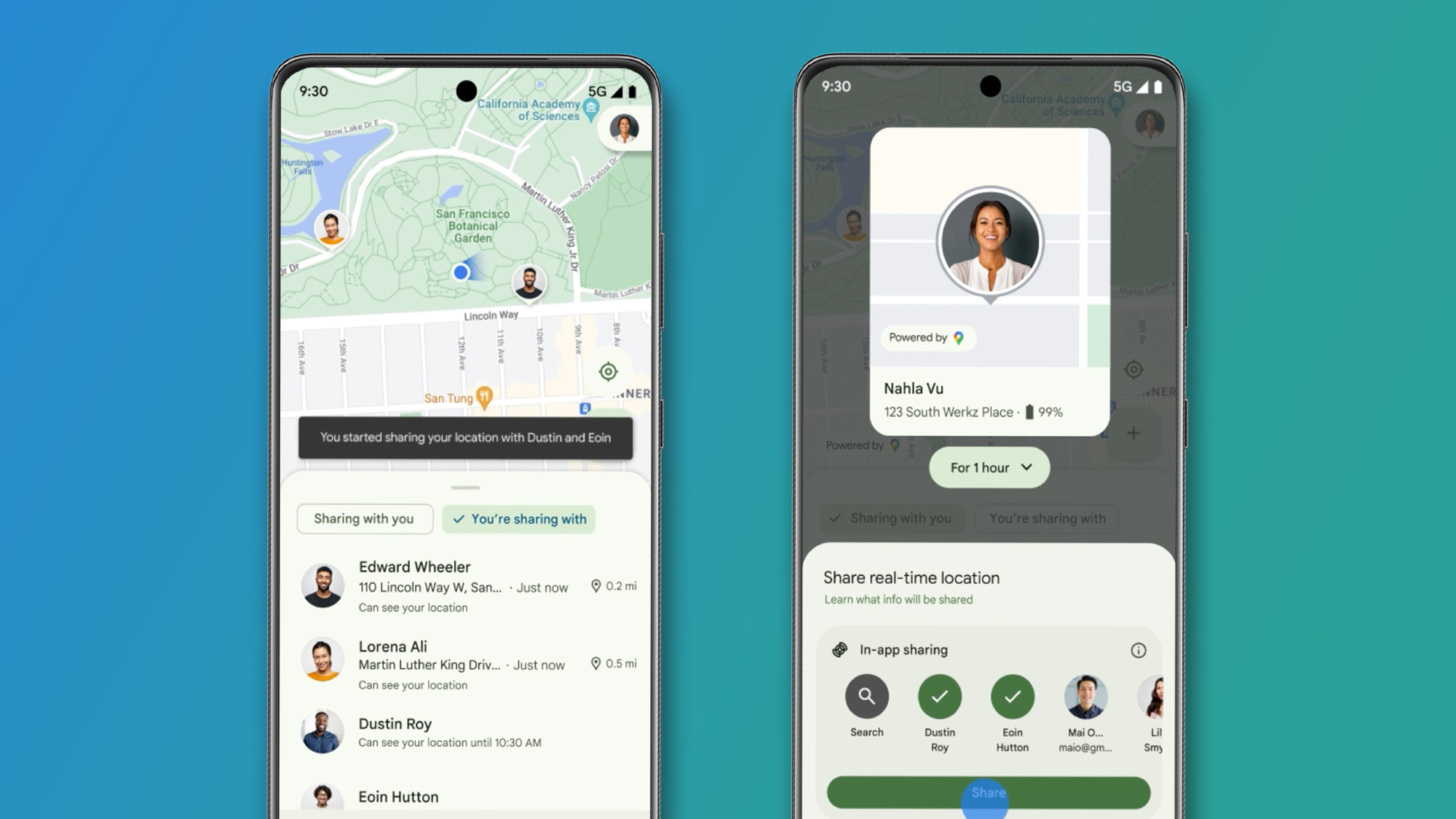















































































AI Memory Breakthrough: HEMA Extends Conversation Lengths by 3X
This is a Plain English Papers summary of a research paper called AI Memory Breakthrough: HEMA Extends Conversation Lengths by 3X. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. The Problem with AI's Memory: Why LLMs Forget Long Conversations Large language models (LLMs) have revolutionized natural language processing, but they struggle with a critical limitation: maintaining coherence in extended conversations. Despite impressive capabilities within their context windows, these models "forget" earlier dialogue segments when conversations span hundreds of turns, compromising their ability to maintain continuity and recall important details. This memory limitation stems from fixed context windows that can only accommodate a finite number of tokens. When conversations exceed this limit, earlier content gets truncated, leading to disjointed responses and factual inconsistencies. Inspired by the human hippocampus—the brain region responsible for storing and retrieving long-term memories—researchers have developed HEMA (Hippocampus-Inspired Extended Memory Architecture), a dual-memory system that extends LLMs' conversational abilities without requiring model retraining. HEMA enables an off-the-shelf 6B parameter transformer to maintain coherent dialogues beyond 300 turns while keeping prompt length under 3,500 tokens. Most impressively, this system adds minimal overhead—just 0.18 seconds of latency per turn and less than 1.2GB memory for storing 50,000 vector embeddings on a single A100 GPU. Memory Systems for AI: The State of the Art Building on External Memory Systems: Retrieval-Augmented Generation Early research into non-parametric memory systems like kNN-LM demonstrated that coupling language models with external datastores could improve factual recall without retraining core weights. This approach evolved with RAG (Retrieval-Augmented Generation) systems that retrieve relevant information from external sources to enhance model responses. The field has diversified to include streaming-RAG agents that perform retrieval at every conversation turn and Retro-architectures that incorporate retrieved "chunks" directly into intermediate LM layers. HippoRAG went further by integrating a graph-based index with Personalized PageRank to mimic hippocampal indexing, achieving significant precision gains on long-horizon QA benchmarks. Despite these advances, traditional RAG pipelines still face challenges with conversational continuity across extended dialogues. Remembering Conversations: Specialized Memory Systems for Dialogue Conversational AI requires specialized memory approaches that go beyond simple document retrieval. While standard RAG systems excel at factual information retrieval, they often struggle with maintaining the narrative thread and conversational context necessary for fluid, coherent dialogue spanning hundreds of turns. Current approaches frequently rely on simplistic solutions like recency-based truncation or keyword matching, which fail to capture the semantic richness and evolving context of extended conversations. These limitations create an urgent need for memory systems specifically designed for long-term dialogue coherence. Learning from the Brain: Hippocampus as a Model for AI Memory The human hippocampus provides an inspiring model for AI memory systems. It plays a crucial role in consolidating short-term experiences into long-term memories, selectively storing important information while discarding less relevant details. This biological memory system separates episodic memories (specific events) from semantic memories (general knowledge)—a distinction that HEMA emulates with its dual-memory architecture. By drawing on these principles, HEMA creates a more human-like memory system capable of both maintaining narrative coherence and recalling specific conversational details when needed. Inside HEMA: A Dual-Memory Architecture for Extended Conversations Compact Memory: The Global Narrative Thread The first component of HEMA's dual-memory system is Compact Memory—a continuously updated one-sentence summary that preserves the global narrative thread throughout the conversation. This summary functions like semantic memory, capturing the essential context without storing every detail. After each conversation turn, HEMA condenses the interaction into a concise summary (60 tokens or less) that captures the most important information. These summaries maintain the conversation's coherence by providing consistent context regardless of how many turns have passed. This approach allows the system to maintain awareness of the conversation's overall direction and important topics without exceeding context window limitations. Vector Memory: Episodic Storage and Retrieval The second component, Vector Memory, functions as an episodic store of conversation chunks conv

This is a Plain English Papers summary of a research paper called AI Memory Breakthrough: HEMA Extends Conversation Lengths by 3X. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Problem with AI's Memory: Why LLMs Forget Long Conversations
Large language models (LLMs) have revolutionized natural language processing, but they struggle with a critical limitation: maintaining coherence in extended conversations. Despite impressive capabilities within their context windows, these models "forget" earlier dialogue segments when conversations span hundreds of turns, compromising their ability to maintain continuity and recall important details.
This memory limitation stems from fixed context windows that can only accommodate a finite number of tokens. When conversations exceed this limit, earlier content gets truncated, leading to disjointed responses and factual inconsistencies.
Inspired by the human hippocampus—the brain region responsible for storing and retrieving long-term memories—researchers have developed HEMA (Hippocampus-Inspired Extended Memory Architecture), a dual-memory system that extends LLMs' conversational abilities without requiring model retraining.
HEMA enables an off-the-shelf 6B parameter transformer to maintain coherent dialogues beyond 300 turns while keeping prompt length under 3,500 tokens. Most impressively, this system adds minimal overhead—just 0.18 seconds of latency per turn and less than 1.2GB memory for storing 50,000 vector embeddings on a single A100 GPU.
Memory Systems for AI: The State of the Art
Building on External Memory Systems: Retrieval-Augmented Generation
Early research into non-parametric memory systems like kNN-LM demonstrated that coupling language models with external datastores could improve factual recall without retraining core weights. This approach evolved with RAG (Retrieval-Augmented Generation) systems that retrieve relevant information from external sources to enhance model responses.
The field has diversified to include streaming-RAG agents that perform retrieval at every conversation turn and Retro-architectures that incorporate retrieved "chunks" directly into intermediate LM layers. HippoRAG went further by integrating a graph-based index with Personalized PageRank to mimic hippocampal indexing, achieving significant precision gains on long-horizon QA benchmarks.
Despite these advances, traditional RAG pipelines still face challenges with conversational continuity across extended dialogues.
Remembering Conversations: Specialized Memory Systems for Dialogue
Conversational AI requires specialized memory approaches that go beyond simple document retrieval. While standard RAG systems excel at factual information retrieval, they often struggle with maintaining the narrative thread and conversational context necessary for fluid, coherent dialogue spanning hundreds of turns.
Current approaches frequently rely on simplistic solutions like recency-based truncation or keyword matching, which fail to capture the semantic richness and evolving context of extended conversations. These limitations create an urgent need for memory systems specifically designed for long-term dialogue coherence.
Learning from the Brain: Hippocampus as a Model for AI Memory
The human hippocampus provides an inspiring model for AI memory systems. It plays a crucial role in consolidating short-term experiences into long-term memories, selectively storing important information while discarding less relevant details.
This biological memory system separates episodic memories (specific events) from semantic memories (general knowledge)—a distinction that HEMA emulates with its dual-memory architecture. By drawing on these principles, HEMA creates a more human-like memory system capable of both maintaining narrative coherence and recalling specific conversational details when needed.
Inside HEMA: A Dual-Memory Architecture for Extended Conversations
Compact Memory: The Global Narrative Thread
The first component of HEMA's dual-memory system is Compact Memory—a continuously updated one-sentence summary that preserves the global narrative thread throughout the conversation. This summary functions like semantic memory, capturing the essential context without storing every detail.
After each conversation turn, HEMA condenses the interaction into a concise summary (60 tokens or less) that captures the most important information. These summaries maintain the conversation's coherence by providing consistent context regardless of how many turns have passed.
This approach allows the system to maintain awareness of the conversation's overall direction and important topics without exceeding context window limitations.
Vector Memory: Episodic Storage and Retrieval
The second component, Vector Memory, functions as an episodic store of conversation chunks converted into vector embeddings and queried via cosine similarity. This system enables precise retrieval of specific past exchanges when they become relevant to the current conversation turn.
When a user asks a question or mentions a topic discussed earlier, Vector Memory retrieves the most relevant previous exchanges, allowing the LLM to access specific details it would otherwise have "forgotten" due to context window limitations.
This component provides the factual grounding necessary for maintaining conversational coherence across hundreds of turns, substantially improving recall accuracy compared to context-window-only approaches.
Implementation Details: Making It Work in Practice
HEMA integrates several technical components to achieve its memory capabilities:
| Component | Specification |
|---|---|
| Embedding Model |
text-embedding-3-small (dim=1 536) |
| ANN Index | FAISS IVF-4096 + OPQ-16, nprobe=32 |
| Summarizer | Distil-PEGASUS-dialogue, $\leq 60$ tokens |
| Tokenizer | tiktoken-2025 (GPT-4o compatible) |
| LLM | 6B parameter transformer, frozen weights |
Table 5-0: HEMA component specifications showing the models and techniques used in the implementation.
The system uses text-embedding-3-small to generate vector representations, FAISS for efficient similarity search, and Distil-PEGASUS-dialogue for generating compact summaries. These components work together to create a memory system that integrates seamlessly with a 6B parameter transformer model while keeping prompt length under 3,500 tokens.
The implementation prioritizes both performance and efficiency, adding minimal computational overhead while significantly extending the model's conversational capabilities.
Testing HEMA: How We Evaluated the System
Challenging the System: Evaluation Tasks
HEMA was evaluated using long-form QA and story-continuation benchmarks designed to test both factual recall and narrative coherence. These benchmarks presented challenging scenarios requiring the system to maintain context and recall specific details across hundreds of conversation turns.
The evaluation tasks included:
- Long-form question answering that required recalling facts from earlier in the conversation
- Story continuation that tested the system's ability to maintain narrative coherence
- Multi-turn dialogues spanning up to 500 turns to evaluate long-term memory performance
These tasks were specifically designed to highlight the limitations of traditional context-window approaches while demonstrating HEMA's enhanced memory capabilities.
Measurement Tools: Baselines and Metrics
The research team used several metrics to evaluate HEMA's performance:
- Precision@K and Recall@K: Measuring the system's ability to retrieve relevant information
- Area Under the Precision-Recall Curve (AUPRC): Evaluating overall retrieval performance
- Factual recall accuracy: Testing the system's ability to correctly recall information from earlier conversations
- Human-rated coherence: Professional evaluators rated coherence on a 1-5 scale
HEMA was compared against two baselines: a Raw approach using only the standard context window, and a Compact-only approach using just the summarization component without Vector Memory retrieval.
HEMA in Action: Results and Performance Analysis
Finding the Needle in the Haystack: Precision and Recall Analysis
HEMA demonstrated substantial improvements in information retrieval compared to baseline approaches:
| Model | P@5 $\uparrow$ | R@50 $\uparrow$ | AUPRC $\uparrow$ |
|---|---|---|---|
| Raw | $0.29 \pm 0.03$ | $\begin{gathered} 0.45 \pm \ 0.03 \end{gathered}$ | 0.19 |
Table 5-1: Baseline raw performance showing limited precision and recall when using only the standard context window.
| Compact | $0.62 \pm 0.02$ | $\begin{gathered} 0.62 \pm \ 0.04 \end{gathered}$ | 0.46 |
|---|---|---|---|
| Compact + Vector |
$\mathbf{0 . 8 2} \pm \mathbf{0 . 0 2}$ | $\begin{gathered} \mathbf{0 . 7 4} \pm \ \mathbf{0 . 0 3} \end{gathered}$ | $\mathbf{0 . 7 2}$ |
Table 6-2: Comparison of Compact-only versus Compact+Vector memory approaches, showing significant improvements with the combined approach.
With 10,000 indexed chunks, HEMA's Vector Memory achieved precision@5 ≥ 0.80 and recall@50 ≥ 0.74, doubling the area under the precision-recall curve compared to using summarization alone. This demonstrates the system's ability to accurately retrieve relevant information from extended conversation histories.
Remembering Facts, Maintaining Coherence: Long-Form QA and Coherence Results
HEMA substantially improved both factual recall and perceived conversation coherence:
| Model | Long-form QA Acc. $\uparrow$ |
Blind Cohere nce (1-5) $\uparrow$ |
|---|---|---|
| Raw | $0.41 \pm 0.02$ | $2.7 \pm 0.2$ |
| Compact | $0.62 \pm 0.02$ | $3.8 \pm 0.2$ |
| Compact + Vector |
$\mathbf{0 . 8 7} \pm \mathbf{0 . 0 1}$ | $\mathbf{4 . 3} \pm \mathbf{0 . 1}$ |
Table 6-3: Comparison of factual recall accuracy and human-rated coherence across different memory approaches.
Factual recall accuracy increased from 41% with the Raw approach to 87% with the full HEMA system, while human-rated coherence improved from 2.7 to 4.3 on a 5-point scale. These results highlight how HEMA's dual-memory architecture significantly enhances both information recall and conversational flow.
What Matters Most: Ablation Studies
Ablation studies revealed key insights about HEMA's design choices:
| ID | Memory Policy |
Retrieval Latency (ms) |
Recal $\mathbf{1 @ 5 0}$ |
Cohe rence |
|---|---|---|---|---|
| A | No forgetting, no SoS |
21.4 | 0.74 | 4.32 |
| B | Semantic forgetting |
14.1 | 0.72 | 4.30 |
| C | Summary- of-summar ies (SoS) |
20.9 | $\mathbf{0 . 7 6}$ | 4.34 |
| D | Forgetting + SoS |
$\mathbf{1 3 . 8}$ | 0.75 | $\mathbf{4 . 3 5}$ |
Table 6-4: Ablation study results showing the impact of different memory policies on system performance.
Two key findings emerged:
Semantic forgetting: Age-weighted pruning of low-salience chunks reduced retrieval latency by 34% with less than 2 percentage points of recall loss, demonstrating an effective balance between performance and efficiency.
Two-level summary hierarchy: A summary-of-summaries approach prevented cascade errors in ultra-long conversations exceeding 1,000 turns, maintaining coherence even in extremely extended dialogues.
The optimal configuration combined both approaches (row D), achieving the fastest retrieval latency while maintaining strong recall and coherence scores.
Going the Distance: Scaling Behavior with Conversation Length
HEMA maintained strong performance even as conversation length increased dramatically:
| Turns | Raw Recall | Compact Recall |
$\mathbf{C}+\mathbf{V}$ Recall |
|---|---|---|---|
| 50 | 0.60 | 0.75 | $\mathbf{0 . 8 8}$ |
| 100 | 0.45 | 0.65 | $\mathbf{0 . 8 0}$ |
| 500 | 0.20 | 0.40 | $\mathbf{0 . 7 2}$ |
Table 6-5: Recall performance at different conversation lengths showing how raw performance degrades sharply while HEMA maintains higher recall.
At 50 turns, HEMA achieved 88% recall compared to 60% for the Raw approach. As conversations extended to 500 turns, the Raw approach's recall dropped to just 20%, while HEMA maintained 72% recall—more than three times better.
These results demonstrate HEMA's ability to scale effectively with conversation length, maintaining high performance where traditional approaches fail dramatically.
Beyond the Results: Implications and Future Directions
Current Boundaries: Limitations
Despite its impressive performance, HEMA has several limitations. The computational overhead of maintaining vector indices increases with conversation length, though the semantic forgetting mechanism helps mitigate this challenge.
Privacy considerations also arise since the system stores conversation history, requiring thoughtful implementation of data retention policies. Additionally, while HEMA significantly outperforms baseline approaches, extremely lengthy conversations (thousands of turns) may still present challenges that require further optimization.
The system also remains constrained by the quality of its underlying components—particularly the embedding model and summarizer—meaning that improvements in these technologies could further enhance HEMA's capabilities.
Next Steps: Future Work
Future research directions include:
- Refining the semantic forgetting mechanism to better identify which information to retain or discard
- Optimizing the summary-of-summaries approach for ultra-long conversations
- Exploring adaptive memory management strategies that adjust based on conversation content and user behavior
- Investigating integration with other memory architectures like graph-based memory or hierarchical compression
- Applying HEMA to specialized domains requiring domain-specific knowledge retention
These improvements could further extend HEMA's capabilities, enabling even longer and more coherent AI conversations across diverse applications.
The Memory Revolution: Conclusion and Practical Impact
HEMA represents a significant advance in extending the conversational capabilities of large language models. By reconciling verbatim recall with semantic continuity, the system offers a practical path toward scalable, privacy-aware conversational AI capable of engaging in months-long dialogue without retraining the underlying model.
The dual-memory architecture draws inspiration from human cognitive processes, separating global narrative maintenance (Compact Memory) from specific episodic recall (Vector Memory). This approach enables LLMs to maintain coherence beyond 300 turns while keeping prompt length under 3,500 tokens—substantially outperforming context-window-only approaches.
With factual recall accuracy improving from 41% to 87% and human-rated coherence increasing from 2.7 to 4.3, HEMA demonstrates how biologically-inspired memory systems can overcome one of the most significant limitations of current AI conversational systems.
As AI increasingly enters everyday life through conversational interfaces, systems like HEMA will play a crucial role in enabling the long-term relationships and extended interactions that users expect from truly helpful AI assistants.



