![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)





























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)









































































































.png?#)




.jpg?#)
































_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)



































































































![Rapidus in Talks With Apple as It Accelerates Toward 2nm Chip Production [Report]](https://www.iclarified.com/images/news/96937/96937/96937-640.jpg)




























































































































Learnable Neural Attention Boosts Vision Transformer Performance While Using Less Computing Power
This is a Plain English Papers summary of a research paper called Learnable Neural Attention Boosts Vision Transformer Performance While Using Less Computing Power. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview Researchers introduce Kolmogorov-Arnold Attention (KA-Attention), a learnable alternative to standard attention in Vision Transformers KA-Attention replaces the fixed softmax function with trainable neural networks Improves performance across multiple computer vision tasks and datasets Reduces computational complexity while maintaining or improving accuracy Shows greater robustness to adversarial attacks and out-of-distribution data Plain English Explanation Think of attention in transformers like a spotlight system at a concert. Traditional transformer attention uses a fixed method (softmax) to decide where to shine these spotlights - it's like having a pre-programmed lighting system that can't adapt to different performers or sta... Click here to read the full summary of this paper
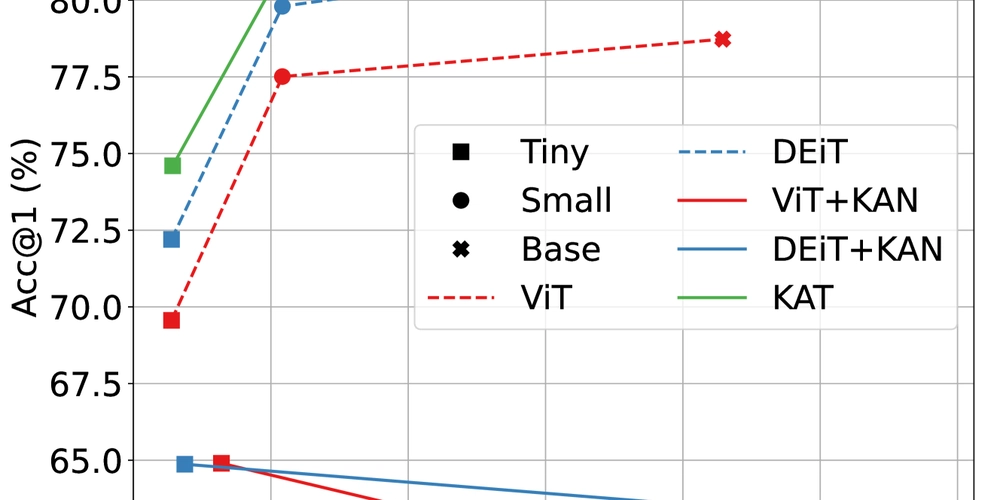
This is a Plain English Papers summary of a research paper called Learnable Neural Attention Boosts Vision Transformer Performance While Using Less Computing Power. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- Researchers introduce Kolmogorov-Arnold Attention (KA-Attention), a learnable alternative to standard attention in Vision Transformers
- KA-Attention replaces the fixed softmax function with trainable neural networks
- Improves performance across multiple computer vision tasks and datasets
- Reduces computational complexity while maintaining or improving accuracy
- Shows greater robustness to adversarial attacks and out-of-distribution data
Plain English Explanation
Think of attention in transformers like a spotlight system at a concert. Traditional transformer attention uses a fixed method (softmax) to decide where to shine these spotlights - it's like having a pre-programmed lighting system that can't adapt to different performers or sta...