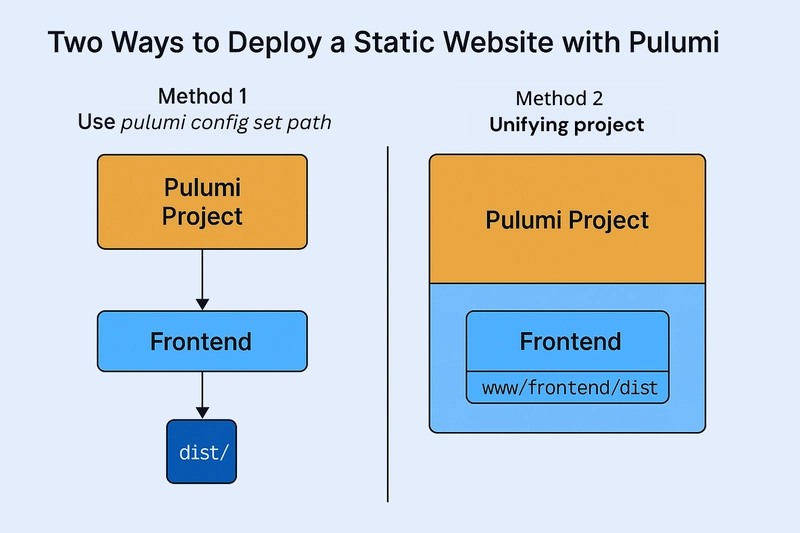
![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)



































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.jpg?#)

































_ArtemisDiana_Alamy.jpg?#)


 (1).webp?#)








































































-xl.jpg)












![Yes, the Gemini icon is now bigger and brighter on Android [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/02/Gemini-on-Galaxy-S25.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Rushes Five Planes of iPhones to US Ahead of New Tariffs [Report]](https://www.iclarified.com/images/news/96967/96967/96967-640.jpg)
![Apple Vision Pro 2 Allegedly in Production Ahead of 2025 Launch [Rumor]](https://www.iclarified.com/images/news/96965/96965/96965-640.jpg)
























































































































How to use dynatrace for anomalies detection to increase performance of application?
Dynatrace is a powerful observability platform that leverages its AI engine, Davis®, to automatically detect anomalies in your applications, services, and infrastructure. By identifying performance issues early, it helps you optimize application performance proactively. Here's how you can use Dynatrace for anomaly detection to enhance application performance: Set Up Comprehensive Monitoring Deploy Dynatrace OneAgent: Install the Dynatrace OneAgent on your application servers, containers, or cloud environments. It automatically discovers and monitors all components (applications, services, databases, infrastructure) without manual configuration. Enable Full-Stack Observability: Ensure Dynatrace monitors the entire technology stack—end-user experience, application performance, infrastructure metrics, and logs. This holistic view helps correlate anomalies across layers. Leverage Automatic Baselining Dynatrace uses multidimensional baselining to learn your application’s normal behavior over time (e.g., response times, error rates, traffic patterns). It observes metrics like CPU usage, memory, network latency, and user actions. After a learning period (typically 7 days), Dynatrace establishes a baseline and detects deviations automatically. For example, if response times spike beyond the baseline, it flags an anomaly. Configure Anomaly Detection Rules Access Anomaly Detection Settings: Go to Settings > Anomaly Detection in the Dynatrace UI. You can configure rules for applications, services, infrastructure, or databases. Customize Thresholds: Choose between: Automatic Baselining: Dynatrace adjusts thresholds dynamically based on historical data. Fixed Thresholds: Set specific values (e.g., response time > 500ms or failure rate > 5%) for critical metrics. Fine-Tune Sensitivity: Adjust sensitivity (Low, Medium, High) to control how strict the detection is. For mission-critical apps, use High sensitivity to catch even minor deviations. Traffic Anomalies: Enable detection for unexpected spikes or drops in traffic, which could indicate performance bottlenecks or underutilized resources. Use Davis AI for Root Cause Analysis When an anomaly is detected (e.g., slow response times or high error rates), Davis AI analyzes the event in real-time, identifying the root cause (e.g., a database query bottleneck or CPU saturation). Review the Problems section in Dynatrace to see detailed insights, including impacted services, dependencies, and suggested fixes. Monitor Key Performance Metrics Focus on critical metrics that impact performance: Response Time: Detect degradation in median or slowest 10% of requests. Failure Rate: Identify increases in errors that could degrade user experience. Service Load: Spot unusual traffic patterns that might overload resources. Set specific thresholds for these metrics under Settings > Anomaly Detection > Applications or Services. Predictive Analytics for Proactive Optimization Dynatrace uses predictive analytics to forecast traffic patterns based on historical data. For instance, it can predict high-load periods (e.g., Black Friday) and alert you if actual traffic deviates significantly. Use these insights to scale resources or optimize code before performance degrades. Act on Alerts and Insights Set Up Alerts: Configure notifications (e.g., email, Slack, or custom webhooks) for detected anomalies via Settings > Integration > Problem Notifications. Resolve Issues: Use the detailed context provided (e.g., code-level traces, logs, or infrastructure metrics) to fix the root cause. For example, optimize a slow database query or increase server capacity. Optimize Low-Traffic Scenarios For applications with low traffic, adjust the minimum actions-per-minute threshold (e.g., 10 actions/min) to avoid false positives. This ensures anomaly detection focuses on meaningful data. Example Workflow Scenario: Your application experiences intermittent slowdowns. Step 1: Dynatrace detects a response time anomaly (e.g., 50% above baseline). Step 2: Davis AI identifies a database query taking 80% of the request time. Step 3: You optimize the query (e.g., add an index), redeploy, and monitor the improvement. Result: Response time returns to normal, improving user experience and performance. Tips for Maximum Performance Impact Focus on Business-Critical Services: Set stricter thresholds for key services or requests (e.g., payment processing) via Settings > Anomaly Detection > Services. Reset Baselines After Changes: If you deploy a major update, reset the baseline (via the UI) to reflect the new normal. Integrate Logs: Combine log analytics with anomaly detection to catch issues like recurring errors affecting performance. Regularly Review Trends: Use Dynatrace dashboards to track performance improvements over time after resolving anomalies. By automating anomaly detection and providing actionable insights, Dynatrace helps you catch and resolve performance issues before they impact users, ultimately enhancing

Dynatrace is a powerful observability platform that leverages its AI engine, Davis®, to automatically detect anomalies in your applications, services, and infrastructure. By identifying performance issues early, it helps you optimize application performance proactively. Here's how you can use Dynatrace for anomaly detection to enhance application performance:
Set Up Comprehensive Monitoring
Deploy Dynatrace OneAgent: Install the Dynatrace OneAgent on your application servers, containers, or cloud environments. It automatically discovers and monitors all components (applications, services, databases, infrastructure) without manual configuration.
Enable Full-Stack Observability: Ensure Dynatrace monitors the entire technology stack—end-user experience, application performance, infrastructure metrics, and logs. This holistic view helps correlate anomalies across layers.Leverage Automatic Baselining
Dynatrace uses multidimensional baselining to learn your application’s normal behavior over time (e.g., response times, error rates, traffic patterns). It observes metrics like CPU usage, memory, network latency, and user actions.
After a learning period (typically 7 days), Dynatrace establishes a baseline and detects deviations automatically. For example, if response times spike beyond the baseline, it flags an anomaly.Configure Anomaly Detection Rules
Access Anomaly Detection Settings: Go to Settings > Anomaly Detection in the Dynatrace UI. You can configure rules for applications, services, infrastructure, or databases.
Customize Thresholds: Choose between:
Automatic Baselining: Dynatrace adjusts thresholds dynamically based on historical data.
Fixed Thresholds: Set specific values (e.g., response time > 500ms or failure rate > 5%) for critical metrics.
Fine-Tune Sensitivity: Adjust sensitivity (Low, Medium, High) to control how strict the detection is. For mission-critical apps, use High sensitivity to catch even minor deviations.
Traffic Anomalies: Enable detection for unexpected spikes or drops in traffic, which could indicate performance bottlenecks or underutilized resources.Use Davis AI for Root Cause Analysis
When an anomaly is detected (e.g., slow response times or high error rates), Davis AI analyzes the event in real-time, identifying the root cause (e.g., a database query bottleneck or CPU saturation).
Review the Problems section in Dynatrace to see detailed insights, including impacted services, dependencies, and suggested fixes.Monitor Key Performance Metrics
Focus on critical metrics that impact performance:
Response Time: Detect degradation in median or slowest 10% of requests.
Failure Rate: Identify increases in errors that could degrade user experience.
Service Load: Spot unusual traffic patterns that might overload resources.
Set specific thresholds for these metrics under Settings > Anomaly Detection > Applications or Services.Predictive Analytics for Proactive Optimization
Dynatrace uses predictive analytics to forecast traffic patterns based on historical data. For instance, it can predict high-load periods (e.g., Black Friday) and alert you if actual traffic deviates significantly.
Use these insights to scale resources or optimize code before performance degrades.Act on Alerts and Insights
Set Up Alerts: Configure notifications (e.g., email, Slack, or custom webhooks) for detected anomalies via Settings > Integration > Problem Notifications.
Resolve Issues: Use the detailed context provided (e.g., code-level traces, logs, or infrastructure metrics) to fix the root cause. For example, optimize a slow database query or increase server capacity.Optimize Low-Traffic Scenarios
For applications with low traffic, adjust the minimum actions-per-minute threshold (e.g., 10 actions/min) to avoid false positives. This ensures anomaly detection focuses on meaningful data.
Example Workflow
Scenario: Your application experiences intermittent slowdowns.
Step 1: Dynatrace detects a response time anomaly (e.g., 50% above baseline).
Step 2: Davis AI identifies a database query taking 80% of the request time.
Step 3: You optimize the query (e.g., add an index), redeploy, and monitor the improvement.
Result: Response time returns to normal, improving user experience and performance.
Tips for Maximum Performance Impact
Focus on Business-Critical Services: Set stricter thresholds for key services or requests (e.g., payment processing) via Settings > Anomaly Detection > Services.
Reset Baselines After Changes: If you deploy a major update, reset the baseline (via the UI) to reflect the new normal.
Integrate Logs: Combine log analytics with anomaly detection to catch issues like recurring errors affecting performance.
Regularly Review Trends: Use Dynatrace dashboards to track performance improvements over time after resolving anomalies.
By automating anomaly detection and providing actionable insights, Dynatrace helps you catch and resolve performance issues before they impact users, ultimately enhancing application reliability and speed.