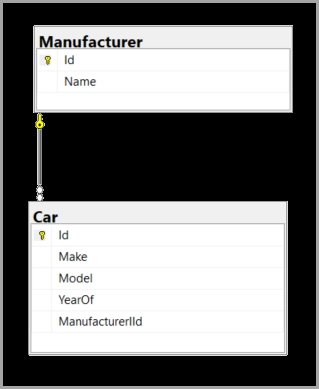





















































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)
































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)










































































































(1).jpg?#)

































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
































































































![The Material 3 Expressive redesign of Google Clock leaks out [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/03/Google-Clock-v2.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)
![What Google Messages features are rolling out [May 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2023/12/google-messages-name-cover.png?resize=1200%2C628&quality=82&strip=all&ssl=1)













![New Apple iPad mini 7 On Sale for $399! [Lowest Price Ever]](https://www.iclarified.com/images/news/96096/96096/96096-640.jpg)
![Apple to Split iPhone Launches Across Fall and Spring in Major Shakeup [Report]](https://www.iclarified.com/images/news/97211/97211/97211-640.jpg)
![Apple to Move Camera to Top Left, Hide Face ID Under Display in iPhone 18 Pro Redesign [Report]](https://www.iclarified.com/images/news/97212/97212/97212-640.jpg)
![Apple Developing Battery Case for iPhone 17 Air Amid Battery Life Concerns [Report]](https://www.iclarified.com/images/news/97208/97208/97208-640.jpg)

























































































How I Used Python to Almost Crash ChatGPT
As AI continues to evolve, developers and researchers are exploring its boundaries. One such experiment I undertook involved using Python to test the limits of ChatGPT's response generation capabilities. This blog post documents how I structured the experiment, what I observed, and the key takeaways from the process. Objective The goal was to explore: How ChatGPT handles dynamically generated prompts at scale. How it deals with recursion, large inputs, and nested logic. What practical limitations (length, processing, memory) exist in the interaction model. Setup I used Python to generate structured prompts that grew in complexity, size, or logical depth. The experiments were run using both the ChatGPT web interface and API, where applicable. Environment Python version: 3.11 ChatGPT version: GPT-4 (via web) Libraries: None required beyond standard Python Experiment 1: Recursive Prompt Generation I wrote a Python script to create recursive text prompts, where each prompt builds on the previous one with increasing complexity. def generate_recursive_prompts(count): prompts = [] base = "Explain recursion." for i in range(1, count + 1): base = f"Explain recursion based on: [{base}]" prompts.append(base) return prompts Test Details Generated prompts ranging from 1 to 500 levels of nesting. Copied the most complex prompt (character count > 8000) into the ChatGPT interface. Observations ChatGPT truncated or summarized after a certain complexity level. At around 10–15 levels deep, it began to generalize rather than expand on each level. Beyond a certain character limit (~4,096 tokens for web interface), it failed to process the full prompt. Experiment 2: Bulk Prompt Submission I used Python to simulate sending multiple prompts programmatically. prompts = [f"Explain the concept of item {i}" for i in range(1000)] While I didn’t use the API to send them automatically (due to OpenAI usage limits), I manually tested the effect of batch processing multiple related prompts back-to-back. Observations The model maintained context well up to ~10–15 prompts in a thread. After ~20 prompts, earlier context began to degrade unless explicitly restated. Repeated similar prompts sometimes triggered output repetition or optimization attempts by the model. Experiment 3: Token Overflow Test I used Python to construct a prompt exceeding the token limits. text = "This is a test sentence. " * 2000 print(len(text)) # Character count Results At ~8,000 characters (approx. 3,000–4,000 tokens), ChatGPT returned a "message too long" error. The model did not crash, but it refused to process the input. Token limits are strictly enforced; longer prompts are automatically rejected. Key Learnings 1. ChatGPT Has Hard Limits The web interface caps token limits around 4,096 tokens (input + output combined). API limits are higher (up to 8,192 or 32,768 tokens depending on the model), but still finite. 2. Recursive or Nested Prompts Are Abstracted ChatGPT recognizes recursion but will not endlessly expand recursive logic unless specifically instructed—and even then, only within safe limits. 3. Context Management Is Strong but Not Infinite ChatGPT can handle sequential prompts but begins to lose accuracy and detail as the thread length increases. Resetting context or summarizing helps manage longer sessions. Conclusion While I did not "crash" ChatGPT in a literal sense, these experiments clearly revealed its processing limitations. Using Python to automate prompt generation is an effective way to test the robustness and practical boundaries of large language models. For developers, researchers, or curious users, this type of testing provides useful insights into: Designing better prompts Understanding AI constraints Identifying when to switch from chat-based interactions to API-based solutions for scalability

As AI continues to evolve, developers and researchers are exploring its boundaries. One such experiment I undertook involved using Python to test the limits of ChatGPT's response generation capabilities. This blog post documents how I structured the experiment, what I observed, and the key takeaways from the process.
Objective
The goal was to explore:
How ChatGPT handles dynamically generated prompts at scale.
How it deals with recursion, large inputs, and nested logic.
What practical limitations (length, processing, memory) exist in the interaction model.
Setup
I used Python to generate structured prompts that grew in complexity, size, or logical depth. The experiments were run using both the ChatGPT web interface and API, where applicable.
Environment
Python version: 3.11
ChatGPT version: GPT-4 (via web)
Libraries: None required beyond standard Python
Experiment 1: Recursive Prompt Generation
I wrote a Python script to create recursive text prompts, where each prompt builds on the previous one with increasing complexity.
def generate_recursive_prompts(count):
prompts = []
base = "Explain recursion."
for i in range(1, count + 1):
base = f"Explain recursion based on: [{base}]"
prompts.append(base)
return prompts
Test Details
Generated prompts ranging from 1 to 500 levels of nesting.
Copied the most complex prompt (character count > 8000) into the ChatGPT interface.
Observations
ChatGPT truncated or summarized after a certain complexity level.
At around 10–15 levels deep, it began to generalize rather than expand on each level.
Beyond a certain character limit (~4,096 tokens for web interface), it failed to process the full prompt.
Experiment 2: Bulk Prompt Submission
I used Python to simulate sending multiple prompts programmatically.
prompts = [f"Explain the concept of item {i}" for i in range(1000)]
While I didn’t use the API to send them automatically (due to OpenAI usage limits), I manually tested the effect of batch processing multiple related prompts back-to-back.
Observations
The model maintained context well up to ~10–15 prompts in a thread.
After ~20 prompts, earlier context began to degrade unless explicitly restated.
Repeated similar prompts sometimes triggered output repetition or optimization attempts by the model.
Experiment 3: Token Overflow Test
I used Python to construct a prompt exceeding the token limits.
text = "This is a test sentence. " * 2000
print(len(text)) # Character count
Results
- At ~8,000 characters (approx. 3,000–4,000 tokens), ChatGPT returned a "message too long" error.
- The model did not crash, but it refused to process the input.
- Token limits are strictly enforced; longer prompts are automatically rejected.
Key Learnings
1. ChatGPT Has Hard Limits
The web interface caps token limits around 4,096 tokens (input + output combined).
API limits are higher (up to 8,192 or 32,768 tokens depending on the model), but still finite.
2. Recursive or Nested Prompts Are Abstracted
ChatGPT recognizes recursion but will not endlessly expand recursive logic unless specifically instructed—and even then, only within safe limits.
3. Context Management Is Strong but Not Infinite
ChatGPT can handle sequential prompts but begins to lose accuracy and detail as the thread length increases.
Resetting context or summarizing helps manage longer sessions.
Conclusion
While I did not "crash" ChatGPT in a literal sense, these experiments clearly revealed its processing limitations. Using Python to automate prompt generation is an effective way to test the robustness and practical boundaries of large language models.
For developers, researchers, or curious users, this type of testing provides useful insights into:
- Designing better prompts
- Understanding AI constraints
- Identifying when to switch from chat-based interactions to API-based solutions for scalability