










































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)






























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)









































































































.png?#)




.jpg?#)
































_Christophe_Coat_Alamy.jpg?#)

































































































![Rapidus in Talks With Apple as It Accelerates Toward 2nm Chip Production [Report]](https://www.iclarified.com/images/news/96937/96937/96937-640.jpg)






























































































































Générer un id unique avec une solution serverless !
Contexte Le besoin Lors de l'intégration d'une application du marché pour un de mes clients, celui-ci a eu besoin de fournir à cette application un identifiant unique incrémental, celle-ci étant incapable de le générer au format souhaité. Plusieurs solutions ont été discutées : Permettre à l'application de se connecter directement à une base de données relationnelle existante du client pour manipuler une séquence SQL : pas génial d'un point de vue ségrégation, responsabilité et couplage faible Développer une API dans un des backends existants permettant de renvoyer un ID incrémental : similaire à la solution précédente, sans la connexion directe à la base de données. Un peu mieux mais pas génial non plus Développer un backend from sractch permettant de renvoyer cet id unique incrémental : un peu lourd non, juste pour ça ? Alors que faire ? Hé bien étudions les contraintes du client pour faire notre choix. Les contraintes La garantie de l'unicité des ID récupérés par l'application en cours d'intégration : c'est le point le plus important Un coût faible (le plus faible possible) De la sécurité sur la solution Architecture mise en place Alors on fait quoi ? Garantie de l'unicité des ID récupérés: ça m'évoque la notion de concurrence des opérations et de consistent read/write Coût faible, ça résonne bien souvent avec serverless et paiement à l'usage De la sécurité : dans le contexte d'échange inter applicaitf, je l'associe tout d'abord avec authentification Une solution qui répond à toutes ces contraintes, c'est une solution full serverless basé sur les services API Gateway, Lambda et DynamoDB, je voux explique pourquoi juste après. Présentation de la solution La solution imaginée est la suivante : Une api est exposée via le service API Gateway et sécurisée par une API Key Cette API déclenche une fonction Lambda qui permet d'aller lire et écrire dans une table DynamoDB La table DynamoDB permet de stocker la valeur courante de la séquence que l'on cherche à incrémenter à chaque appel Table dynamoDB C'est là que va être stockée la valeur de notre séquence Code terraform de création de la table # Création de la table DynamoDB resource "aws_dynamodb_table" "generate_id_unique" { name = local.dynamodb_name billing_mode = "PAY_PER_REQUEST" hash_key = "sequenceId" attribute { name = "sequenceId" type = "S" } point_in_time_recovery { enabled = false } } # Initialisation de la table avec la valeur 0 resource "aws_dynamodb_table_item" "initial_sequence_item" { table_name = aws_dynamodb_table.generate_id_unique.name hash_key = aws_dynamodb_table.generate_id_unique.hash_key item = jsonencode({ "sequenceId" = { "S" = local.application_name } "sequenceValue" = { "N" = "0" } }) lifecycle { ignore_changes = [item] } } Fonction lambda C'est cette fonction qui va mettre à jour à la table avec la prochaine valeur de la séquence, et la renvoyer à l'appelant Code terraform pour déployer la lambda (merci Anton Babenko pour le module terraform) module "generate_id_unique" { source = "terraform-aws-modules/lambda/aws" function_name = local.lambda_name description = "Permet de générer un id unique" handler = "${local.application_name}.lambda_handler" runtime = "python3.12" architectures = ["arm64"] layers = ["arn:aws:lambda:eu-west-3:017000801446:layer:AWSLambdaPowertoolsPythonV2-Arm64:60"] source_path = "${path.module}/resource/lambda/${local.application_name}.py" environment_variables = { DYNAMODB_TABLE = aws_dynamodb_table.generate_id_unique.name SEQUENCE_ID = local.application_name } attach_policy_statements = true policy_statements = { dynamodb = { effect = "Allow" actions = ["dynamodb:UpdateItem", "dynamodb:GetItem", "dynamodb:PutItem"] resources = [aws_dynamodb_table.generate_id_unique.arn] } } tags = { Name = local.lambda_name } } API Gateway C'est elle qui nous permet d'exposer une route pour invoquer notre lambda Code terraform de déploiement de l'API Gateway resource "aws_api_gateway_rest_api" "generate_id_unique" { name = local.api_gateway_name } resource "aws_api_gateway_resource" "generate_id_unique" { rest_api_id = aws_api_gateway_rest_api.generate_id_unique.id parent_id = aws_api_gateway_rest_api.generate_id_unique.root_resource_id path_part = "new-id" } resource "aws_api_gateway_method" "generate_id_unique" { rest_api_id = aws_api_gateway_rest_api.generate_id_unique.id resource_id = aws_api_gateway_resource.generate_id_unique.id http_method = "GET" authorization = "NONE" api_key_required = true } resource "aws_api_gateway_integration"
Contexte
Le besoin
Lors de l'intégration d'une application du marché pour un de mes clients, celui-ci a eu besoin de fournir à cette application un identifiant unique incrémental, celle-ci étant incapable de le générer au format souhaité.
Plusieurs solutions ont été discutées :
- Permettre à l'application de se connecter directement à une base de données relationnelle existante du client pour manipuler une séquence SQL : pas génial d'un point de vue ségrégation, responsabilité et couplage faible
- Développer une API dans un des backends existants permettant de renvoyer un ID incrémental : similaire à la solution précédente, sans la connexion directe à la base de données. Un peu mieux mais pas génial non plus
- Développer un backend from sractch permettant de renvoyer cet id unique incrémental : un peu lourd non, juste pour ça ?
Alors que faire ? Hé bien étudions les contraintes du client pour faire notre choix.
Les contraintes
- La garantie de l'unicité des ID récupérés par l'application en cours d'intégration : c'est le point le plus important
- Un coût faible (le plus faible possible)
- De la sécurité sur la solution
Architecture mise en place
Alors on fait quoi ?
- Garantie de l'unicité des ID récupérés: ça m'évoque la notion de concurrence des opérations et de consistent read/write
- Coût faible, ça résonne bien souvent avec serverless et paiement à l'usage
- De la sécurité : dans le contexte d'échange inter applicaitf, je l'associe tout d'abord avec authentification
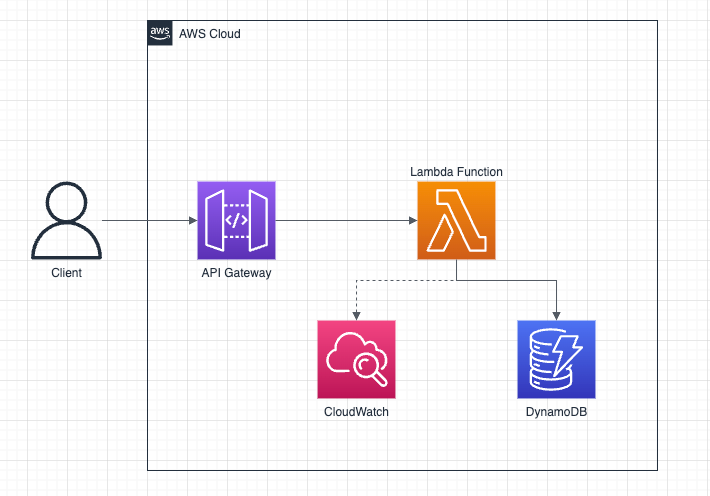
Une solution qui répond à toutes ces contraintes, c'est une solution full serverless basé sur les services API Gateway, Lambda et DynamoDB, je voux explique pourquoi juste après.
Présentation de la solution
La solution imaginée est la suivante :
- Une api est exposée via le service API Gateway et sécurisée par une API Key
- Cette API déclenche une fonction Lambda qui permet d'aller lire et écrire dans une table DynamoDB
- La table DynamoDB permet de stocker la valeur courante de la séquence que l'on cherche à incrémenter à chaque appel
Table dynamoDB
- C'est là que va être stockée la valeur de notre séquence
- Code terraform de création de la table
# Création de la table DynamoDB
resource "aws_dynamodb_table" "generate_id_unique" {
name = local.dynamodb_name
billing_mode = "PAY_PER_REQUEST"
hash_key = "sequenceId"
attribute {
name = "sequenceId"
type = "S"
}
point_in_time_recovery {
enabled = false
}
}
# Initialisation de la table avec la valeur 0
resource "aws_dynamodb_table_item" "initial_sequence_item" {
table_name = aws_dynamodb_table.generate_id_unique.name
hash_key = aws_dynamodb_table.generate_id_unique.hash_key
item = jsonencode({
"sequenceId" = { "S" = local.application_name }
"sequenceValue" = { "N" = "0" }
})
lifecycle {
ignore_changes = [item]
}
}
Fonction lambda
- C'est cette fonction qui va mettre à jour à la table avec la prochaine valeur de la séquence, et la renvoyer à l'appelant
- Code terraform pour déployer la lambda (merci Anton Babenko pour le module terraform)
module "generate_id_unique" {
source = "terraform-aws-modules/lambda/aws"
function_name = local.lambda_name
description = "Permet de générer un id unique"
handler = "${local.application_name}.lambda_handler"
runtime = "python3.12"
architectures = ["arm64"]
layers = ["arn:aws:lambda:eu-west-3:017000801446:layer:AWSLambdaPowertoolsPythonV2-Arm64:60"]
source_path = "${path.module}/resource/lambda/${local.application_name}.py"
environment_variables = {
DYNAMODB_TABLE = aws_dynamodb_table.generate_id_unique.name
SEQUENCE_ID = local.application_name
}
attach_policy_statements = true
policy_statements = {
dynamodb = {
effect = "Allow"
actions = ["dynamodb:UpdateItem", "dynamodb:GetItem", "dynamodb:PutItem"]
resources = [aws_dynamodb_table.generate_id_unique.arn]
}
}
tags = {
Name = local.lambda_name
}
}
API Gateway
- C'est elle qui nous permet d'exposer une route pour invoquer notre lambda
- Code terraform de déploiement de l'API Gateway
resource "aws_api_gateway_rest_api" "generate_id_unique" {
name = local.api_gateway_name
}
resource "aws_api_gateway_resource" "generate_id_unique" {
rest_api_id = aws_api_gateway_rest_api.generate_id_unique.id
parent_id = aws_api_gateway_rest_api.generate_id_unique.root_resource_id
path_part = "new-id"
}
resource "aws_api_gateway_method" "generate_id_unique" {
rest_api_id = aws_api_gateway_rest_api.generate_id_unique.id
resource_id = aws_api_gateway_resource.generate_id_unique.id
http_method = "GET"
authorization = "NONE"
api_key_required = true
}
resource "aws_api_gateway_integration" "generate_id_unique" {
rest_api_id = aws_api_gateway_rest_api.generate_id_unique.id
resource_id = aws_api_gateway_resource.generate_id_unique.id
http_method = aws_api_gateway_method.generate_id_unique.http_method
integration_http_method = "POST"
type = "AWS_PROXY"
uri = module.generate_id_unique.lambda_function_invoke_arn
}
resource "aws_api_gateway_deployment" "generate_id_unique" {
rest_api_id = aws_api_gateway_rest_api.generate_id_unique.id
depends_on = [
aws_api_gateway_integration.generate_id_unique
]
}
resource "aws_api_gateway_stage" "generate_uid" {
deployment_id = aws_api_gateway_deployment.generate_id_unique.id
rest_api_id = aws_api_gateway_rest_api.generate_id_unique.id
stage_name = "api"
}
resource "aws_api_gateway_api_key" "generate_uid" {
name = "${local.api_gateway_name}-key"
}
resource "aws_api_gateway_usage_plan" "generate_uid" {
name = "${local.api_gateway_name}-usage-plan"
api_stages {
api_id = aws_api_gateway_rest_api.generate_id_unique.id
stage = aws_api_gateway_stage.generate_uid.stage_name
}
}
resource "aws_api_gateway_usage_plan_key" "generate_uid" {
key_id = aws_api_gateway_api_key.generate_uid.id
key_type = "API_KEY"
usage_plan_id = aws_api_gateway_usage_plan.generate_uid.id
}
resource "aws_lambda_permission" "generate_uid" {
statement_id = "AllowExecutionFromAPIGateway"
action = "lambda:InvokeFunction"
function_name = module.generate_id_unique.lambda_function_arn
principal = "apigateway.amazonaws.com"
source_arn = "${aws_api_gateway_rest_api.generate_id_unique.execution_arn}/*/*"
}
Fichier locals.tf
- Contenu du fichier locals.tf pour bien comprendre les codes précédents
locals {
application_name = "generate-id-unique"
resource_prefix = "esc"
resource_base_name = "${local.resource_prefix}-${local.application_name}"
lambda_name = "${local.resource_base_name}-lambda"
dynamodb_name = "${local.resource_base_name}-table"
api_gateway_name = "${local.resource_base_name}-apigw"
}
Comment gère-t-on les acccès concurrents ?
- La gestion des accès concurrents va se faire dans le code de la Lambda, en python :
import boto3
import os
import json
from botocore.exceptions import ClientError
from aws_lambda_powertools import Logger
logger = Logger()
dynamodb = boto3.resource('dynamodb')
TABLE_NAME = os.environ.get('DYNAMODB_TABLE')
SEQUENCE_ID = os.environ.get('SEQUENCE_ID')
if not TABLE_NAME:
logger.error("DYNAMODB_TABLE environment variable not set")
raise ValueError("DYNAMODB_TABLE environment variable is not set")
if not SEQUENCE_ID:
logger.error("SEQUENCE_ID environment variable not set")
raise ValueError("SEQUENCE_ID environment variable is not set")
table = dynamodb.Table(TABLE_NAME)
@logger.inject_lambda_context
def lambda_handler(event, context):
try:
logger.info("Attempting to update sequence", extra={"sequence_id": SEQUENCE_ID})
response = table.update_item(
Key={'sequenceId': SEQUENCE_ID},
UpdateExpression="ADD sequenceValue :inc",
ExpressionAttributeValues={':inc': 1},
ReturnValues="UPDATED_NEW",
ConditionExpression="attribute_exists(sequenceId)"
)
sequence_value = response['Attributes']['sequenceValue']
logger.info("Successfully updated sequence", extra={"sequence_value": sequence_value})
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json'
},
'body': json.dumps({
'sequence': str(sequence_value)
})
}
except ClientError as e:
error_code = e.response['Error']['Code']
if error_code == 'ConditionalCheckFailedException':
try:
logger.info("Sequence not found, initializing new sequence", extra={"sequence_id": SEQUENCE_ID})
response = table.put_item(
Item={
'sequenceId': SEQUENCE_ID,
'sequenceValue': 0
}
)
except ClientError as put_error:
logger.error("Failed to initialize sequence", extra={"error": str(put_error)})
return {
'statusCode': 500,
'body': json.dumps({
'error': f'Failed to initialize sequence: {str(put_error)}'
})
}
else:
logger.error("Database error occurred", extra={"error": str(e)})
return {
'statusCode': 500,
'headers': {
'Content-Type': 'application/json'
},
'body': json.dumps({
'error': f'Database error: {str(e)}'
})
}
except Exception as e:
logger.error("Unexpected error occurred", extra={"error": str(e)})
return {
'statusCode': 500,
'headers': {
'Content-Type': 'application/json'
},
'body': json.dumps({
'error': f'Unexpected error: {str(e)}'
})
}
- La partie la plus importante, c'est celle-ci :
response = table.update_item(
Key={'sequenceId': SEQUENCE_ID},
UpdateExpression="ADD sequenceValue :inc",
ExpressionAttributeValues={':inc': 1},
ReturnValues="UPDATED_NEW",
ConditionExpression="attribute_exists(sequenceId)"
)
Ce code utilise les "Atomic counters", via "ADD sequenceValue :inc": cette fonctionnalité de DynamoDB garantit que les différentes écritures sont exécutées les unes après les autres, sans interférences.
Extrait de la documentation :
You can use the
UpdateItemoperation to implement an atomic counter—a numeric attribute that is incremented, unconditionally, without interfering with other write requests. (All write requests are applied in the order in which they were received.) With an atomic counter, the updates are not idempotent. In other words, the numeric value increments or decrements each time you callUpdateItem. If the increment value used to update the atomic counter is positive, then it can cause overcounting. If the increment value is negative, then it can cause undercounting.
A noter qu'on retourne aussi directement la valeur incrémentée dans la même instruction afin d'être plus performant.
Comment vérifier le coût ce qu'on déploie ?
Nous déployons une solution complètement serveless, on ne va donc payer qu'à l'usage. Lançons l'outil infracost pour nous en assurer avec la commande infracost breakdown --path=.
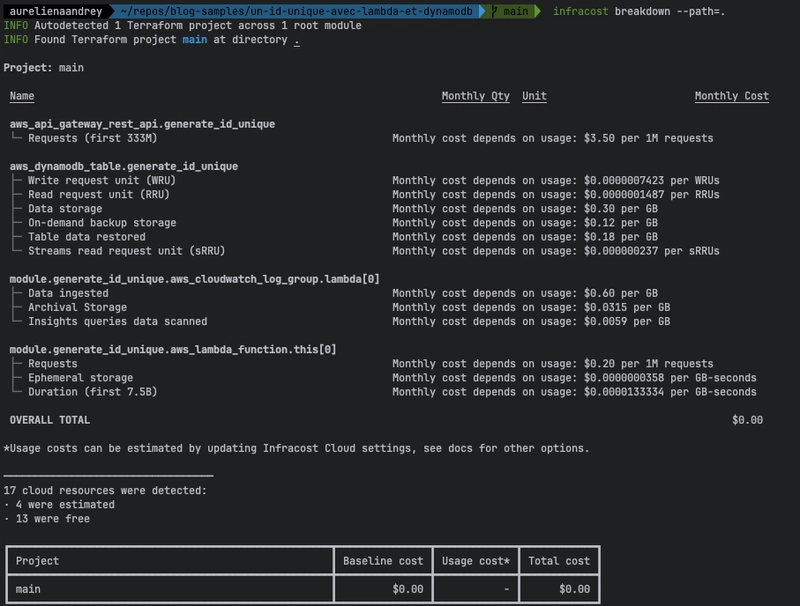
C'est bien le cas : il n'y pas de coût associé à la mise en place des services, uniquement des coûts à l'usage.
Prenons comme hypothèse, que nous allons avoir avoir environ 100 000 requêtes/mois, soit 5 000 requêtes/jour ouvré (bien au-delà des besoins de mon client).
Créons un fichier infracost-usage.yml à la racine de notre projet pour paraméter l'outil
version: 0.1
resource_usage:
module.generate_id_unique.aws_lambda_function.this[0]:
monthly_requests: 100000
request_duration_ms: 300
aws_dynamodb_table.generate_id_unique:
monthly_read_request_units: 100000
monthly_write_request_units: 100000
aws_api_gateway_rest_api.generate_id_unique:
monthly_requests: 100000
module.generate_id_unique.aws_cloudwatch_log_group.lambda[0]:
monthly_data_ingested_gb: 0.1
Et relançons infracost avec la commande infracost breakdown --path=. --usage-file infracost-usage.ymlpour estimer les coûts :
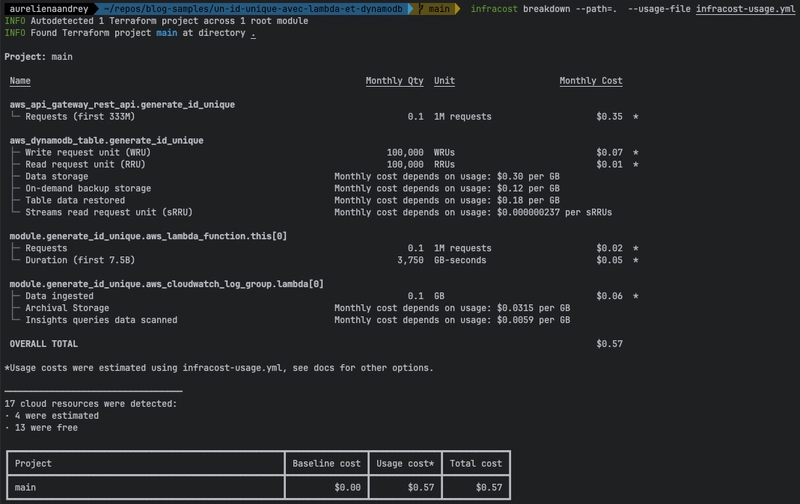
infracost nous donne cette fois un coût d'usage de 0.57$/mois, on peut dire que l'objectif est atteint !
Et l'augmentation est linéaire : si on fait x10 sur le nombre de requêtes et la taille du log group, le coût passe à 6$.
Comment sécuriser la route exposée par l'API Gateway ?
La sécurité est assurée par API Gateway : elle permet d'exposer la lambda et sécurise son appel en demandant une API Key. C'est ce code qui se charge de ça et notamment l'attribut api_key_required:
resource "aws_api_gateway_method" "generate_id_unique" {
rest_api_id = aws_api_gateway_rest_api.generate_id_unique.id
resource_id = aws_api_gateway_resource.generate_id_unique.id
http_method = "GET"
authorization = "NONE"
api_key_required = true
}
Tests de la solution
Tests manuels
Testons dans un premier temps avec Postman
- Commençons par vérifier la sécurité en appelant notre API sans fournir d'API Key
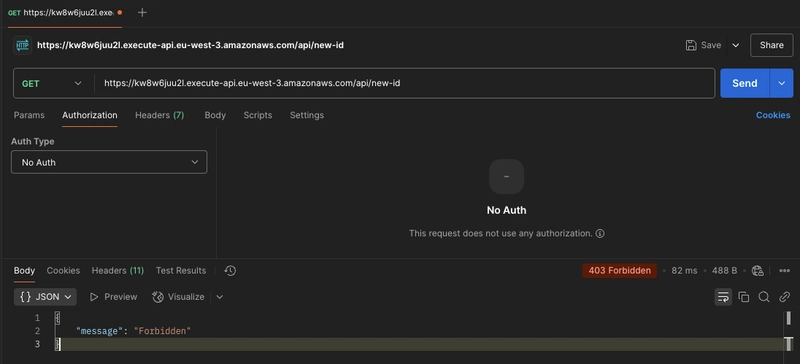
On reçoit un code d'erreur HTTP 403 qui est la valeur attendue.
- Rajoutons maintenant notre API Key pour vérifier que notre API fonctionne et retestons :
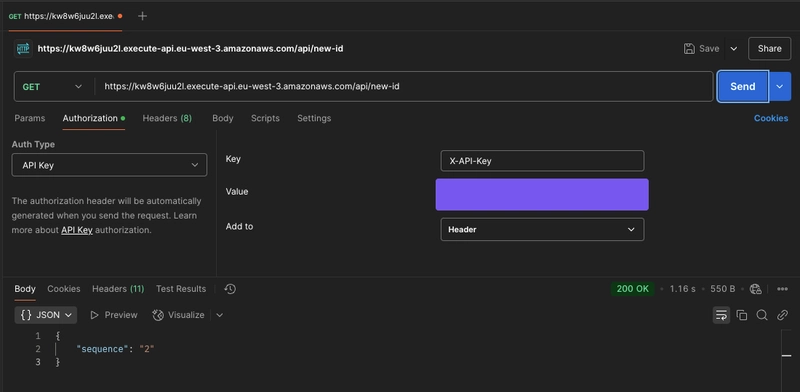
Cette fois, on reçoit un code HTTP 200 et la valeur de la séquence à utiliser (2 dans cette capture d'écran).
Tests de performances avec Locust
Notre API fonctionne de façon unitaire, parfait.
L'enjeu principal est désormais de vérifier que les accès concurrents sont bien gérés. Pour cela on va utiliser Locust, un framework de test de charge. Je ne rentre pas dans les détails d'installation ou de configuration de l'outil, je vous laisse consulter le site.
Nous allons créer une classe de test en python pour vérifier l'unicité des ids renvoyés : on va lancer en parallèle plein d'appels, on va récupérer tous les ids générés, et on va vérifier si on a des doublons
- Code de la classe
from locust import HttpUser, task, between, events
from collections import Counter
import os
all_ids_received = []
@events.test_stop.add_listener
def on_test_stop(environment, **kwargs):
counter = Counter(all_ids_received)
duplicates = [k for k, v in counter.items() if v > 1]
if duplicates:
print(f"Found duplicate IDs: {duplicates}")
else:
print("No duplicate IDs found!")
print(f"Total IDs received: {len(all_ids_received)}")
if all_ids_received:
print(f"Min ID: {min(all_ids_received)}")
print(f"Max ID: {max(all_ids_received)}")
class UniqueIdApiUser(HttpUser):
wait_time = between(1, 3)
api_key = os.environ.get('API_KEY', '')
def on_start(self):
if not self.api_key:
print("WARNING: API_KEY environment variable not set")
@task
def get_unique_id(self):
headers = {"X-API-Key": self.api_key}
with self.client.get("/api/new-id", headers=headers, catch_response=True) as response:
if response.status_code == 200:
try:
response_data = response.json()
unique_id = int(response_data.get('sequence', 0))
all_ids_received.append(unique_id)
print(f"Received ID: {unique_id}")
except ValueError:
response.failure("Failed to parse ID from response")
except Exception as e:
response.failure(f"Error processing response: {str(e)}")
else:
response.failure(f"HTTP Error: {response.status_code}, Response: {response.text}")
- On démarre notre serveur local locust avec la commande
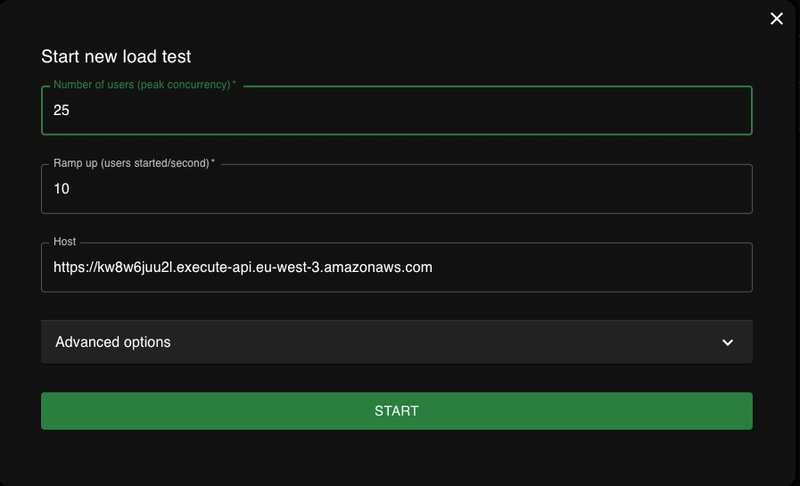
locust -f resource/tests/test-generate-id-unique.py --host https://kw8w6juu2l.execute-api.eu-west-3.amazonaws.comaprès avoir préalablement exporté notre API_KEY dans notre terminal - On accède à l'ihm pour paramétrer le test : 25 users en parallèle avec 10 users qui démarrent en même temps
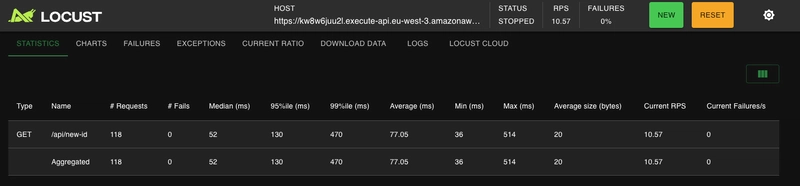
On laisse tourner un peu, voici le résultat dans Locust
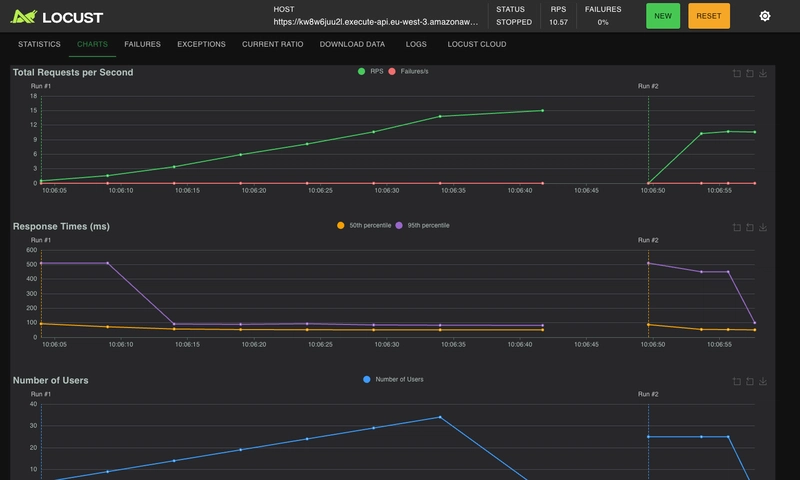
Et voici l'output de notre terminal :
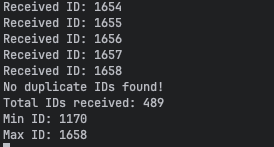
Pas d'id dupliqués et on constate bien les incréments qui sont réalisés: parfait !
Conclusion
Nous avons donc réussi à mettre en oeuvre une solution qui répond aux contraintes énoncées et nous l'avons validée :
- Unicité des id générés grâce à DynamoDB et les "Atomic counters"
- Nous l'avons vérifié grâce à l'outil de test de performances Locust
- Coût faible : en mettant en oeuvre une solution full serverless, nous bénéficions d'une facturation à l'usage : pour le cas de mon client (100 000 requêtes/mois) et même bien au-delà (1 000 000 requêtes/mois), nous avons avons une solution variant de quelques centimes de dollars à quelques dollars.
- Sécurité : en configurant correctement notre API Gateway, nous avons rajouté une couche d'authentification à notre API



