![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)
























































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)


























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)






























































































































Find the Closest Date Match for Each Record from Two Tables — From SQL to SPL #20
Problem description & analysis: SQL Server has two tables, Table1: Table2: Task: Now we need to sort Table1 by ID and traverse each record in sequence: retrieve the record in Table2 that has the same DocNum field as the current record, but with a slightly later time (the earliest among all later records). The special rule is that records taken from Table2 cannot be retrieved again next time. Code comparisons: SQL: WITH CTE1 As ( SELECT t1.ID, t1.JoiningDt, t1.DocNum, (SELECT TOP 1 ClosestDt FROM Table2 WHERE DocNum = t1.DocNum AND ClosestDt > t1.JoiningDt ORDER BY ClosestDt ASC ) ClosestDt FROM Table1 t1 ), CTE2 AS ( SELECT ID, JoiningDt, DocNum, ClosestDt , ROW_NUMBER() OVER(PARTITION BY DocNum, ClosestDt ORDER BY ID) rn FROM CTE1 ) SELECT ID, JoiningDt, DocNum, CASE WHEN rn = 1 then ClosestDt ELSE (SELECT ClosestDt FROM Table2 WHERE DocNum = c1.DocNum AND ClosestDt > c1.JoiningDt ORDER BY ClosestDt ASC OFFSET c1.rn -1 ROWS FETCH NEXT 1 ROWS ONLY) END as ClosestDt FROM CTE2 c1 Ordered calculations need to be performed here, especially to implement the rule that record cannot be retrieved again after being taken. SQL needs to create sequence numbers and flag bits, and multiple layers of nesting are used in conjunction with join statements to indirectly implement it. The code is cumbersome and difficult to understand; Using stored procedures would be relatively intuitive, but the code would be longer and the structure would become more complex. SPL: SPL can directly implement it according to business logic.

Problem description & analysis:
SQL Server has two tables, Table1:
Table2:
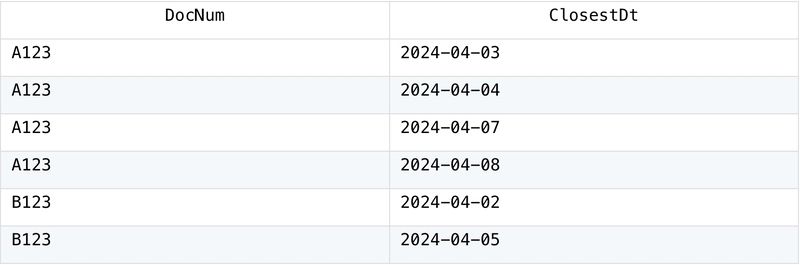
Task: Now we need to sort Table1 by ID and traverse each record in sequence: retrieve the record in Table2 that has the same DocNum field as the current record, but with a slightly later time (the earliest among all later records). The special rule is that records taken from Table2 cannot be retrieved again next time.

Code comparisons:
SQL:
WITH CTE1 As (
SELECT t1.ID, t1.JoiningDt, t1.DocNum,
(SELECT TOP 1 ClosestDt FROM Table2
WHERE DocNum = t1.DocNum AND ClosestDt > t1.JoiningDt ORDER BY ClosestDt ASC ) ClosestDt
FROM Table1 t1
), CTE2 AS (
SELECT
ID, JoiningDt, DocNum, ClosestDt
, ROW_NUMBER() OVER(PARTITION BY DocNum, ClosestDt ORDER BY ID) rn
FROM CTE1
)
SELECT ID, JoiningDt, DocNum,
CASE WHEN rn = 1 then ClosestDt ELSE
(SELECT ClosestDt FROM Table2
WHERE DocNum = c1.DocNum AND ClosestDt > c1.JoiningDt ORDER BY ClosestDt ASC
OFFSET c1.rn -1 ROWS FETCH NEXT 1 ROWS ONLY) END as ClosestDt
FROM CTE2 c1
Ordered calculations need to be performed here, especially to implement the rule that record cannot be retrieved again after being taken. SQL needs to create sequence numbers and flag bits, and multiple layers of nesting are used in conjunction with join statements to indirectly implement it. The code is cumbersome and difficult to understand; Using stored procedures would be relatively intuitive, but the code would be longer and the structure would become more complex.
SPL: SPL can directly implement it according to business logic.