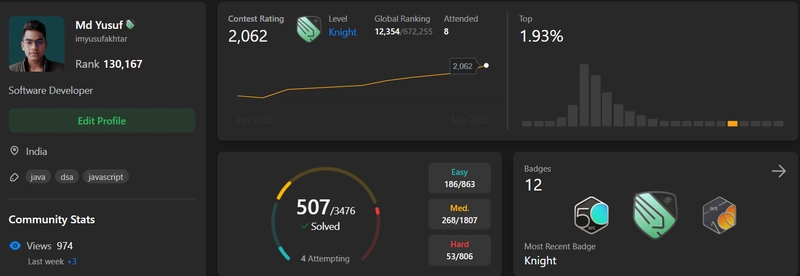
![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)


































































































































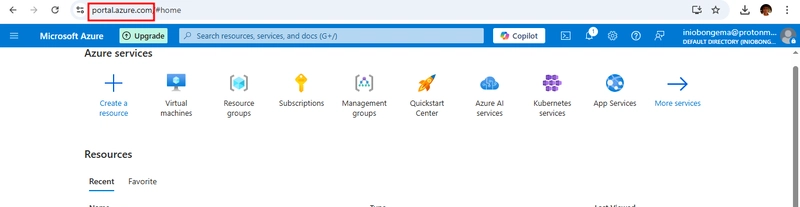
![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)










































































































.jpg?#)


































_ArtemisDiana_Alamy.jpg?#)


 (1).webp?#)


































































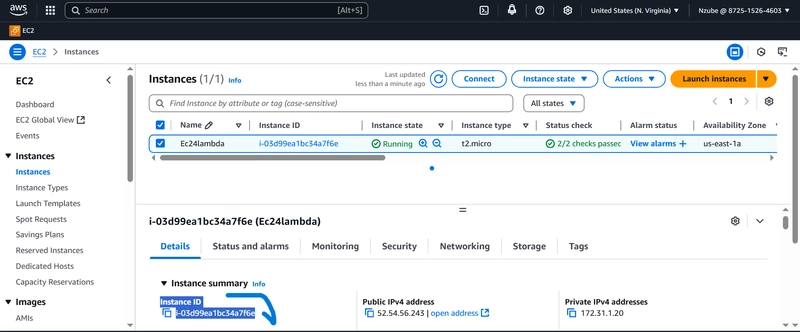
-xl.jpg)











![Yes, the Gemini icon is now bigger and brighter on Android [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/02/Gemini-on-Galaxy-S25.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Rushes Five Planes of iPhones to US Ahead of New Tariffs [Report]](https://www.iclarified.com/images/news/96967/96967/96967-640.jpg)
![Apple Vision Pro 2 Allegedly in Production Ahead of 2025 Launch [Rumor]](https://www.iclarified.com/images/news/96965/96965/96965-640.jpg)























































































































Consistency Patterns
If you’ve ever built or worked with a distributed system, you’ve probably asked: “How do I keep all my data in sync when it’s scattered across multiple servers?” Well, that’s where consistency patterns come in. First, What’s a Distributed System? A distributed system is basically a bunch of components running on different networked computers, all working together to achieve a common goal. Think of it as teamwork—each part plays its role, and together, they build something powerful. Example: In an e-commerce app, you might have: An account service A payment service An order service An inventory service A loyalty points service When a user buys a book, multiple services kick in. So how do we make sure they’re all on the same page (literally)? That’s where data consistency becomes critical. Why Does Consistency Matter? Let’s say two users try to buy the same last-copy book at the same time. If the inventory doesn’t update fast enough after the first order, both users might think the book is available. You can guess how that ends—not good for customer trust. Meet the Consistency Patterns There are three major patterns that define how data is kept consistent in distributed systems: 1. Strong Consistency Every read reflects the most recent write. All data copies are updated synchronously. You always see the latest state—no surprises. Example: A banking system where a fund transfer must reflect immediately on both accounts. No delays, no stale data. Accuracy over speed. Pros: High data integrity Cons: Higher latency, lower availability 2. Weak Consistency Reads may or may not reflect recent writes. Data may be inconsistent across nodes. Great for systems where speed matters more than precision. Example: In online multiplayer games, actions might appear instantly to nearby players but lag for others if there’s network delay. Pros: High availability, low latency Cons: Risk of data conflicts 3. Eventual Consistency A flavor of weak consistency—but with a promise. Eventually, all nodes will reflect the latest data. Updates are propagated asynchronously. Example: A social media post shows up instantly for users in the same data center, but may take a few seconds to appear globally. Pros: Good balance between availability and consistency Cons: Temporary inconsistencies So, Which Pattern Should You Choose? It depends on what your system needs: Strong Consistency → Use when accuracy is non-negotiable (e.g., finance). Weak Consistency → Use when speed is crucial and some delay is acceptable (e.g., games). Eventual Consistency → Use when you want scalability and availability, but can tolerate slight delays (e.g., social platforms).

If you’ve ever built or worked with a distributed system, you’ve probably asked:
“How do I keep all my data in sync when it’s scattered across multiple servers?”
Well, that’s where consistency patterns come in.
First, What’s a Distributed System?
A distributed system is basically a bunch of components running on different networked computers, all working together to achieve a common goal. Think of it as teamwork—each part plays its role, and together, they build something powerful.
Example:
In an e-commerce app, you might have:
- An account service
- A payment service
- An order service
- An inventory service
- A loyalty points service
When a user buys a book, multiple services kick in. So how do we make sure they’re all on the same page (literally)? That’s where data consistency becomes critical.
Why Does Consistency Matter?
Let’s say two users try to buy the same last-copy book at the same time.
If the inventory doesn’t update fast enough after the first order, both users might think the book is available. You can guess how that ends—not good for customer trust.
Meet the Consistency Patterns
There are three major patterns that define how data is kept consistent in distributed systems:
1. Strong Consistency
- Every read reflects the most recent write.
- All data copies are updated synchronously.
- You always see the latest state—no surprises.
Example:
A banking system where a fund transfer must reflect immediately on both accounts. No delays, no stale data. Accuracy over speed.
Pros: High data integrity
Cons: Higher latency, lower availability
2. Weak Consistency
- Reads may or may not reflect recent writes.
- Data may be inconsistent across nodes.
- Great for systems where speed matters more than precision.
Example:
In online multiplayer games, actions might appear instantly to nearby players but lag for others if there’s network delay.
Pros: High availability, low latency
Cons: Risk of data conflicts
3. Eventual Consistency
- A flavor of weak consistency—but with a promise.
- Eventually, all nodes will reflect the latest data.
- Updates are propagated asynchronously.
Example:
A social media post shows up instantly for users in the same data center, but may take a few seconds to appear globally.
Pros: Good balance between availability and consistency
Cons: Temporary inconsistencies
So, Which Pattern Should You Choose?
It depends on what your system needs:
- Strong Consistency → Use when accuracy is non-negotiable (e.g., finance).
- Weak Consistency → Use when speed is crucial and some delay is acceptable (e.g., games).
- Eventual Consistency → Use when you want scalability and availability, but can tolerate slight delays (e.g., social platforms).