![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)
















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)




































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)








































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)









![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)































































































































Cloudy Resumes
Put your resume in the cloud. Sounds simple. Easy enough, right? Well... maybe not so much. This project was the longest and definitely in the top ten most mentally taxing I've ever undertaken, with around 650 hours dedicated to it. I will preface this by saying that I am not a developer. I can develop when needed, to an extent, but it's not my field nor specialty. IT and cyber infrastructure engineering is where my skill set lies the most. In this field, oftentimes being able to script or program in some languages such as PowerShell and python is helpful, but not required, and I am usually not one to take the easy route. So, after finishing this Cloud Resume Project, with somewhere around 15K lines of code later... whew, that was a lot. Check out the Github repo over here! The Cloud Resume This spawned from the desire to expand my skill set and potentially move into a more cloud-based role. With next to no knowledge of any clouds beyond very basic theory, I set out to find some method or project that I could use to learn. After some searching, I came across the Cloud Resume Challenge. The Cloud Resume Challenge was designed and became fairly popular in 2020, especially as people were being forced to find ways to work from home. It seemed like a decent way to gain some practical experience in whichever major cloud provider I wanted. In my case, AWS. Cloud Resume Challenge's goal is to provide the reader with a bare bones framework or checklist of how to host one's resume in the cloud. For the project, it suggests the elements to be included are: Static webpage containing one's resume with a view counter API that the webpage can interface with to get and update view count Database to host the count CDN to host the website on Automated testing Automated infrastructure deployment Pretty simple in concept, but less so in reality. What this means is the person completing the challenge must perform (simplistic) full stack development, including front end, API, backend, storage, database, SSL certificates, IaC, and testing, all to be stored on a git repo. Evolution from single page to a manager As I was getting my three associate AWS certifications, the thought ran through my mind that this seemed more like a project for people starting out in IT or cloud. As someone with 15 years of experience under her belt, I didn't feel like it was ideal for me to "settle" for the bare minimum. "So," I asked myself, "What can I do to showcase more of my engineering skill set?" I pondered it for a day or two before it came to me. What if instead of sending a generic resume via URL, I send a link to a tailored resume for each company I applied to? With a smile on my face, I nodded. Seemed sufficiently complicated, yet doable. Now, I've seen over the years how much a project can grow out of hand, even without scope creep, so I refrained from patting myself on the back for such an idea. Oh goodness, did I not realize how correct a decision that was. Instead of the relatively simple architecture listed above, it turned into a fair bit more. Front end resume pages, front end authenticated manager, APIs and back ends for both, an OAuth2 server, a resume parser, storage for the parsed and unparsed resumes, databases for view counts and resume metadata, authentication validators, CDN, DNS, SSL certificates, website monitoring, permissions, automated testing, and IaC for all of it. Likely needless to say at this point, but to reiterate from earlier, for someone with no prior cloud experience, I bit off a lot. Front End There are two aspects to the resume manager's front end. Hosted resumes and the manager itself. Hosted Resume The hosted resumes portion is fairly simple. Each resume webpage hosts an equivalent of the resume docx file it spawned from, along with a view counter and a link to this blog at the bottom. Simple enough. Resume Manager The manager is fairly more complicated. First, it requires authentication, which I decided to go with AWS Cognito (Spoilers: never again). Once authenticated, the manager allows actions such as adding, modifying, re-uploading, deleting, restoring permanently deleting, and viewing metadata about one or more resumes. Not terribly complicated in comparison, but as a reminder, I am not a developer. I did not know JavaScript nor CSS going into this and I only had a rudimentary grasp of HTML. I'm certain any developer going through my JavaScript will be appalled at whatever technique is industry standard that I'm not using. But I'm not terribly worried about that. The point of this was not to show that I can be a full stack developer. Rather it was to show that I understand how development works and that I can create, interface with, manage, and destroy cloud resources that the applications or products utilize. Back End The back end is where things start to get more complicated. Least complicated is the hosted re
Put your resume in the cloud. Sounds simple. Easy enough, right? Well... maybe not so much.
This project was the longest and definitely in the top ten most mentally taxing I've ever undertaken, with around 650 hours dedicated to it. I will preface this by saying that I am not a developer. I can develop when needed, to an extent, but it's not my field nor specialty. IT and cyber infrastructure engineering is where my skill set lies the most. In this field, oftentimes being able to script or program in some languages such as PowerShell and python is helpful, but not required, and I am usually not one to take the easy route.
So, after finishing this Cloud Resume Project, with somewhere around 15K lines of code later... whew, that was a lot.
Check out the Github repo over here!
The Cloud Resume
This spawned from the desire to expand my skill set and potentially move into a more cloud-based role. With next to no knowledge of any clouds beyond very basic theory, I set out to find some method or project that I could use to learn. After some searching, I came across the Cloud Resume Challenge.
The Cloud Resume Challenge was designed and became fairly popular in 2020, especially as people were being forced to find ways to work from home. It seemed like a decent way to gain some practical experience in whichever major cloud provider I wanted. In my case, AWS.
Cloud Resume Challenge's goal is to provide the reader with a bare bones framework or checklist of how to host one's resume in the cloud. For the project, it suggests the elements to be included are:
- Static webpage containing one's resume with a view counter
- API that the webpage can interface with to get and update view count
- Database to host the count
- CDN to host the website on
- Automated testing
- Automated infrastructure deployment
Pretty simple in concept, but less so in reality. What this means is the person completing the challenge must perform (simplistic) full stack development, including front end, API, backend, storage, database, SSL certificates, IaC, and testing, all to be stored on a git repo.
Evolution from single page to a manager
As I was getting my three associate AWS certifications, the thought ran through my mind that this seemed more like a project for people starting out in IT or cloud. As someone with 15 years of experience under her belt, I didn't feel like it was ideal for me to "settle" for the bare minimum. "So," I asked myself, "What can I do to showcase more of my engineering skill set?"
I pondered it for a day or two before it came to me. What if instead of sending a generic resume via URL, I send a link to a tailored resume for each company I applied to? With a smile on my face, I nodded. Seemed sufficiently complicated, yet doable.
Now, I've seen over the years how much a project can grow out of hand, even without scope creep, so I refrained from patting myself on the back for such an idea.
Oh goodness, did I not realize how correct a decision that was.
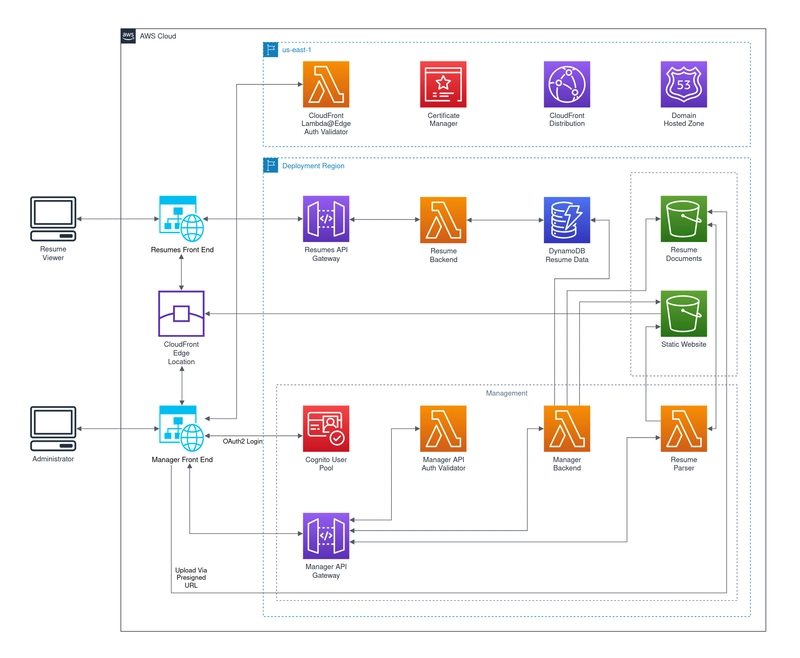
Instead of the relatively simple architecture listed above, it turned into a fair bit more. Front end resume pages, front end authenticated manager, APIs and back ends for both, an OAuth2 server, a resume parser, storage for the parsed and unparsed resumes, databases for view counts and resume metadata, authentication validators, CDN, DNS, SSL certificates, website monitoring, permissions, automated testing, and IaC for all of it.
Likely needless to say at this point, but to reiterate from earlier, for someone with no prior cloud experience, I bit off a lot.
Front End
There are two aspects to the resume manager's front end. Hosted resumes and the manager itself.
Hosted Resume

The hosted resumes portion is fairly simple. Each resume webpage hosts an equivalent of the resume docx file it spawned from, along with a view counter and a link to this blog at the bottom. Simple
enough.
Resume Manager
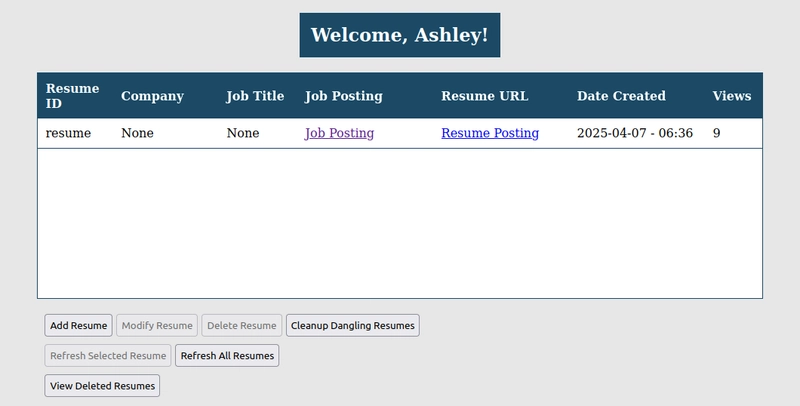
The manager is fairly more complicated. First, it requires authentication, which I decided to go with AWS Cognito (Spoilers: never again). Once authenticated, the manager allows actions such as adding, modifying, re-uploading, deleting, restoring permanently deleting, and viewing metadata about one or more resumes. Not terribly complicated in comparison, but as a reminder, I am not a developer. I did not know JavaScript nor CSS going into this and I only had a rudimentary grasp of HTML. I'm certain any developer going through my JavaScript will be appalled at whatever technique is industry standard that I'm not using.
But I'm not terribly worried about that. The point of this was not to show that I can be a full stack developer. Rather it was to show that I understand how development works and that I can create, interface with, manage, and destroy cloud resources that the applications or products utilize.
Back End
The back end is where things start to get more complicated.
Least complicated is the hosted resumes portion. It consists of CloudFront, S3 for the front end files, API Gateway, a Lambda function for retrieving/updating the view counter, and three DynamoDB tables. One table consisting of a single item with a single attribute: view_count. Another table is the resumes metadata table for the view count of the specific resume. And the final table stores a hash of the IP address of the viewer and which resume they viewed, for statistics. Not a terribly large amount going on, but it is worth noting that this alone--along with testing and IAC--was the intended product of the Cloud Resume Challenge.
The resume manager portion is where the majority of the complexity lies, which makes sense as it's interactable, as opposed to the solely viewable hosted resumes portion. The resources used here are CloudFront, Cognito, API Gateway, Lambda functions, S3, DynamoDB, and SNS.
CloudFront
Let's start with CloudFront. In order to restrict access, there has to be an authentication validator somewhere between the user and the origin. I decided to use Lambda@Edge as it was in the middle and was simple and easy, at least in theory. The most difficult, or rather time-consuming, portion of developing a Lambda@Edge function was testing it with the CloudFront distribution. Even though, it appeared to my human eyes that the request and response were what it seemed they should have been, every time there was an error, it was a five to ten minute wait between fix attempts. This is due to Lambda@Edge using function versions, which when a new version is used, that configuration must be populated to all CloudFront region edges.
In order to use a Lambda@Edge function for authentication, the client would first have to authenticated with a server, in this case, an OAuth2 server. I had never implemented an OAuth2 client before, so there were definitely some dues to be paid there. However, even after delving into and learning about how OAuth2 protocols worked, my naïve self, at the time, figured that AWS Cognito User Pools were an out-of-the-box, easy-to-use, OAuth2 solution.
Oh how wrong I was.
Cognito
There were so many little things that I ran into with attempting to implement Cognito. I won't get into too many of them, but from my experience, it's fairly clear that AWS does not prioritize Cognito User Pools user or the developer experience. Even something as simple as including the user's given name in the ID token was a chore. A chore that required a custom Lambda extension just for that, a pre-existing user attribute. I don't know if I will ever need to integrate OAuth2 into an application again, but if I do, I will absolutely choose another solution.
Moving on, once a user is authenticated and redirected to the manager portal, is when the rest of the back end comes into play.
API Gateway
The API Gateway and its Lambda integration for the manager was interesting to set up. That whole slice of the application went through a few revisions and was the cause of several romantic, candle-lit dinners between my face and a brick wall. Those were some bangers, really. One of the biggest "issues" I had was with CORS, or Cross Origin Resource Sharing. As someone new to web development, I had the fun experience of learning how even though the browser said it was a CORS issue, it almost always was most certainly not a CORS issue. The API Gateway's gateway responses were simply not including CORS headers. So, any 4XX-5XX errors were being sent back with no way for the browser to know that it was a safe, non-malicious transmission.
When I was initially developing the application in the AWS console--before I moved it all to CDK--API Gateway models were a pain as well. Any time I would export and import the API, all models would be stripped because the JSON schemas were too complex and API Gateway, or maybe its OpenAPI implementation, couldn't interpret it. Either way, it was quite the inconvenience.
In the early stages of the API, all of the integrations were not Lambda proxy types. This led for there to be an excessive need of mapping templates, of which I really did not want to dive into and learn, only to forget it six months down the road from disuse. Eventually, I decided to save myself some hassle and converted almost all of them to Lambda proxy integrations. This allowed the function itself to dictate what went into the body, headers, and params of the response. It simplified the that portion of the application, since the integration's response is always fairly simplistic.
Lambda Functions
Back to the manager back end, most of what it does is interface with the DynamoDB databases. Fetching, updating, deleting, etc. etc. But one other thing it does is generate pre-signed S3 URLs for the manager front end to upload a resume with. Those in themselves were quite a pain, as, since it's a pre-signed URL, the metadata of the request must match exactly to what was signed. AWS's documentation on how to use pre-signed URLs can hardly be called straightforward and not many people seem to be interested in that specific feature. In the end, I was able to get them working after many, many iterations of trial and error. Well, in all aspects except one. Much later in my development, I resorted using a curl command inside a Python script because I could not get the Python requests library to match whatever the signed URL wanted.
In any case, once the front end uploaded the resume docx file via the pre-signed url into an S3 bucket--which was another CORS nightmare that I'll get into in the CDK section--an S3 Notifications event would then trigger a Lambda function to convert the resume. This Lambda function is, admittedly, not one I am proud of, but it is one that works. For a very specific docx format, at least. I'm not happy that it can only process one format of docx, but when it came down to it, I had to decide what was worth the time and effort. At that point, I'd already had somewhere around 200-250 hours of work put into this project and I was very wary of scope creep. In the end, I decided to stick with my single style of resume, as it was much easier to process it than it was a range of resume formats. Though, even with "just" processing that one specific style, the docx-to-html converter still required nearly 1K lines of JavaScript.
Once that Lambda function finished converting the resume to html, there was another issue that didn't come up until final testing. This was due to a mistake of my own making, of which is... caching.
Cache Invalidation
During development, caching is not a developer's friend. When a webpage or script or CSS or font or any other file is updated on the server, no one wants to have to wait for cache to expire or to attach a header/metadata to the file for how long the object should be cached. So, I did the simplest thing: disable CloudFront caching.
Even though I'd put big, in-your-face print statements on the CDK deployment, it didn't register. I'd gotten so used to seeing CLOUDFRONT CACHING DISABLED FIX ME LATER that they'd become a familiar, friendly sight. by the time I realized it was an issue, everything was essentially feature complete. So, I enabled it, ran my tests, and... huh, why are these four PyTest tests failing all the sudden?
Turns out, caching is kind of a big deal when a webpage gets updated. Slightly demoralized and nearing the 600 hour mark, I pulled on my big girl undies and dove in. One of the more common solutions I found was to use different file names altogether, when updating a file. Well, that wouldn't work without some significant refactoring. The plan was to give a potential employer a direct link to a resume. To use this cache update method would require that link to redirect to whatever the latest version of the resume would be. While certainly a potentially ideal solution, my heart was simply not into diving back in and implementing changing such a large change.
Eventually, I settled on a relatively less ideal solution of using cache invalidation. There were some changes to be made along with a new Lambda function that would invalidate and wait for the invalidation to complete, but it was nowhere near as involved as redirecting. What makes it less ideal is that AWS always gives 1000 free cache invalidations per month at the account level. After that, they cost $0.005 per invalidation. Which, to some, may sound like a very slight amount, but a mere 200 invalidations would cost $1. For any website with a decent amount of traffic, that can add up fast. The reason I settled on that is because this is a project that the administrator--me--will be specifically choosing when something gets invalidated. In the case that it does go above the account limit, it's a very low cost. In fact, when I was troubleshooting PyTest with the invalidation solution, the most I racked up was around $11-worth.
In a corporate setting, where hundreds, thousands, or more users might cause a need for cache invalidation, I would never suggest using such a thing. It's a thorough waste of money when there are far more reasonable methods.
For the remaining manager back end resources, DynamoDB and SNS were fairly straightforward. I had a few issues with Boto3 and DynamoDB, but nothing more noteworthy than one AWS API documentation being outdated.
CDK
Cloud Development Kit. This was an... adventure to learn. I've done a decent amount in Ansible and a small bit in Terraform, but I've never used a programmatic IaC. This was a monumental task, and I will freely admit that my implementation of it made it far more painful.
Implementation
For the last couple of years, I've been on a config file stint. Config files can allow for a more modular program, but they can also get out of hand quite quickly. My thought process for CDK was to create a modular implementation, one that could potentially be reused for some future, nebulous AWS project. My poor, thoroughly naïve self had no idea what kind of undertaking that would be. An undertaking that I discovered is simply not worth it in so many scenarios. But, by the time I'd realized a config file-based CDK approach wasn't such a hot idea, I was already around 2K lines of Python CDK deep and 4.5K lines of JSON.
The sunk cost fallacy rooted itself deep in me.
But I pushed through and the solution works, even if it cost me many more hours than I would have liked. So, will I ever reuse this code for that nebulous, imaginary, future AWS project? No. Just a hard no. But am I glad I did it this way? Actually... yes. I am.
When it comes to any new platform, solution, tool, or language, there will always be dues to pay. While this method did take longer and have many more cracks and bumps to trip over--and goddesses did I trip over a lot of them--I learned a ton. I'd wager I learned about as much as what shouldn't be done as what should be.
As it stands, there are many things I'm not happy about with how I wrote this project's CDK. Each module is not quite as independent or modular as I would like, but the amount of effort to make them fully modular was more trouble than it was worth, especially for something I'm likely to never attempt again.
CDK Dependencies
One of the things I didn't quite understand going in were resource and stack dependencies in CloudFormation. Early on, I ran into a lot of cyclical dependencies because I couldn't quite initially grasp the concept of how resources depended on one another within CloudFormation. Even later on, maybe a third of the way through my development of the CDK, cross-stack dependencies still tripped me up. I ended up scrapping any of use CDK's built-in IAM permissions grants because too many things I needed to grant permissions to were in different stacks, if not in different regions. The same went for Lambda functions. It was easier to import a reference to another stack's function than it was to try to work around the cross-stack references and the minefield of cyclical dependencies that came with it.
Custom Resources
One of the features I'd wanted to include from the very conception of this project was to use placeholders in any of the functions that needed to reference AWS resources. What I didn't realize at the time was how much effort it would take to implement that. My thought was that I'd use something--a custom resource, I'd later learned--to update the values post-deployment. That wasn't too terribly difficult to implement, but it didn't click until after I'd finished, that any resource that referenced a numeric version of the function would have to be updated to point to a newer version. This is not something that CloudFormation can facilitate on its own. That spawned the need for custom resources to update both API Gateway integrations and CloudFront Lambda@Edge behavior associations.
On top of those custom resources, CDK's Route53 isn't quite all that useful for interacting with existing hosted zones, especially ones in different accounts. That led to needing a custom resource to create and delete DNS records. And since Certificate Manager requires DNS records to be created on-the-spot, SSL certificates for CloudFront, Cognito, and API Gateway had to have their own custom resource to create, validate, and destroy certificates.
Then there's the very common empty bucket custom resource to delete all S3 objects before a bucket can be destroyed.
S3 Buckets
Speaking of buckets, I ran into an issue that took me quite a while to track down. During manual testing, I never ran into the problem, but once I moved to automated testing, it reared its head. The tests would successfully create an environment from scratch in a test account, run the tests, then destroy it, but the S3 pre-signed URLs the manager used to upload a resume docx file started just... not working. But only sometimes. In the browser it would present as, surprise surprise, a CORS error. After I'd confirmed all of the CORS configuration, I decided to run the pre-signed URL through curl. Turns out it wasn't a CORS issue--gasp!--but rather a somewhat perplexing 307 temporary redirect. It stated that the given URL should be used in the future, but for now, the user should redirect to [bucket].s3.[region].amazonaws.com.
No one on Google seemed to have an answer, including a couple re:Post questions stating the same issue. After a bunch of trial and error testing, I found out that after around 30 minutes to an hour after the environment was created, the original link worked. Sure enough, every time, as long as I waited that time frame, it would work, no problem. To confirm my suspicions, I changed the bucket deployment location to us-east-1, and there were no issues.
From what I can tell, s3.amazonaws.com exists in us-east-1, so any time a standard bucket URL is used, it goes to us-east-1, which then redirects internally to the bucket's actual region, assuming it's hosted elsewhere. However, it appears to take a little time for other regions to propagate data about their buckets to S3 in Northern Virginia, which thusly causes a temporary redirect.
Unfortunately, there's literally nothing that can be done on the front end to get around this. Not only can the client not read the redirect or even the status code thanks to the response not having CORS headers, but even if that temporary redirect is used, AWS rejects it. Pre-signed URLs include the full URL as part of the signature, which means redirecting to the new URL invalidates it. Boto3 also cannot generate a pre-signed URL for anything other than [bucket].s3.amazonaws.com. The only solution is to wait until the bucket's existence propagates to Northern Virginia.
Automated Testing
I've had some experience in PyTest before, so I knew writing a test framework was going to be an Ordeal™. Unfortunately, I had not had experience with web testing, nor with Selenium, the web driver I ended up settling on.
Web Drivers
The biggest issues I had was with two drivers in particular: Firefox and Safari.
Firefox, specifically, granted me two dinner dates between my face and a wall. First was scrolling. Firefox does not implement scroll_to_element the same way everyone else does. Instead move_to_element has to be used. That one took an embarrassingly long time to narrow down. Except that's not quite the whole story. In an HTML table, there are elements nested within it, most commonly The second dinner date was uploading files via Safari. When selecting a file programmatically, one cannot (easily) open a dialog box, navigate to the file, and click open. Instead, the path is given directly to an I said it earlier about CDK, but this whole project was an adventure. From figuring out what to use to learn cloud, to getting my AWS certs, to creating the relatively small website, to integrating everything with CDK and CI/CD. It's one of the accomplishments I'm most proud of. Even though I had a lot of background IT knowledge that helped me put the pieces together, I still knew next to nothing about AWS or cloud going in.
Now though? I can confidently say if I were given a professional project in AWS, I could see it through from start to finish.
I can't wait to see what's next.
[data] (table row) element, there would be no problem. But with Firefox? It does nothing. You instead have to scroll to the (table data, or cell) element. But be careful! If the table has headers, sometimes it will scroll too far and the cell will be hidden behind the header, which makes clicking it impossible.
element of type file. In Safari, this works fine, but then the driver simply won't upload it. Turns out this is a feature that is not, and is not planned to be, implemented in the Safari driver. I could have rewritten a lot of the testing to allow for secondary driver to do the uploading while Safari runs the rest of the tests, but a rather significant number of tests require uploading as part of its functionality test. To remove those tests altogether would leave a somewhat pitiful number remaining and I deemed it simply not worth it.
Putting it all Together