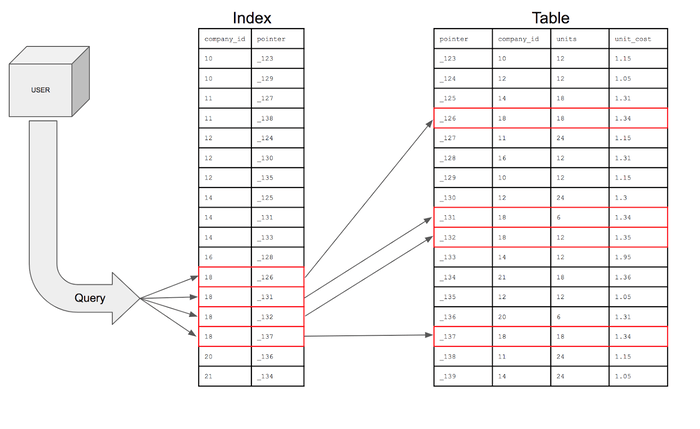
![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)













































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)








































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)








































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)





























































































































Tiny Video AI: 3B Model Rivals Giants, Shows "Aha!" Moments
This is a Plain English Papers summary of a research paper called Tiny Video AI: 3B Model Rivals Giants, Shows "Aha!" Moments. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Why Smaller Video Reasoning Models Matter: Introducing TinyLLaVA-Video-R1 Recent advances in large multimodal models (LMMs) have demonstrated significant reasoning capabilities. However, most research focuses on large-scale models (7B+ parameters) or image-only reasoning tasks, leaving a critical gap for researchers with limited computational resources. TinyLLaVA-Video-R1 addresses this gap by showing that small-scale models can develop strong reasoning abilities through reinforcement learning on general Video-QA datasets. The research proves that smaller models not only effectively reason about video content but also exhibit emergent "aha moment" characteristics - showing reflection and self-correction during the reasoning process. This represents a significant advancement for resource-constrained AI research environments. A case of TinyLLaVA-Video-R1 on video understanding data from MVBench, showing scene perception, option analysis, and reflective behavior (highlighted in blue). Background: Video Reasoning in the Context of LLM Advances Recent years have seen remarkable progress in large language reasoning models through reinforcement learning. Models like DeepSeek-R1 and Kimi K1.5 have demonstrated that the Group Relative Policy Optimization (GRPO) algorithm with rule-based rewards can significantly enhance reasoning capabilities while reducing computational costs. These advancements have sparked interest in multimodal reasoning, with researchers observing intriguing phenomena like "aha moments" where models demonstrate self-reflection. Despite this progress, multimodal reasoning remains concentrated in two areas: image-based reasoning and large-scale video models. Most existing work on video reasoning, such as Video-R1, focuses on models with at least 7B parameters and argues that small-scale models cannot produce effective reasoning processes. This leaves a significant gap in understanding how reinforcement learning affects reasoning in small LLMs, particularly for video understanding tasks which present unique challenges due to their temporal nature. A case of TinyLLaVA-Video-R1 on video reasoning data from MMVU, showing comprehensive video understanding and analytical reasoning capabilities. Building TinyLLaVA-Video-R1: A Technical Approach The Foundation: TinyLLaVA-Video Architecture TinyLLaVA-Video-R1 builds upon TinyLLaVA-Video, a fully open-source small-scale video understanding model that employs Qwen2.5-3B as its language model and SigLIP as its visual encoder. A key advantage of this foundation is its transparency and traceability - both the training data and process are fully open-sourced, preventing uncontrolled variables from repeated use of identical data across different training phases. This ensures more reliable experimental results compared to models that only release weights. Cases of "aha moment" from MVBench and MMVU, where TinyLLaVA-Video-R1 demonstrates reflection and backtracking during reasoning (highlighted in blue). Optimizing Reasoning: The GRPO Algorithm The research implements the Group Relative Policy Optimization (GRPO) algorithm for training. For each question, the policy model generates multiple candidate responses and computes corresponding rewards based on predefined rules. These rewards are normalized to calculate advantages for each response, and the model is optimized through a specialized objective function. To address an issue where responses with equal rewards receive zero advantage (reducing sample efficiency), the researchers added gaussian noise to the advantages. This small modification ensures intra-group advantage diversity across responses, maximizing the utility of each training sample. Training Data Selection and Prompt Engineering The research team selected multiple-choice questions from the NextQA subset of LLaVA-Video-178K as training data. To manage computational demands, they limited training to 5,496 samples with video durations between 0-30 seconds. While NextQA is considered a "weak reasoning" dataset with more perception-oriented questions, the researchers hypothesized that reasoning abilities would emerge primarily from the reinforcement learning process itself. The training prompt included specific instructions: "Output the thinking process in and final answer (option) in tags." This structure encouraged the model to articulate its reasoning process separately from its final answer. Designing Effective Reward Rules The reward structure includes two components: Format reward: A base reward for adhering to the required response format, plus a continuous length reward to encourage longer, more detailed reasoning. Accuracy reward: Bas
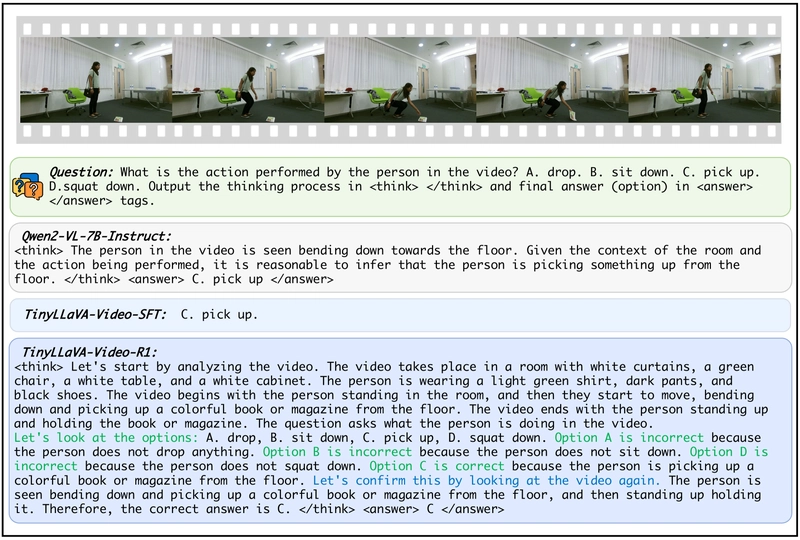
This is a Plain English Papers summary of a research paper called Tiny Video AI: 3B Model Rivals Giants, Shows "Aha!" Moments. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Why Smaller Video Reasoning Models Matter: Introducing TinyLLaVA-Video-R1
Recent advances in large multimodal models (LMMs) have demonstrated significant reasoning capabilities. However, most research focuses on large-scale models (7B+ parameters) or image-only reasoning tasks, leaving a critical gap for researchers with limited computational resources. TinyLLaVA-Video-R1 addresses this gap by showing that small-scale models can develop strong reasoning abilities through reinforcement learning on general Video-QA datasets.
The research proves that smaller models not only effectively reason about video content but also exhibit emergent "aha moment" characteristics - showing reflection and self-correction during the reasoning process. This represents a significant advancement for resource-constrained AI research environments.
A case of TinyLLaVA-Video-R1 on video understanding data from MVBench, showing scene perception, option analysis, and reflective behavior (highlighted in blue).
Background: Video Reasoning in the Context of LLM Advances
Recent years have seen remarkable progress in large language reasoning models through reinforcement learning. Models like DeepSeek-R1 and Kimi K1.5 have demonstrated that the Group Relative Policy Optimization (GRPO) algorithm with rule-based rewards can significantly enhance reasoning capabilities while reducing computational costs. These advancements have sparked interest in multimodal reasoning, with researchers observing intriguing phenomena like "aha moments" where models demonstrate self-reflection.
Despite this progress, multimodal reasoning remains concentrated in two areas: image-based reasoning and large-scale video models. Most existing work on video reasoning, such as Video-R1, focuses on models with at least 7B parameters and argues that small-scale models cannot produce effective reasoning processes. This leaves a significant gap in understanding how reinforcement learning affects reasoning in small LLMs, particularly for video understanding tasks which present unique challenges due to their temporal nature.

A case of TinyLLaVA-Video-R1 on video reasoning data from MMVU, showing comprehensive video understanding and analytical reasoning capabilities.
Building TinyLLaVA-Video-R1: A Technical Approach
The Foundation: TinyLLaVA-Video Architecture
TinyLLaVA-Video-R1 builds upon TinyLLaVA-Video, a fully open-source small-scale video understanding model that employs Qwen2.5-3B as its language model and SigLIP as its visual encoder. A key advantage of this foundation is its transparency and traceability - both the training data and process are fully open-sourced, preventing uncontrolled variables from repeated use of identical data across different training phases. This ensures more reliable experimental results compared to models that only release weights.

Cases of "aha moment" from MVBench and MMVU, where TinyLLaVA-Video-R1 demonstrates reflection and backtracking during reasoning (highlighted in blue).
Optimizing Reasoning: The GRPO Algorithm
The research implements the Group Relative Policy Optimization (GRPO) algorithm for training. For each question, the policy model generates multiple candidate responses and computes corresponding rewards based on predefined rules. These rewards are normalized to calculate advantages for each response, and the model is optimized through a specialized objective function.
To address an issue where responses with equal rewards receive zero advantage (reducing sample efficiency), the researchers added gaussian noise to the advantages. This small modification ensures intra-group advantage diversity across responses, maximizing the utility of each training sample.
Training Data Selection and Prompt Engineering
The research team selected multiple-choice questions from the NextQA subset of LLaVA-Video-178K as training data. To manage computational demands, they limited training to 5,496 samples with video durations between 0-30 seconds. While NextQA is considered a "weak reasoning" dataset with more perception-oriented questions, the researchers hypothesized that reasoning abilities would emerge primarily from the reinforcement learning process itself.
The training prompt included specific instructions: "Output the thinking process in and final answer (option) in tags." This structure encouraged the model to articulate its reasoning process separately from its final answer.
Designing Effective Reward Rules
The reward structure includes two components:
Format reward: A base reward for adhering to the required response format, plus a continuous length reward to encourage longer, more detailed reasoning.
Accuracy reward: Based on whether the extracted answer matches the correct label.
Crucially, the researchers introduced a penalty for incorrect answers. When the model answers correctly, longer reasoning leads to higher rewards. However, when incorrect, longer reasoning results in higher penalties. This approach discourages the model from generating lengthy but inaccurate reasoning and focuses it on quality rather than quantity.
Experimental Validation and Key Findings
Setup and Evaluation Methodology
Experiments were conducted on 8 NVIDIA A100-40G GPUs with the vision encoder frozen while updating the connector and language model. To ensure training stability, the researchers first fine-tuned the model using 16 human-annotated cold-start samples (creating TinyLLaVA-Video-ColdStart), then used this as the base for reinforcement learning.
Evaluation used four video understanding and reasoning benchmarks spanning multiple domains and video durations: MVBench, VideoMME, MLVU, and MMVU.
Performance Analysis and Emergent Reasoning Behavior
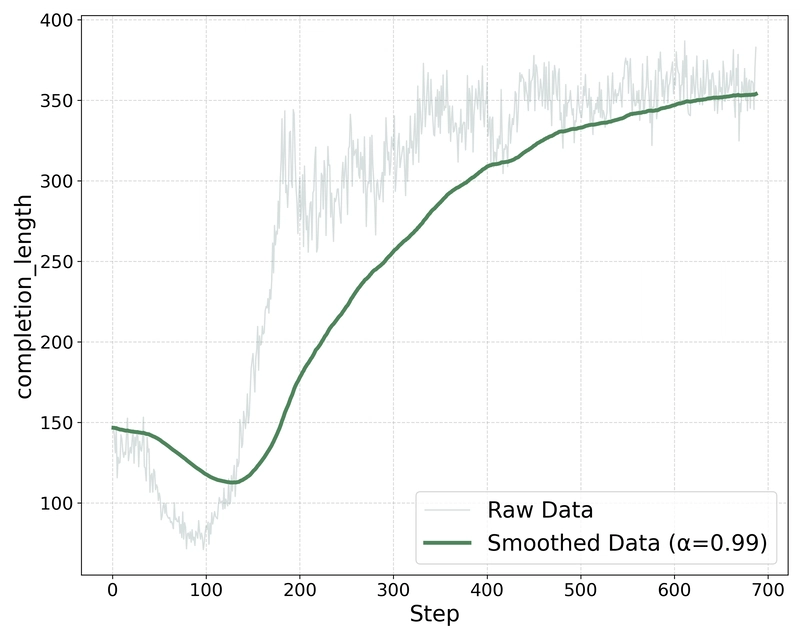
Evolution in completion length during training, showing steady growth as the model learns to provide more detailed reasoning.
The results demonstrate that TinyLLaVA-Video-R1 not only outperforms its supervised learning counterpart (TinyLLaVA-Video-SFT) across all benchmarks, but also exceeds many larger models with 7-8B parameters while providing reasoning processes rather than just answers.
| Model | LLM size | Answer Type | MVBench | Video-MME (wo sub) | MLVU | MMVU (mc) |
|---|---|---|---|---|---|---|
| LLaMA-VID [10] | 7B | Option | 41.4 | - | 33.2 | - |
| LLaVA-NeXT [12] | 7B | Option | - | - | 39.3 | 29.2 |
| VideoLLaVA [11] | 7B | Option | - | 39.9 | 47.3 | - |
| ShareGPT4Video [2] | 8B | Option | - | 39.9 | 46.4 | - |
| LLaVA-Mini [26] | 7B | Option | 44.5 | - | 42.8 | - |
| InternVideo2 [22] | 8B | Option | - | 41.9 | - | 39.0 |
| TinyLLaVA-Video-SFT | 3B | Option | 49.0 | 42.2 | 49.2 | 46.1 |
| TinyLLaVA-Video-ColdStart | 3B | Reason | 33.2 | 26.6 | 28.6 | 22.7 |
| TinyLLaVA-Video-R1 | 3B | Reason | 49.5 | 46.6 | 52.4 | 46.9 |
Performance comparison across models. TinyLLaVA-Video-R1 outperforms both its SFT counterpart and many larger models despite having fewer parameters and providing reasoning processes.
Perhaps more significantly, the model exhibited the emergent "aha moment" phenomenon similar to what has been observed in larger models. During reasoning, TinyLLaVA-Video-R1 demonstrated self-verification, reflecting on its initial thoughts and sometimes revising its reasoning path. This behavior indicates that the model engages in continuous thinking and self-checking, not merely perception-based responses.
This finding contradicts previous assertions that small-scale models cannot produce effective reasoning processes, as seen in works like VILLA and others that focus exclusively on larger models.
Crucial Components for Success: Ablation Studies
The Value of Cold-Start Data
Without cold-start data, the researchers observed that small-scale models tend to learn "shortcuts" - while adhering to the required format, they would omit the reasoning process entirely, producing responses structured as
This finding suggests that cold-starting is essential for developing reasoning capabilities in small-scale models, with even minimal guidance significantly stabilizing the training process.
Optimizing Response Length through Reward Design
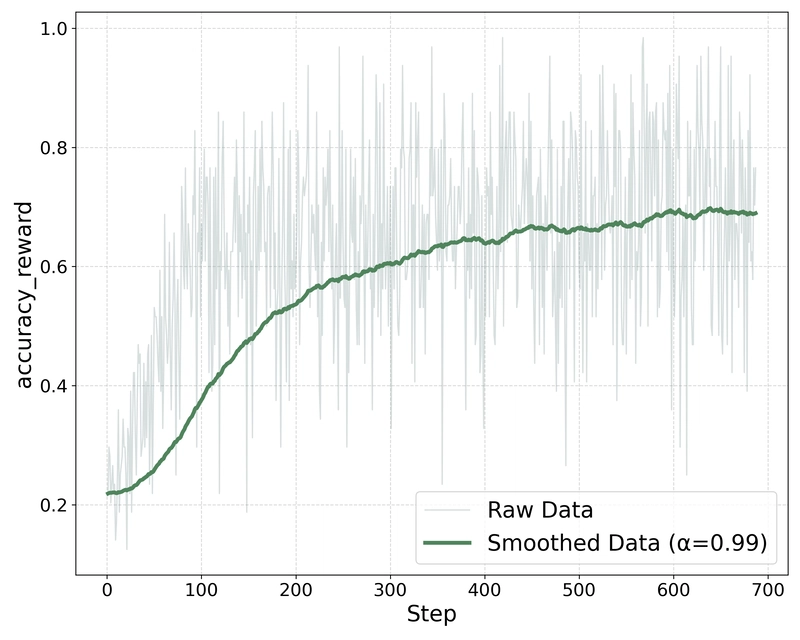
The variation in response length during training under different reward settings, showing how the continuous length reward component influences model behavior.
The researchers found that standard format rewards alone did not lead to increased response length in small models - and in some cases even reduced it. After introducing continuous length rewards, response length increased significantly, but the quality varied, with some models generating meaningless text just to increase length.
The breakthrough came from incorporating answer correctness penalties in the total reward. This modification led to both qualitative improvements in model responses and sustained growth in output length throughout training, suggesting the model was learning to reason more effectively rather than simply generating longer outputs.
Technical Optimization Experiments
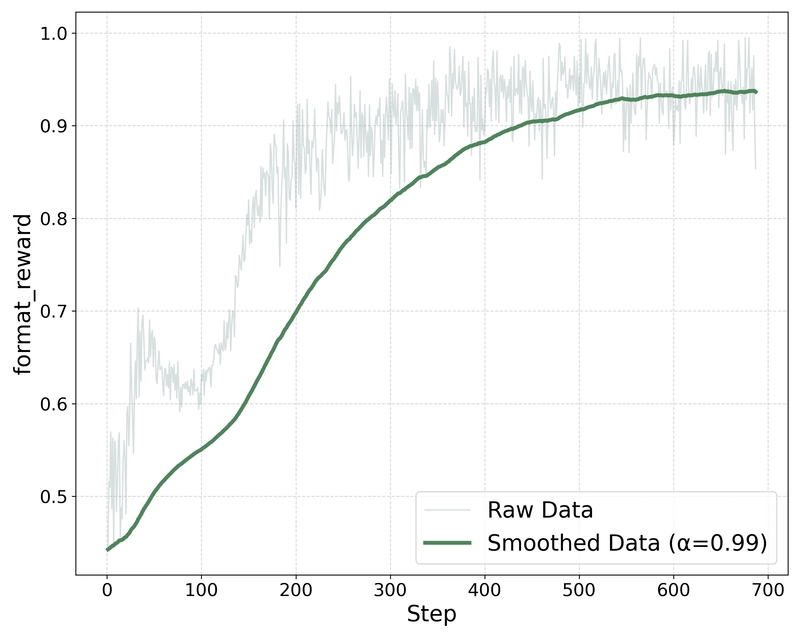
Ablation study comparing TinyLLaVA-Video-R1 with variants: one removing the KL divergence term (Del KL) and another replacing GRPO with Dr. GRPO, showing performance differences across benchmarks.
Additional experiments explored modifications to the GRPO algorithm itself. Removing the KL divergence term (which constrains the model's distribution to remain close to the reference model) improved performance, suggesting that reasoning models benefit from greater freedom to diverge from their initial distribution.
Further experiments with Dr. GRPO (which removes response length and reward variance terms from calculations) showed additional performance improvements, though with shorter responses focused more on video description than deep analysis. The researchers attribute this to the weak reasoning content in the training dataset, which failed to stimulate deeper logical reasoning.
Future Directions: What's Next for Small Video Reasoning Models
TinyLLaVA-Video-R1 opens important new territory for researchers with limited computational resources. By demonstrating that small-scale models can develop robust reasoning abilities through reinforcement learning, even on general video question-answering datasets, the work challenges assumptions about the minimum model size needed for effective reasoning.
Two key directions for future research emerge:
Introducing high-quality video reasoning data: TinyLLaVA-Video-R1 was trained only on general video question-answering data with limited reasoning complexity. Exploring the upper limits of small models' reasoning capabilities will require developing or adapting higher-quality video reasoning datasets specifically designed to stimulate logical reasoning.
Improving reinforcement learning algorithms: While GRPO proved effective, the research identified several limitations. Future work should focus on refining algorithms specifically for video reasoning tasks, addressing challenges unique to small-scale models in this domain.
By tackling these challenges, researchers can further democratize access to advanced AI capabilities, making video reasoning models accessible to a broader community of researchers and developers.