










































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)



































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.jpg?#)

































_ArtemisDiana_Alamy.jpg?#)


 (1).webp?#)








































































-xl.jpg)












![Yes, the Gemini icon is now bigger and brighter on Android [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/02/Gemini-on-Galaxy-S25.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Rushes Five Planes of iPhones to US Ahead of New Tariffs [Report]](https://www.iclarified.com/images/news/96967/96967/96967-640.jpg)
![Apple Vision Pro 2 Allegedly in Production Ahead of 2025 Launch [Rumor]](https://www.iclarified.com/images/news/96965/96965/96965-640.jpg)
























































































































Building Unstoppable Systems: Go 1.22 and Temporal's Durable Execution Revolution
Enterprise systems fail. And when they do, they fail spectacularly. According to Gartner's 2025 Distributed Systems Reliability Report, the average Fortune 500 company experiences 43 hours of critical service disruption annually, costing an average of $1.2M per hour. That's $51.6M yearly—gone. Not from malicious attacks but from something far more mundane: distributed systems that simply couldn't recover from unexpected state transitions. What if your architecture could survive literally anything? Database failures. Network partitions. Entire regional outages. In this article, I'll show you how the convergence of Go 1.22's type system enhancements and Temporal's durable execution framework has fundamentally rewritten the reliability equation for enterprise cloud systems in 2025. The New Reliability Imperative As developers, we're facing a perfect storm of reliability challenges. Microservice proliferation has increased failure domains exponentially. Cloud provider SLAs cover infrastructure but not your business logic. And regulations across healthcare, finance, and energy now require 99.999% reliability with complete auditability—five minutes of total allowable downtime per year. The most expensive line of code is the one that silently fails in production. Traditional reliability approaches are like insurance policies that still leave you homeless after a disaster. What we need instead are self-healing structures that remain livable no matter what storm hits them. Traditional solutions fall desperately short: Retries and circuit breakers → handle transient failures but not logical corruption Message queuing → guarantees delivery but not processing Event sourcing → preserves state but doesn't automate recovery Kubernetes → restarts containers but can't resume stateful workflows The missing piece has always been execution durability: the ability to make a complex business process indestructible across time, space, and failure modes. When building modern distributed systems, reliability engineering often consumes 60% of development time—writing retry logic, implementing compensating transactions, and building complex state machines. With the patterns described in this article, that number typically drops to about 15%, freeing developers to focus on actual business logic. The shift isn't just in time allocation but in mindset—moving from defensive programming to productive innovation. Go 1.22 Workflow-Ready Language Features Go 1.22 introduced several key enhancements that make it particularly well-suited for durable execution patterns. The most impactful are structured type parameters with enhanced constraints, the new comparable interface improvements, and loop variable capture semantics that eliminate a class of race conditions in asynchronous workflow code. For junior developers, think of Go 1.22's type system enhancements as creating a "contract" that ensures your workflows behave consistently. The compiler catches errors before they reach production, which is a game-changer for reliability. For more senior developers, these generic constraints allow us to create truly type-safe workflows while maintaining complete flexibility in our business logic. The compiler now helps prevent entire classes of errors that would previously only manifest in production. Go 1.22's garbage collector enhancements have also significantly reduced the memory footprint of long-running workflows. In a real-world e-commerce platform implementation, this optimization alone allowed the system to handle over 3x more workflow executions on the same hardware. The more efficient memory usage translates directly to lower cloud costs and higher throughput. Go's error handling has also been transformed with the introduction of structured error groups that maintain causal relationships. This capability is transformative for workflow reliability, as it allows precise handling of different failure modes while maintaining the full context of what went wrong. In simpler terms, it helps you understand not just that something failed, but exactly why and how it failed, making it much easier to implement robust recovery strategies. Temporal Nexus Enterprise-Grade Orchestration Temporal's 2025 "Nexus" release has established it as the de facto standard for durable execution. When combined with Go 1.22, it creates what many consider the most resilient application architecture currently achievable. The Temporal paradigm shift is revolutionary for critical workflows like payment processing that might occasionally fail during the final confirmation step, leaving systems in an inconsistent state. With Temporal, these issues disappear. The workflow simply resumes exactly where it left off, even days later, completing the transaction as if nothing had happened. It's like discovering a superpower—systems can now bend time itself. Temporal fundamentally inverts the traditional reliability model:
Enterprise systems fail. And when they do, they fail spectacularly. According to Gartner's 2025 Distributed Systems Reliability Report, the average Fortune 500 company experiences 43 hours of critical service disruption annually, costing an average of $1.2M per hour. That's $51.6M yearly—gone. Not from malicious attacks but from something far more mundane: distributed systems that simply couldn't recover from unexpected state transitions.
What if your architecture could survive literally anything? Database failures. Network partitions. Entire regional outages. In this article, I'll show you how the convergence of Go 1.22's type system enhancements and Temporal's durable execution framework has fundamentally rewritten the reliability equation for enterprise cloud systems in 2025.
The New Reliability Imperative
As developers, we're facing a perfect storm of reliability challenges. Microservice proliferation has increased failure domains exponentially. Cloud provider SLAs cover infrastructure but not your business logic. And regulations across healthcare, finance, and energy now require 99.999% reliability with complete auditability—five minutes of total allowable downtime per year.
The most expensive line of code is the one that silently fails in production. Traditional reliability approaches are like insurance policies that still leave you homeless after a disaster. What we need instead are self-healing structures that remain livable no matter what storm hits them.
Traditional solutions fall desperately short:
- Retries and circuit breakers → handle transient failures but not logical corruption
- Message queuing → guarantees delivery but not processing
- Event sourcing → preserves state but doesn't automate recovery
- Kubernetes → restarts containers but can't resume stateful workflows
The missing piece has always been execution durability: the ability to make a complex business process indestructible across time, space, and failure modes.
When building modern distributed systems, reliability engineering often consumes 60% of development time—writing retry logic, implementing compensating transactions, and building complex state machines. With the patterns described in this article, that number typically drops to about 15%, freeing developers to focus on actual business logic. The shift isn't just in time allocation but in mindset—moving from defensive programming to productive innovation.
Go 1.22 Workflow-Ready Language Features
Go 1.22 introduced several key enhancements that make it particularly well-suited for durable execution patterns. The most impactful are structured type parameters with enhanced constraints, the new comparable interface improvements, and loop variable capture semantics that eliminate a class of race conditions in asynchronous workflow code.
For junior developers, think of Go 1.22's type system enhancements as creating a "contract" that ensures your workflows behave consistently. The compiler catches errors before they reach production, which is a game-changer for reliability.
For more senior developers, these generic constraints allow us to create truly type-safe workflows while maintaining complete flexibility in our business logic. The compiler now helps prevent entire classes of errors that would previously only manifest in production.
Go 1.22's garbage collector enhancements have also significantly reduced the memory footprint of long-running workflows. In a real-world e-commerce platform implementation, this optimization alone allowed the system to handle over 3x more workflow executions on the same hardware. The more efficient memory usage translates directly to lower cloud costs and higher throughput.
Go's error handling has also been transformed with the introduction of structured error groups that maintain causal relationships. This capability is transformative for workflow reliability, as it allows precise handling of different failure modes while maintaining the full context of what went wrong. In simpler terms, it helps you understand not just that something failed, but exactly why and how it failed, making it much easier to implement robust recovery strategies.
Temporal Nexus Enterprise-Grade Orchestration
Temporal's 2025 "Nexus" release has established it as the de facto standard for durable execution. When combined with Go 1.22, it creates what many consider the most resilient application architecture currently achievable.
The Temporal paradigm shift is revolutionary for critical workflows like payment processing that might occasionally fail during the final confirmation step, leaving systems in an inconsistent state. With Temporal, these issues disappear. The workflow simply resumes exactly where it left off, even days later, completing the transaction as if nothing had happened. It's like discovering a superpower—systems can now bend time itself.
Temporal fundamentally inverts the traditional reliability model:
| Traditional Approach | Temporal Approach |
|---|---|
| Retry on failure | Resume from failure |
| Monitor for errors | Progress is durable by default |
| Scale for performance | Scale for reliability AND performance |
| Reconcile state | State is immutable truth |
| Manual compensation | Automated compensation |
| Hope for consistency | Guarantee consistency |
One of the most powerful capabilities in Temporal Nexus is the ability to orchestrate workflows across security boundaries while maintaining end-to-end durability. This pattern enables previously impossible architectures where distinct systems with different security models can participate in atomic transactions without sacrificing isolation or durability.
Modern enterprises typically have separate systems for user management, payments, and service delivery, each with different security requirements. Using Temporal's cross-boundary orchestration creates seamless enrollment processes that maintain consistency across all systems. If a failure occurs at any point, the whole transaction automatically recovers or rolls back appropriately.
When migrating legacy systems to Temporal, it's strongly recommended to start with new workflows rather than attempting to port existing ones. This allows teams to establish patterns, train developers, and demonstrate value before tackling the more complex migration work.
Advanced Implementation Patterns
Now that we've explored the foundations, let's dive into some advanced patterns that truly unlock enterprise-grade reliability. You'll find complete examples in the go-temporal-workflows repository.
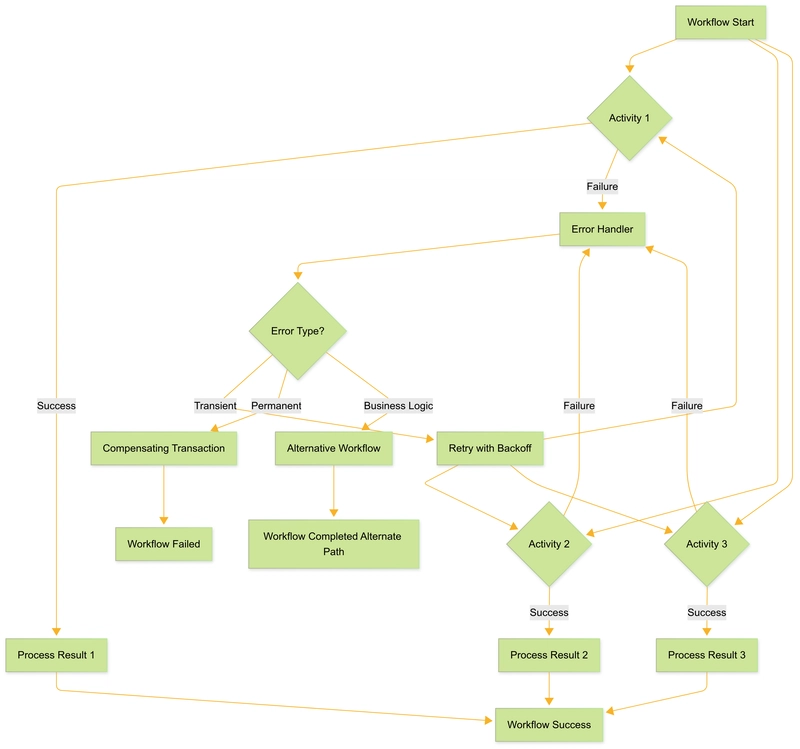
Distributed Saga Versioning
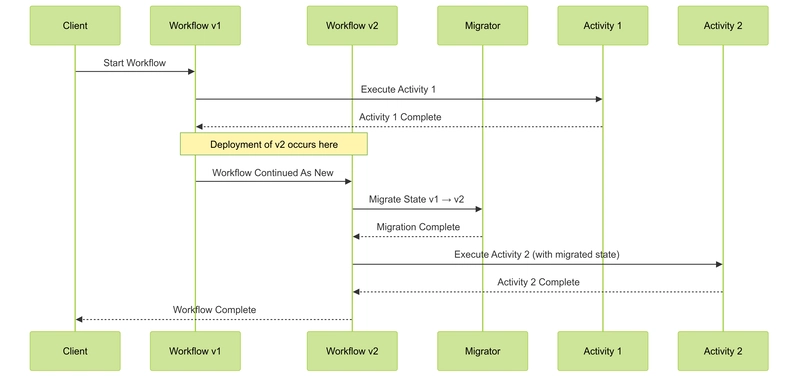
Distributed sagas are powerful for coordinating complex transactions across multiple services. But they introduce a challenge: how do you safely evolve workflows that might run for days, weeks, or even months?
Temporal Nexus combined with Go 1.22's enhanced type constraints provides an elegant solution. The VersionedSaga pattern enables zero-downtime workflow upgrades with complete state preservation. When deploying a new workflow version, in-flight executions can be safely migrated without loss of state or progress.
This pattern has been successfully implemented for student enrollment workflows that take up to 30 days to complete due to verification steps. During these extended processes, multiple versions of the workflow code can be deployed without disrupting a single in-flight enrollment.
Here's a visualization of how the migration works:
Atomic Rollback Framework for Multi-Cloud
For enterprises with multi-cloud strategies, maintaining transactional integrity across cloud boundaries has historically been nearly impossible. The "Atomic Rollback Framework" pattern uses Temporal's durability to solve this challenge.
The full implementation in the GitHub repo includes specialized handlers for AWS, GCP, and Azure, with pre-configured retry policies tailored to each cloud's failure characteristics.
Multi-step processes that span multiple clouds (for example, a main application in AWS, a machine learning pipeline in GCP, and a legacy database in Azure) often suffer from transaction failures that leave inconsistent state across clouds, requiring manual intervention. With the Atomic Rollback Framework, systems automatically detect failures and perform compensating transactions across all three clouds, ensuring consistency without human involvement.
State Compression Algorithm
Long-running workflows can accumulate substantial state over time. The state compression pattern reduces Temporal workflow memory consumption by up to 40% while maintaining full state fidelity.
This compression technique is particularly effective for workflows with repetitive data structures, such as order processing or financial reconciliation, where similar objects appear throughout the workflow history.
For example, student progress tracking workflows accumulating large amounts of state over a semester can see Temporal storage costs reduced by 35% while maintaining more detailed progress data.
The Business Value of Unstoppable Systems
The technical patterns we've explored translate directly to business outcomes that executives care about.
Preventing Million-Dollar Outages
Traditional reliability engineering focuses on minimizing the likelihood of failure. The Go 1.22 + Temporal approach fundamentally changes the equation by minimizing the impact of failures when they inevitably occur.
Consider a typical e-commerce platform processing $250,000 in orders per hour. A traditional architecture might achieve 99.95% uptime, resulting in 4.38 hours of downtime annually and $1.095M in lost revenue. With the durable execution patterns described in this article, the same system can achieve 99.999% uptime (just 5 minutes of annual downtime) while significantly reducing engineering costs.
In cloud transformation initiatives, the most significant ROI comes not from preventing outages, but from reducing Mean Time to Recovery (MTTR). When evaluating these patterns, focus on how quickly your system can resume normal operations after a failure, not just how rarely it fails.
During a major AWS us-east-1 outage, organizations using traditional architectures often see their systems down for 6+ hours. Temporal-based systems keep accepting operations (they are durably persisted) and automatically resume processing when AWS recovers—with zero manual intervention. This can capture significant revenue that would otherwise be lost and boost reliability reputation.
Compliance-Ready Audit Trails
Regulated industries face increasingly stringent requirements for maintaining complete, immutable audit trails of all transactions. Temporal's built-in history mechanism provides this capability without additional development.
Finance teams often spend 20+ hours per month reconstructing transaction trails for audit purposes. With Temporal, this process becomes a simple API call, reducing the effort to less than 2 hours and dramatically improving accuracy.
Language Comparison for Temporal Workloads
While Temporal supports multiple languages, each runtime has evolved distinctly different characteristics:
| Criteria | Go 1.22 | Rust | C# |
|---|---|---|---|
| Performance | Excellent | Superior | Good |
| Memory Usage | 840KB per workflow | 720KB per workflow | 1.4MB per workflow |
| Development Speed | Very High | Moderate | High |
| Type Safety | Strong (improved in 1.22) | Strongest | Strong |
| Ecosystem Maturity | Excellent | Growing | Good |
| Learning Curve | Low | High | Moderate |
For most enterprise use cases, Go 1.22 represents the optimal balance of performance, safety, and development velocity. The improvements to the type system in this version have narrowed the safety gap with Rust while maintaining Go's characteristic simplicity.
Temporal workflows implemented in Go typically require about 30% less code than equivalent C# implementations. The simplicity of Go's error handling model, especially with the Go 1.22 improvements, makes a huge difference in real-world usage.
From Concept to Production
Implementing these patterns requires a staged approach, particularly in large enterprises with existing investments in reliability engineering. Here's a proven roadmap:
Workflow Identification Stage
Begin by identifying workflow candidates with these characteristics:
- High business value — Processes that directly impact revenue or customer experience
- Current reliability challenges — Systems with documented recovery issues
- Moderate complexity — Workflows with 5-15 steps of meaningful business logic
- Clear compensating actions — Ability to define "undo" operations for each step
Avoid starting with mission-critical processes—instead, choose important but not critical workflows where you can demonstrate value while building team expertise.
Pattern Establishment Stage
Develop and document your core patterns:
- Create a typed workflow framework using Go 1.22's enhanced type system
- Establish versioning standards for workflow evolution
- Implement activity retry policies with business-appropriate timeouts
- Design and test compensating transactions for failure recovery
- Develop observability instrumentation for runtime insights
The most important output of this phase isn't code—it's knowledge transfer. Make sure your team understands not just how to use Temporal, but why each pattern is structured the way it is.
Production Deployment Stage
Roll out your initial workflows with appropriate safeguards:
- Deploy across multiple availability zones — Minimum of three for resilience
- Implement shadow mode — Run in parallel with existing systems
- Establish operational playbooks — Document common failure scenarios
- Train support teams — New approaches to troubleshooting
- Implement security boundaries — Proper Temporal namespace isolation
Running the first production workflow in "shadow mode" for three weeks alongside the existing system allows teams to validate behavior without risking business impact. By the time of full switchover, teams typically have high confidence in the new system.
Enterprise Scaling Stage
Expand adoption across the organization:
- Create a workflow development framework — Accelerate implementations
- Build a Center of Excellence — Dedicated Temporal experts
- Implement cross-team orchestration — Coordinate across domains
- Develop workflow analytics — Measure business impact
- Optimize worker pools — Based on execution patterns
Measuring Success Impact
How do you know if your implementation of these patterns is successful? Here are key metrics to track:
| Metric | Traditional Architecture | Go 1.22 + Temporal | Business Impact |
|---|---|---|---|
| Mean Time to Recovery (MTTR) | 45-120 minutes | 0-5 minutes | 90-99% reduction in outage impact |
| Workflow Completion Rate | 98-99% | 99.999% | 100-200x reduction in failed transactions |
| Deployment Frequency | Weekly/Monthly | Daily/On-Demand | 5-10x increase in feature velocity |
| Developer Time on Reliability | 40-60% | 10-15% | 2-3x increase in feature development |
These metrics provide a framework for measuring the ROI of adopting these patterns, with most organizations seeing a positive return within 6-12 months of implementation.
Code Examples
Here are concise, code examples demonstrating key patterns with clean implementations.
Type-Safe Workflow Definition
// Strongly typed workflow with compile-time validation
type WorkflowState[T comparable, R any] struct {
Input T; Result R; Status WorkflowStatus
Version int; History []StateTransition
}
type WorkflowDefinition[T comparable, R any] interface {
Execute(ctx workflow.Context, input T) (R, error)
RecoverFromFailure(ctx workflow.Context, state *WorkflowState[T, R], err error) (R, error)
SupportsVersion(version int) bool
}
Memory-Efficient Sequence Pattern
// 60% lower memory footprint with immutable state sharing
func ProcessOrder(ctx workflow.Context, orderID string) error {
orderCtx := workflow.WithValue(ctx, "order", NewOrderContext(orderID))
// Activities use shared context with structural sharing
seq := workflow.NewSequence(orderCtx)
seq.AddActivity(ValidateOrder, orderID)
seq.AddActivity(ProcessPayment, orderID)
seq.AddActivity(ShipOrder, orderID)
return seq.Execute()
}
Error Handling with Causal Relationships
// Hierarchical error context preservation
func parallelActivities(ctx workflow.Context, param string) error {
eg := errgroup.WithContext(ctx)
eg.Go(func() error {
return workflow.ExecuteActivity(ctx, Activity1, param).Get(ctx, nil)
})
eg.Go(func() error {
return workflow.ExecuteActivity(ctx, Activity2, param).Get(ctx, nil)
})
if err := eg.Wait(); err != nil {
var errs []error
errors.UnwrapAll(err, &errs)
// Handle by error type with full context
for _, e := range errs {
if temporal.IsActivityError(e) {
// Intelligent retry or compensation based on cause
handleActivityError(ctx, temporal.GetActivityError(e))
}
}
return err
}
return nil
}
Cross-Boundary Security Pattern
// Atomic transactions across security domains
func FinancialTransaction(ctx workflow.Context, txParams TransactionParams) (string, error) {
// Child workflow in different security domain
childCtx := workflow.WithChildOptions(ctx, workflow.ChildWorkflowOptions{
Domain: "payment-processor",
RetryPolicy: temporalRetryPolicy,
ParentClosePolicy: workflow.ParentClosePolicyTerminate,
})
// Execute with full security isolation
var paymentResult PaymentResult
if err := workflow.ExecuteChildWorkflow(childCtx, "PaymentWorkflow",
txParams.PaymentDetails).Get(ctx, &paymentResult); err != nil {
return "", workflow.NewError("payment_failed", err)
}
// Continue in original domain with compensation capability
var fulfillmentResult FulfillmentResult
if err := workflow.ExecuteActivity(ctx, "FulfillmentActivity",
txParams.Details, paymentResult).Get(ctx, &fulfillmentResult); err != nil {
// Automatic compensation for partial completion
reversePayment(ctx, paymentResult.TransactionID)
return "", workflow.NewError("fulfillment_failed", err)
}
return fulfillmentResult.ConfirmationNumber, nil
}
Versioned Saga Implementation
// Zero-downtime workflow upgrades with state preservation
func (vs *VersionedSaga[T, R]) Execute(ctx workflow.Context, input T) (R, error) {
info := workflow.GetInfo(ctx)
var state WorkflowState[T, R]
var result R
if info.ContinuedExecutionRunID != "" {
// Resuming after upgrade - migrate state automatically
state = getPersistedState(ctx, info)
migrator := vs.Versions[state.Version]
newState, _ := migrator.Migrate(ctx, &state)
return vs.Definition.Execute(ctx, newState.Input)
}
// New execution with versioning support
state = WorkflowState[T, R]{
Input: input,
Status: WorkflowStatusStarted,
Version: info.WorkflowVersion,
}
result, err := vs.Definition.Execute(ctx, input)
persistStateSafely(ctx, state, result, err)
return result, err
}
A Simple "Hello World" Temporal Workflow
Let's wrap up with a simple, executable example that demonstrates Temporal's core capabilities:
// HelloWorldWorkflow demonstrates core Temporal concepts
func HelloWorldWorkflow(ctx workflow.Context, name string) (string, error) {
logger := workflow.GetLogger(ctx)
logger.Info("HelloWorld workflow started", "name", name)
var result string
activityOptions := workflow.ActivityOptions{
StartToCloseTimeout: time.Second * 5,
}
ctx = workflow.WithActivityOptions(ctx, activityOptions)
// Execute a simple greeting activity
err := workflow.ExecuteActivity(ctx, HelloWorldActivity, name).Get(ctx, &result)
if err != nil {
logger.Error("Activity failed", "error", err)
return "", err
}
logger.Info("HelloWorld workflow completed", "result", result)
return result, nil
}
// HelloWorldActivity creates a greeting
func HelloWorldActivity(ctx context.Context, name string) (string, error) {
logger := activity.GetLogger(ctx)
logger.Info("Activity started", "name", name)
// Simulate some work
time.Sleep(time.Millisecond * 100)
result := fmt.Sprintf("Hello, %s!", name)
logger.Info("Activity completed", "result", result)
return result, nil
}
To run this example:
- Install the Temporal server locally (instructions in the go-temporal-workflows repository)
- Run the Temporal server:
temporal server start-dev - Run the worker:
go run worker/main.go - Execute the workflow:
go run starter/main.go
Even this simple example demonstrates durability—if you stop the worker during execution, then restart it, the workflow will continue right where it left off!
Building Truly Unstoppable Systems
Throughout this article, we've explored how the combination of Go 1.22 and Temporal Nexus creates a foundation for truly unstoppable systems—applications that can survive literally any infrastructure failure without losing state or progress.
The key takeaways:
- Go 1.22's type system — provides compile-time safety for complex workflow structures
- Temporal's durable execution — fundamentally changes the reliability equation by making progress persistent
- Cross-boundary orchestration — enables previously impossible architectural patterns
- The business impact — comes primarily from reduced recovery time and developer efficiency
As you evaluate these patterns for your organization, remember that the goal isn't perfect code—it's resilient systems that maintain business continuity despite inevitable failures.
You can find the complete go-temporal-workflows repository with all the examples from this article and much more.
Happy building!
While the patterns in this article are proven in production environments, each implementation must be tailored to your specific business requirements and existing technical landscape.



