![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)
























































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)


























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)






























































































































Building Flowfile: Architecting a Visual ETL Tool with Polars
Flowfile is my open-source project, born from trying to build an Alteryx alternative that combined two things I like: the straightforward visual style of drag-and-drop tools, and the challenge plus creative freedom you get coding with powerful libraries like Polars. Building it taught me a ton, particularly about getting the architecture right. Since it was such an educational ride, I wanted to break down some of the technical bits here. So, for my first article here on dev.to, I'm excited to do just that – dive into those technical bits! This piece goes behind the scenes of Flowfile's architecture to reveal how data actually flows through the system, from the moment you drag a node onto the canvas right through to final execution. You'll learn about: How nodes and connections form a directed acyclic graph (DAG) The schema prediction system that provides real-time feedback without execution How execution modes leverage Polars' lazy evaluation for performance The worker-based execution model that optimizes memory usage Efficient inter-process communication using Apache Arrow IPC By understanding these components, you'll gain insight into the design decisions made within Flowfile to balance user experience with performance. The architecture: Three interconnected services Flowfile operates as three separate but interconnected components: Designer (Electron + Vue): The visual interface users interact with. Core (FastAPI): The ETL engine that manages workflows, schema predictions, and orchestrates data transformations. Worker (FastAPI): Handles heavy computations and data caching. Let's walk through what happens at each stage of building and executing a data pipeline. Building a data flow: What happens when you drag a node? When you drag a node onto the canvas in the Designer, Flowfile initiates a series of coordinated actions between the front-end and back-end: Node creation: The Designer sends a request to the Core service to create a new node of the specified type. Graph update: The Core service registers this node by creating a NodeStep instance in the workflow graph with placeholder functionality. Connection setup: As the user connects the new node to existing nodes, the Designer communicates these connections to the Core service. Input schema inference: Based on the upstream nodes, the Core service infers the input data schema and sends it back to the Designer, allowing the user to immediately see what data is available for the selected action. Node configuration: The user configures the node’s settings in the Designer (e.g., selecting columns, specifying transformations). Schema prediction: These settings are sent to the Core service, which uses them to calculate the predicted output schema. Schema feedback: The predicted schema is returned to the Designer and displayed in the interface, giving users real-time feedback on how their data will be shaped—before any execution occurs. Iteration: When the user adds the next node, the cycle starts again from step 1, allowing complex workflows to be built step-by-step with continuous feedback. The constant interaction between the Core service and the designer decreases the chance of user errors and increases predictability. This schema prediction is one of Flowfile's most powerful features. # Core schema prediction function (simplified) # Determines output structure without executing transformations def get_predicted_schema(self) -> List[FlowfileColumn]: """Return the predicted schema for this node without executing the transformation.""" if self.schema_callback is not None: # Use custom schema prediction if available return self.schema_callback() else: # Otherwise, infer from lazy evaluation by getting the schema from the plan predicted_data = self._predicted_data_getter() # Gets the Polars LazyFrame plan return predicted_data.schema # Polars can get schema from a LazyFrame Schema prediction: How Flowfile knows your data structure in advance Schema prediction occurs through one of two mechanisms: Schema Callbacks: Custom functions, defined per node type, that calculate the expected output schema based on node configuration and input schemas. Lazy Evaluation: Utilizing Polars' ability to determine the schema of a planned transformation (LazyFrame) without processing the full dataset. This approach provides immediate feedback to users about the structure of their data pipeline without requiring expensive computation. For example, when you set up a "Group By" operation, a schema callback can tell you exactly what the output columns will be based on your aggregation choices, before processing any data: # Example of a schema callback for a Group By node def schema_callback() -> List[FlowfileColumn]: """Calculate the output schema for a group by operation based on aggregation choices.""" # Extract column info from settings (simpli
Flowfile is my open-source project, born from trying to build an Alteryx alternative that combined two things I like: the straightforward visual style of drag-and-drop tools, and the challenge plus creative freedom you get coding with powerful libraries like Polars. Building it taught me a ton, particularly about getting the architecture right. Since it was such an educational ride, I wanted to break down some of the technical bits here.
So, for my first article here on dev.to, I'm excited to do just that – dive into those technical bits! This piece goes behind the scenes of Flowfile's architecture to reveal how data actually flows through the system, from the moment you drag a node onto the canvas right through to final execution. You'll learn about:
- How nodes and connections form a directed acyclic graph (DAG)
- The schema prediction system that provides real-time feedback without execution
- How execution modes leverage Polars' lazy evaluation for performance
- The worker-based execution model that optimizes memory usage
- Efficient inter-process communication using Apache Arrow IPC
By understanding these components, you'll gain insight into the design decisions made within Flowfile to balance user experience with performance.
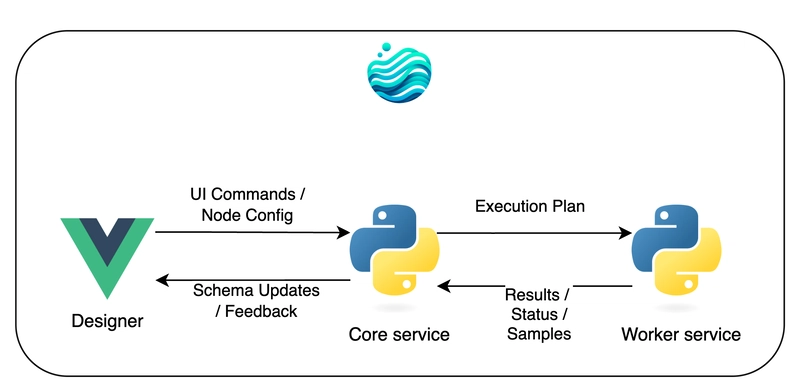
The architecture: Three interconnected services
Flowfile operates as three separate but interconnected components:
- Designer (Electron + Vue): The visual interface users interact with.
- Core (FastAPI): The ETL engine that manages workflows, schema predictions, and orchestrates data transformations.
- Worker (FastAPI): Handles heavy computations and data caching.
Let's walk through what happens at each stage of building and executing a data pipeline.
Building a data flow: What happens when you drag a node?
When you drag a node onto the canvas in the Designer, Flowfile initiates a series of coordinated actions between the front-end and back-end:
- Node creation: The Designer sends a request to the Core service to create a new node of the specified type.
- Graph update: The Core service registers this node by creating a
NodeStepinstance in the workflow graph with placeholder functionality. - Connection setup: As the user connects the new node to existing nodes, the Designer communicates these connections to the Core service.
- Input schema inference: Based on the upstream nodes, the Core service infers the input data schema and sends it back to the Designer, allowing the user to immediately see what data is available for the selected action.
- Node configuration: The user configures the node’s settings in the Designer (e.g., selecting columns, specifying transformations).
- Schema prediction: These settings are sent to the Core service, which uses them to calculate the predicted output schema.
- Schema feedback: The predicted schema is returned to the Designer and displayed in the interface, giving users real-time feedback on how their data will be shaped—before any execution occurs.
- Iteration: When the user adds the next node, the cycle starts again from step 1, allowing complex workflows to be built step-by-step with continuous feedback.
The constant interaction between the Core service and the designer decreases the chance of user errors and increases predictability. This schema prediction is one of Flowfile's most powerful features.
# Core schema prediction function (simplified)
# Determines output structure without executing transformations
def get_predicted_schema(self) -> List[FlowfileColumn]:
"""Return the predicted schema for this node without executing the transformation."""
if self.schema_callback is not None:
# Use custom schema prediction if available
return self.schema_callback()
else:
# Otherwise, infer from lazy evaluation by getting the schema from the plan
predicted_data = self._predicted_data_getter() # Gets the Polars LazyFrame plan
return predicted_data.schema # Polars can get schema from a LazyFrame
Schema prediction: How Flowfile knows your data structure in advance
Schema prediction occurs through one of two mechanisms:
- Schema Callbacks: Custom functions, defined per node type, that calculate the expected output schema based on node configuration and input schemas.
- Lazy Evaluation: Utilizing Polars' ability to determine the schema of a planned transformation (
LazyFrame) without processing the full dataset.
This approach provides immediate feedback to users about the structure of their data pipeline without requiring expensive computation.
For example, when you set up a "Group By" operation, a schema callback can tell you exactly what the output columns will be based on your aggregation choices, before processing any data:
# Example of a schema callback for a Group By node
def schema_callback() -> List[FlowfileColumn]:
"""Calculate the output schema for a group by operation based on aggregation choices."""
# Extract column info from settings (simplified representation)
output_columns = [(c.old_name, c.new_name, c.output_type)
for c in group_by_settings.groupby_input.agg_cols]
# Get input schema info from the upstream node ('depends_on')
input_schema_dict: Dict[str, str] = {s.name: s.data_type for s in depends_on.schema}
output_schema: List[FlowfileColumn] = []
# Construct the output schema based on settings and input types
for old_name, new_name, data_type in output_columns:
# Infer data type if not explicitly set by the aggregation
data_type = input_schema_dict[old_name] if data_type is None else data_type
output_schema.append(FlowfileColumn.from_input(data_type=data_type, column_name=new_name))
return output_schema
The directed acyclic graph (DAG): The foundation of workflows
As you add and connect nodes, Flowfile builds a Directed Acyclic Graph (DAG) where:
- Nodes represent data operations (read file, filter, join, write to database, etc.).
- Edges represent the flow of data between operations.
The DAG is managed by the EtlGraph class in the Core service, which orchestrates the entire workflow:
class EtlGraph:
"""
Manages the ETL workflow as a DAG. Stores nodes, dependencies,
and settings, and handles the execution order.
"""
uuid: str
_node_db: Dict[Union[str, int], NodeStep] # Internal storage for all node steps
_flow_starts: List[NodeStep] # Nodes that initiate data flow (e.g., readers)
_node_ids: List[Union[str, int]] # Tracking node identifiers
flow_settings: schemas.FlowSettings # Global configuration for the flow
def add_node_step(self, node_id: Union[int, str], function: Callable,
node_type: str, **kwargs) -> None:
"""Adds a new processing node (NodeStep) to the graph."""
node_step = NodeStep(node_id=node_id, function=function, node_type=node_type, **kwargs)
self._node_db[node_id] = node_step
# Additional logic to manage dependencies and flow starts...
def run_graph(self) -> RunInformation:
"""Executes the entire flow in the correct topological order."""
execution_order = self.topological_sort() # Determine correct sequence
run_info = RunInformation()
for node in execution_order:
# Execute node based on mode (Development/Performance)
node_results = node.execute_node() # Simplified representation
run_info.add_result(node.node_id, node_results)
return run_info
def topological_sort(self) -> List[NodeStep]:
"""Determines the correct order to execute nodes based on dependencies."""
# Standard DAG topological sort algorithm...
pass
Each NodeStep in the graph encapsulates information about its dependencies, transformation logic, and output schema. This structure allows Flowfile to determine execution order, track data lineage, optimize performance, and provide schema predictions throughout the pipeline.
Leveraging lazy evaluation with Polars
The real power of Flowfile comes from leveraging Polars' lazy evaluation. Instead of processing data immediately at each step, Polars builds an optimized execution plan. The actual computation is deferred until the result is explicitly requested (e.g., writing to a file or displaying data).
This provides several significant benefits:
- Reduced Memory Usage: Data is loaded and processed only when necessary, often streaming through operations without loading entire datasets into memory at once.
- Query Optimization: Polars analyzes the entire plan and can reorder, combine, or eliminate operations for maximum efficiency.
- Parallel Execution: Polars automatically parallelizes operations across available CPU cores during execution.
- Predicate Pushdown: Filters and selections are applied as early as possible in the plan, often directly at the data source level (like during file reading), minimizing the amount of data that needs to be processed downstream.
Consider reading, filtering, and writing data:
# Traditional eager approach (less efficient):
df = pl.read_csv("large_file.csv") # Reads entire file into memory immediately
filtered_df = df.filter(pl.col("value") > 10) # Filters the in-memory dataframe
filtered_df.write_parquet("output.parquet") # Writes the filtered result
# Polars' lazy evaluation approach (efficient):
# 1. Build the plan (no data loaded yet)
lazy_plan = pl.scan_csv("large_file.csv") # Creates a plan to read the CSV
filtered_plan = lazy_plan.filter(pl.col("value") > 10) # Adds filtering to the plan
# 2. Execute the optimized plan (only happens here)
result_df = filtered_plan
filtering efficiently
result_df.sink_parquet("output.parquet") # Writes the final result
Flowfile uses this lazy approach extensively, especially in Performance Mode.
Execution modes: Development vs. Performance
Flowfile offers two execution modes tailored for different needs:
| Feature | Development Mode | Performance Mode |
|---|---|---|
| Purpose | Interactive debugging, step inspection | Optimized execution for production/speed |
| Execution | Executes node-by-node | Builds full plan, executes minimally |
| Data Caching | Caches intermediate results per step | Minimal caching (only if specified/needed) |
| Preview Data | Available for all nodes | Only for final/cached nodes |
| Memory Usage | Potentially higher | Generally lower |
| Speed | Moderate | Faster for complex flows |
Development Mode
In Development mode, each node's transformation is triggered sequentially. After a node executes (within the Worker service), its intermediate result is typically serialized using Apache Arrow IPC format and cached to disk. This allows you to inspect the data at each step in the Designer via small samples fetched from the cache.
Performance Mode
In Performance mode, Flowfile fully embraces Polars' lazy evaluation:
- The Core service constructs the entire Polars execution plan based on the DAG.
- This plan (
LazyFrame) is passed to the Worker service. - The Worker only materializes (executes
.collect()or.sink_*()) the plan when:- An output node (like writing to a file) requires the final result.
- A node is explicitly configured to cache its results (
node.cache_results).
This minimizes computation and memory usage by avoiding unnecessary intermediate materializations.
# Execution logic in Performance Mode (simplified)
def execute_performance_mode(self, node: NodeStep, is_output_node: bool):
"""Handles execution in performance mode, leveraging lazy evaluation."""
if is_output_node or node.cache_results:
# If result is needed (output or caching), trigger execution in Worker
external_df_fetcher = ExternalDfFetcher(
lf=node.get_resulting_data().data_frame, # Pass the LazyFrame plan
file_ref=node.hash, # Unique reference for caching
wait_on_completion=False # Usually async
)
# Worker executes .collect() or .sink_*() and caches if needed
result = external_df_fetcher.get_result() # May return LazyFrame or trigger compute
return result # Or potentially just confirmation if sinking
else:
# If not output/cached, just pass the LazyFrame plan along
# No computation happens here for intermediate nodes
return node.get_resulting_data().data_frame
Crucially, all actual data processing and materialization of Polars DataFrames/LazyFrames happens in the Worker service. This separation prevents large datasets from overwhelming the Core service, ensuring the UI remains responsive.
Efficient Inter-process Communication (IPC) Between Core and Worker
Since Core orchestrates and Worker computes, efficient communication is vital. Flowfile uses Apache Arrow IPC format for data exchange:
- Worker Processing: When the Worker needs to materialize data (either intermediate cache in Dev mode or final results), it computes the Polars DataFrame.
- Serialization & Caching: The resulting DataFrame is serialized into the efficient Arrow IPC binary format and saved to a temporary file on disk. This file acts as a cache, identified by a unique hash (
file_ref). - Reference Passing: The Worker informs the Core that the result is ready at the specified
file_ref. - Core Fetching: If the Core (or subsequently, another Worker task) needs this data, it uses the
file_refto access the cached Arrow file directly. This avoids sending large datasets over network sockets between processes. - UI Sampling: For UI previews, the Core requests a small sample (e.g., the first 100 rows) from the Worker. The Worker reads just the sample from the Arrow IPC file and sends only that lightweight data back to the Core, which forwards it to the Designer.
Here’s how the Core might offload computation to the Worker:
# Core side - Initiating remote execution in the Worker
def execute_remote(self, performance_mode: bool = False) -> None:
"""Offloads the execution of a node's LazyFrame to the Worker service."""
# Create a fetcher instance to manage communication with the Worker
external_df_fetcher = ExternalDfFetcher(
lf=self.get_resulting_data().data_frame, # The Polars LazyFrame plan
file_ref=self.hash, # Unique identifier for the result/cache
wait_on_completion=False, # Operate asynchronously
# Pass other necessary context like flow_id, node_id, operation type...
)
# Store the fetcher to potentially retrieve results later
self._fetch_cached_df = external_df_fetcher
# Request the Worker to start processing (this returns quickly)
# The actual computation happens asynchronously in the Worker
external_df_fetcher.start_processing_in_worker() # Hypothetical method name
# If we immediately need the result (e.g., for a subsequent synchronous step):
# lf = external_df_fetcher.get_result() # This would block until Worker is done
# self.results.resulting_data = FlowfileTable(lf)
# For UI updates, request a sample separately
self.store_example_data_generator(external_df_fetcher) # Fetches sample async
And how the Worker might manage the separate process execution:
# Worker side - Managing computation in a separate process
def start_process(
polars_serializable_object: bytes, # Serialized LazyFrame plan
task_id: str,
file_ref: str, # Path for cached output (Arrow IPC file)
# ... other args like operation type
) -> None:
"""Launches a separate OS process to handle the heavy computation."""
# Use multiprocessing context for safety
mp_context = multiprocessing.get_context('spawn') # or 'fork' depending on OS/needs
# Shared memory/queue for progress tracking and results/errors
progress = mp_context.Value('i', 0) # Shared integer for progress %
error_message = mp_context.Array('c', 1024) # Shared buffer for error messages
queue = mp_context.Queue(maxsize=1) # For potentially passing back results (or file ref)
# Define the target function and arguments for the new process
process = mp_context.Process(
target=process_task, # The function that runs Polars .collect()/.sink()
kwargs={
'polars_serializable_object': polars_serializable_object,
'progress': progress,
'error_message': error_message,
'queue': queue,
'file_path': file_ref, # Where to save the Arrow IPC output
# ... other necessary kwargs
}
)
process.start() # Launch the independent process
# Monitor the task (e.g., update status in a database, check progress)
handle_task(task_id, process, progress, error_message, queue)
This architecture ensures:
- Responsiveness: The Core service remains light and responsive to UI interactions.
- Memory Isolation: Heavy memory usage is contained within transient Worker processes.
- Efficiency: Arrow IPC provides fast serialization/deserialization and efficient disk caching.
- Scalability: Allows handling datasets larger than the memory of any single service by processing chunks or relying on Polars' streaming capabilities where applicable.
Conclusion: Combining Visual Simplicity with Polars' Power
Flowfile tries to bridge the gap between the intuitive, visual workflow building familiar from tools like Alteryx or KNIME, and the raw performance and flexibility you get from modern data libraries like Polars.
By architecting the system around Polars' lazy evaluation, providing real-time schema feedback, and employing a robust multi-process model with efficient Arrow IPC communication, Flowfile delivers a user-friendly experience without sacrificing the speed needed for demanding data tasks. It's designed as a powerful tool for data analysts who prefer visual interfaces and data engineers who need performance and control.
Flowfile is intended as a performant, intuitive, and open-source solution for modern data transformation challenges.
If you're interested in trying Flowfile, exploring its capabilities, or contributing to its development, check out the Flowfile GitHub repository. Feedback and contributions are highly encouraged!
What are your favorite visual ETL tools, or how do you combine visual and code-based approaches in your data workflows? Share your thoughts in the comments below!