![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)

































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)






































































































(1).jpg?#)































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)









































































































![Apple to Split iPhone Launches Across Fall and Spring in Major Shakeup [Report]](https://www.iclarified.com/images/news/97211/97211/97211-640.jpg)
![Apple to Move Camera to Top Left, Hide Face ID Under Display in iPhone 18 Pro Redesign [Report]](https://www.iclarified.com/images/news/97212/97212/97212-640.jpg)
![Apple Developing Battery Case for iPhone 17 Air Amid Battery Life Concerns [Report]](https://www.iclarified.com/images/news/97208/97208/97208-640.jpg)
![AirPods 4 On Sale for $99 [Lowest Price Ever]](https://www.iclarified.com/images/news/97206/97206/97206-640.jpg)






























![[Updated] Samsung’s 65-inch 4K Smart TV Just Crashed to $299 — That’s Cheaper Than an iPad](https://www.androidheadlines.com/wp-content/uploads/2025/05/samsung-du7200.jpg)





























































AI Agents: how they work and how to build them
Have you heard about AI Agents? Of course, you heard about them. These are the intelligent agents who will take our jobs in a few years! I don’t want to scare you, but someone on Twitter said that “most jobs will become obsolete” in less than 10 years. McKinsey agrees (they say AI Agents will replace 70% of office work), and Goldman, too. So, I guess our clock is ticking. We don’t have much time. It’s probably better to take a woodworking course or something similar. But I am not that good at woodworking. So, let’s try to understand how AI Agents work and if they are that scary. If you read Twitter or Linkedin, AI Agents look like special agents that can do everything. The demos that they share look amazing. However, these agents don’t feel that special when you use them. They are helpful for specific cases, just like travel agents. If you give enough details about your desired journey and budget to travel agents, they can find you the vacation you want and plan the entire trip. Just like Cursor! If you give enough details and specific instructions, vibe coding feels like magic (parts of the application start assembling in front of you). In other cases, Cursor feels as smart and useful as Alexa or Siri. So, AI Agents can be extremely helpful, especially if you understand how they work. But before we can understand AI Agents, we need to understand LLMs. How LLMs work Large Language Models or LLMs are very good at predicting the next best set of words based on your input (questions, part of the text they need to complete, or detailed instructions), their training data (all the text that creators of the LLM you use were able to use for training, such as books, websites, your private data [just kidding, or am I?], and other datasets), context (the previous conversation flow or documents you attached), and specific configurations (such as weights, which prioritize certain word patterns, and settings like temperature, which control the randomness of predictions). Let’s use the same example I used in the “5 Prompt Engineering Tips for Developers” article! If you ask an LLM to finish the following sentence: “I am speaking at,” it’ll probably say something such as “a business conference,” “a tech meetup,“or “a community forum.” There’s almost zero chance it would say, “A Martian picnic?” Or “a space farmer’s market.” However, if we add a few sentences to the beginning of the instructions (or prompt, as we call it when talking to LLMs) that tell an LLM that it is a playful, chatty cartoon character named “Space Bunny,” the LLM would not finish the sentence with “a tech meetup,” or similar, but with something more similar to a Martian picnic. When you talk to an LLM, your question or a set of instructions is called a prompt. So, prompts are just instructions. You tell an LLM what you want, and it tries to reply based on your input and context, as well as its training set and configuration. If your instructions are clear, there’s a higher chance you’ll get a helpful reply. However, an LLM will reply even if your instructions do not make sense. In that case and in some other cases, its replies might not be based on truth (we call that hallucinations). Everything related to hallucinations is improving fast, so whatever I write here will probably not be true in a few months. So, you give your instructions (or write your prompt if you want to sound smarter), LLM takes these instructions, spins up some GPUs, burns a small forest, “eats” some of your tokens, and you get an unexpected wisdom or a hallucination. In the world of LLMs, tokens = money. You burn them like the Monopoly money, but the key difference is that LLM tokens are connected to your credit card. But how does an LLM know how to reply to your prompt? Computers are not that great with words. They prefer numbers. So, an LLM will split your instructions into tokens (yeah, these are the tokens I mentioned above). A token is a set of characters that is sometimes equal to a word, sometimes to the part of the word, and sometimes to a set of letters and other characters such as spaces, dots, commas, etc. The exact number of tokens your instructions have depends on the algorithm the LLM uses. You can see the visualization of OpenAI’s tokenizer in the image below or here: https://platform.openai.com/tokenizer. You’ll get slightly different results based on the model you select. But tokens are still words! A tokenizer represents each of these tokens as a set of numbers (so each token becomes an array of numbers). These numbers are vectors that can be placed in a multidimensional space. The entire training set of an LLM is also transformed into tokens and then vectors and put in the same multidimensional space. The major power of LLMs is their ability to put related words (based on their vast training sets) close to each other in this space. For a quick visual example, imagine that each token converts to an array of two numbers (two-di

Have you heard about AI Agents? Of course, you heard about them. These are the intelligent agents who will take our jobs in a few years!
I don’t want to scare you, but someone on Twitter said that “most jobs will become obsolete” in less than 10 years. McKinsey agrees (they say AI Agents will replace 70% of office work), and Goldman, too.
So, I guess our clock is ticking. We don’t have much time. It’s probably better to take a woodworking course or something similar.
But I am not that good at woodworking. So, let’s try to understand how AI Agents work and if they are that scary.
If you read Twitter or Linkedin, AI Agents look like special agents that can do everything. The demos that they share look amazing.

However, these agents don’t feel that special when you use them. They are helpful for specific cases, just like travel agents. If you give enough details about your desired journey and budget to travel agents, they can find you the vacation you want and plan the entire trip. Just like Cursor! If you give enough details and specific instructions, vibe coding feels like magic (parts of the application start assembling in front of you). In other cases, Cursor feels as smart and useful as Alexa or Siri.

So, AI Agents can be extremely helpful, especially if you understand how they work. But before we can understand AI Agents, we need to understand LLMs.
How LLMs work
Large Language Models or LLMs are very good at predicting the next best set of words based on your input (questions, part of the text they need to complete, or detailed instructions), their training data (all the text that creators of the LLM you use were able to use for training, such as books, websites, your private data [just kidding, or am I?], and other datasets), context (the previous conversation flow or documents you attached), and specific configurations (such as weights, which prioritize certain word patterns, and settings like temperature, which control the randomness of predictions).
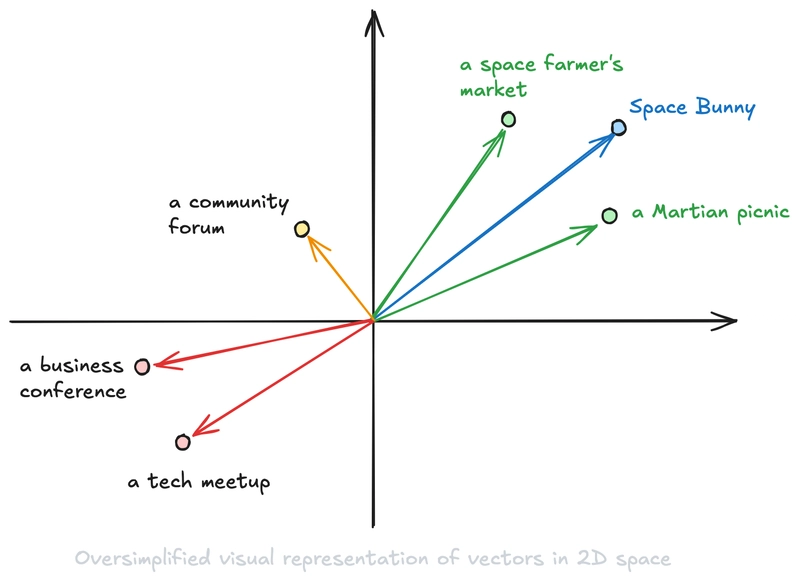
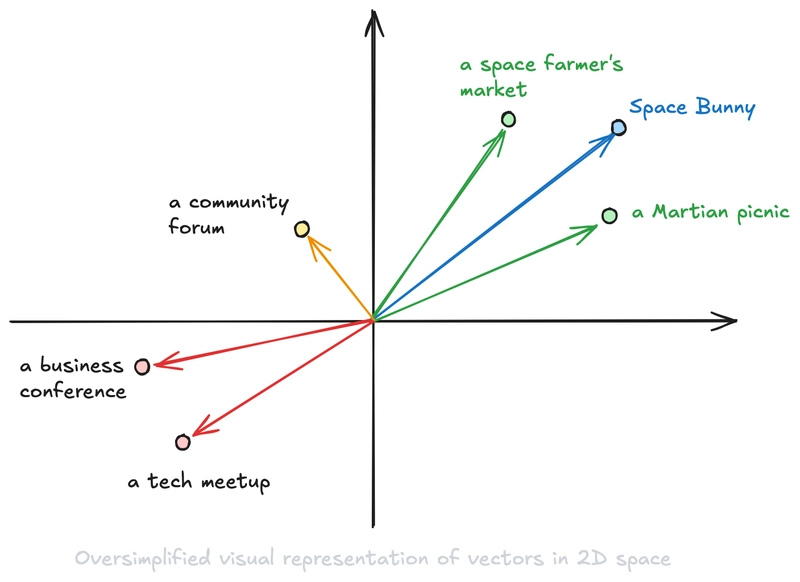
Let’s use the same example I used in the “5 Prompt Engineering Tips for Developers” article! If you ask an LLM to finish the following sentence: “I am speaking at,” it’ll probably say something such as “a business conference,” “a tech meetup,“or “a community forum.” There’s almost zero chance it would say, “A Martian picnic?” Or “a space farmer’s market.”

However, if we add a few sentences to the beginning of the instructions (or prompt, as we call it when talking to LLMs) that tell an LLM that it is a playful, chatty cartoon character named “Space Bunny,” the LLM would not finish the sentence with “a tech meetup,” or similar, but with something more similar to a Martian picnic.

When you talk to an LLM, your question or a set of instructions is called a prompt. So, prompts are just instructions. You tell an LLM what you want, and it tries to reply based on your input and context, as well as its training set and configuration. If your instructions are clear, there’s a higher chance you’ll get a helpful reply. However, an LLM will reply even if your instructions do not make sense. In that case and in some other cases, its replies might not be based on truth (we call that hallucinations). Everything related to hallucinations is improving fast, so whatever I write here will probably not be true in a few months.
So, you give your instructions (or write your prompt if you want to sound smarter), LLM takes these instructions, spins up some GPUs, burns a small forest, “eats” some of your tokens, and you get an unexpected wisdom or a hallucination. In the world of LLMs, tokens = money. You burn them like the Monopoly money, but the key difference is that LLM tokens are connected to your credit card.
But how does an LLM know how to reply to your prompt?
Computers are not that great with words. They prefer numbers. So, an LLM will split your instructions into tokens (yeah, these are the tokens I mentioned above). A token is a set of characters that is sometimes equal to a word, sometimes to the part of the word, and sometimes to a set of letters and other characters such as spaces, dots, commas, etc. The exact number of tokens your instructions have depends on the algorithm the LLM uses. You can see the visualization of OpenAI’s tokenizer in the image below or here: https://platform.openai.com/tokenizer. You’ll get slightly different results based on the model you select.

But tokens are still words! A tokenizer represents each of these tokens as a set of numbers (so each token becomes an array of numbers). These numbers are vectors that can be placed in a multidimensional space. The entire training set of an LLM is also transformed into tokens and then vectors and put in the same multidimensional space. The major power of LLMs is their ability to put related words (based on their vast training sets) close to each other in this space.
For a quick visual example, imagine that each token converts to an array of two numbers (two-dimensional space is easy to visualize). Then, we would be able to put our dots in this space similar to the following image:
Now that an LLM converts your instructions to a set of vectors (an array of arrays of numbers!) and puts them in its multidimensional space, it can use its algorithm to find the closest vectors that might be a good answer to your instructions. LLMs are Large Language Models, meaning they are trained on a massive set of data, which helps them put these vectors in the correct places in the multidimensional space and offer a meaningful answer.
Luckily, LLMs are products, and like other products, they evolve with user feedback and misusage. So we got many useful features that were not initially available, such as system prompts (parts of the prompts that are more important than the rest of the conversation with an LLM), better coding and JSON skills, etc.
An undercover agent
Meet my friend Claude. I ask it many weird questions every day. Claude is nice, so it tries to answer each question in detail politely.
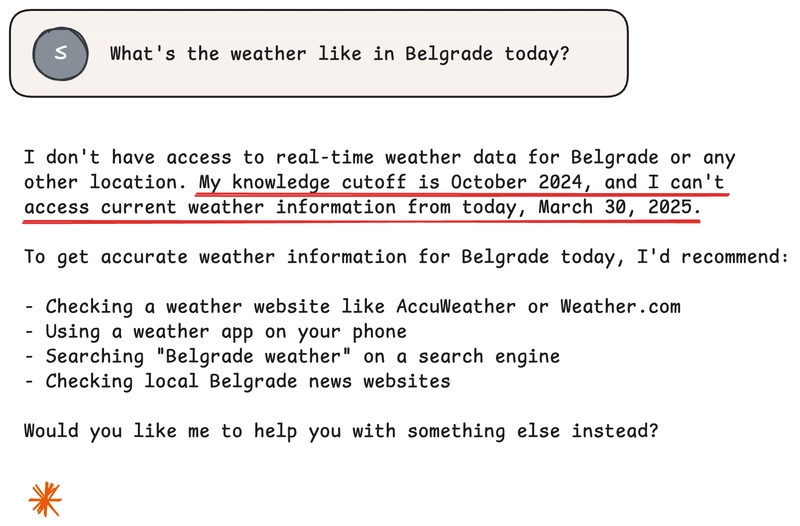
One day, I asked Claude what the weather was like in Belgrade. I ask way more weird questions to both Claude and ChatGPT. But this question is special!

It’s special because Claude can’t answer it. It told me politely that it had no access to real-time weather information. Ah, I forgot that ChatGPT can search the internet, but Claude can’t do it yet!
It makes sense that Claude does not have an answer to my question because it takes months to train an LLM model. I could ask another LLM to answer my question or simply check my phone. But I like Claude! Can I do something to help it to answer this kind of question?
Can I do a quick Google search for Claude when it needs some real-time data?
It’s a weird idea, but let’s try it! I’ll tell Claude that it should let me know when it needs me to search the internet. Claude can be a bit chatty, so I’ll make sure to tell it to provide an exact search phrase I should use. For example, telling me Google:weather in Belgrade today would be ideal.

It seems that my friend Claude likes this game. Let’s ask again, “What’s the weather like in Belgrade today?”

It worked! Claude provided an exact search query so I can do a Google search and provide a screenshot. The reply was more detailed than I needed it to be, but it did not matter; I understood my assignment.
I copied the search phrase, opened my browser, and googled it. Then, I took a screenshot of the result and sent it to Claude. And Claude replied with useful information about the current weather in Belgrade!

Claude definitely liked this game.
But while I did this just for fun, I accidentally did one more thing – I just created an AI agent!
I know it’s not a very useful agent, as I could just read the weather data from Google. But it’s still an agent.
I also know ChatGPT can search the internet, so I could use it instead of Claude. But ChatGPT is also an agent! It’s just an undercover agent that looks like a plain old LLM. To be fair, Claude is also an agent. Just ask it to draw a diagram or create a webpage for you, and you’ll see some superpowers that LLMs do not have.
How AI Agents work
LLMs are amazing! They really are. But like many other tools, they are good at some things but not so good at others.
For example, LLMs are excellent at picking the best set of tokens to continue the set of tokens we provided. Or, in a human-understandable language, they are very good at answering questions, completing sentences, writing text, etc.

You ask a question. LLM replies. Sometimes, it’s helpful information; sometimes, you must ask a follow-up question. But it always replies.
However, not all of these replies are based on truth. Sometimes, an LLM replies with false information that we call hallucinations. That’s because it tries to find the closest set of tokens to your tokenized instructions (or your question) and always finds something.
LLMs do not really care about the truth. They care about the closest tokens to your tokenized instructions, their training sets, their configuration, and some additional parameters.
But what makes an LLM an agent?
Agents are LLMs with something that provides missing information or capabilities to help LLMs answer our questions. If we call these things “tools,” agents are LLMs with tools.
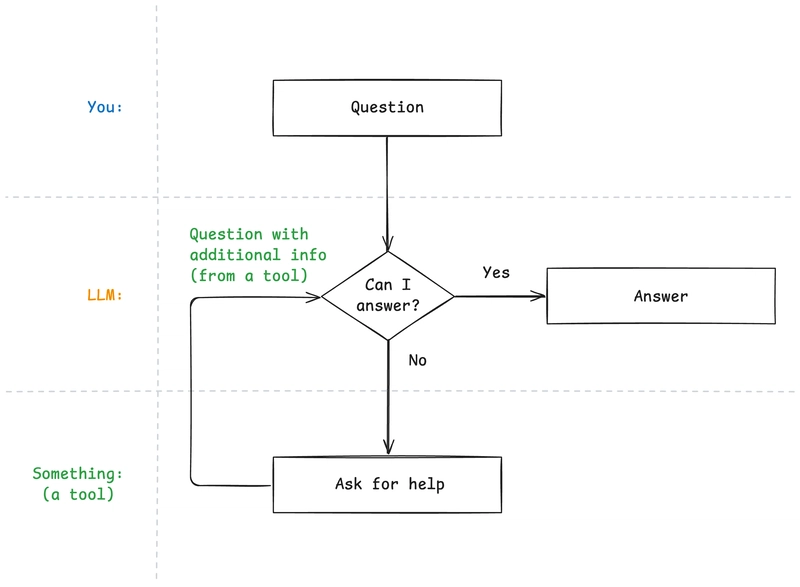
However, to be an agent, LLM must orchestrate these tools and decide when it has enough information to answer our questions or complete our tasks. If we orchestrate the tools with predefined code, LLM is just a tool in our code, and our code is not an AI agent.
The diagram above looks familiar. It looks like a while loop!
So, I guess we can say that an AI agent is like a “while loop” that keeps asking available tools to provide additional information or capability until it has all it needs to complete the task or answer the question.
Anything can be a tool that provides missing capabilities or information to LLMs as long as LLMs have an easy way to use that tool.
For example, I was a tool that my friend Claude used to find information about the current weather in Belgrade! But that made our “while loop” expensive because it used both LLM tokens and my time.
These “while loops” are generally expensive. They are not expensive because of the big O notation and code complexity but because in each iteration, LLM evaluates whether it can complete the task and uses tokens (and our money).
Being expensive depends on the value it provides, but it’s always a good idea to be careful. You can be careful by setting the billing alarms and spending limits, making sure that the LLM does not iterate indefinitely (by limiting the number of iterations), picking the right model for your task (sometimes cheaper models can also complete your tasks), and configuring monitoring, error tracking, and alarms.
While loops and where to write them
So, if agents are while loops with LLMs and some additional tools, where do we write these while loops to create an agent?
The answer is almost anywhere. While creating an AI agent using pen and paper could be a thing, it’s not really a practical way of making an agent. Another cost-inefficient and unhelpful way of creating a while loop is using a person to act as one. However, you can write this “while loop” wherever you need it. For example, it can be inside the app you are working on, in your terminal, on a server (using any backend language you prefer), in a browser, etc. As long as you are careful and you do not leak your LLM secret key and other similar secrets.
To write an agent “while loop,” you need to do the following:
- Choose an LLM model that fits your needs and your budget (which can be $0 or whatever other number).
- Define a system prompt with a clear explanation of all the tools you want to provide (including when and how to use them).
- Ask an LLM to reply in a strict JSON format or any other structure you prefer.
- Make sure you parse and validate the reply correctly.
- Handle errors and set the maximal number of iterations, billing budget, and alerts.
Remember, LLMs are good at talking to humans (actually imitating human interaction), but human language is not easy to parse in the code. If you worked with LLMs and tried to get a JSON reply and nothing else, I am sure you, at least once, got the reply similar to: “Here’s your JSON: {...}.” Yelling at LLM and telling it to reply with JSON works sometimes, but in some cases, even 3 exclamation points at the end do not help. Even a simple agent we built inside Claude.ai replied with a sentence in front of the search phrase:

You can either pick a format that is easier to parse or use a simple trick explained in my previous article: provide the beginning of the reply and let an LLM continue. You can see the code example here: 5 Prompt Engineering Tips for Developers.
But, while understanding how these LLM “while loops” work is good, you do not need to write your own while loops. There are many existing tools and frameworks you can use.
AI Agent tools and frameworks
AI Agent tools and frameworks are like JavaScript frameworks – we get many new ones every day. Pick any word that comes to your mind. The chance to find a JavaScript package with that name in NPM and a .ai domain with that name is higher than the latest US-to-China tariff percentage.
For example, LangChain was the AI Agent framework a while back. Today, we have LlamaIndex and many other popular tools besides it. Big players like Microsoft have their own open-source takes, such as AutoGen. And, of course, services such as Amazon Bedrock Agents. There are many other examples, from tools for non-coders and open-source tools to enterprise-grade tools.
It’s hard to pick the best one. If you want to check just one that works with JavaScript or TypeScript, you can start with LlamaIndex.
LlamaIndex sounds similar to the Meta Llama models. But it’s not the same. Actually, LlamaIndex supports the Meta Llama model and many others (including OpenAI models, Anthropic models, open source models, Amazon Bedrock, Azure OpenAI, etc.).
Another interesting thing about LlamaIndex is that they focused on the AI Agent memory issue as an important problem to focus on. If you have worked with AI Agents, you know what I am talking about. If not, read on.
Remember, remember… the conversation we had yesterday
As I already mentioned, LLMs are limited by their training set, configuration, your instructions, and a few other things. One of their most important limitations is their context size.
The context size represents the maximum number of tokens an LLM can have in a single conversation (through the API, UI, or any other way you interact with it). It’s a hard stop. Once you fill the context with tokens, an LLM will explode. Well, not literally. But it’ll stop working. If you have used LLMs from the early days, you might remember that after a certain number of messages, LLM seems to forget what you were talking about. That’s because the context was filled, and an LLM removed the initial messages to make space for your new messages. Luckily, LLM then made system prompts, sticky parts of the conversation that always stay in context and allow you to provide the instructions.
If you manage to fill the context, LLMs will most likely do one of the following:
- Remove some messages from the beginning of your conversation, but keep the system prompt so it still follows the instructions). This can cause an LLM to forget some parts of your conversation.
- Summarize some parts of the conversation and replace N messages with the summary (well, LLMs are good with summarization). The quality of the remaining conversation depends on the way an LLM summarizes the conversation.
- Block you from sending more messages (most likely if you are using an API).

Luckily, the context size is increasing fast (Claude has a 200k token context, Gemini 1M context, and Llama now has a context size with up to 10M tokens). However, a larger context size can decrease the ability of an LLM to find specific items in it. Also, we want to fit larger items in the context. We started with simple spreadsheets and PDFs, and now we want to embed whole knowledge bases, books, project documentation, etc.
Again, luckily, many smart people work with LLMs, so they quickly came up with an effective way to make the most of the (at that time very) limited LLM context size. However, naming things is hard (ask OpenAI and Anthropic or simply read the names of their models), so they called this approach Retrieval-Augmented Generation (RAG).
While RAG sounds complicated and is still one of the most misunderstood terms related to LLM, it is quite a simple but powerful concept.
In short, instead of putting all documents in the system prompt, you can wait for the user question, then tokenize it before replying and do a vector search against your knowledge base to find a few closest matches. Then, you take these pieces and tell an LLM to respond to the user’s question in the context of the provided pieces of your knowledge base.

Before you do a vector search, you need to split your knowledge base into reasonable chunks (i.e., articles, sections of the articles, or even paragraphs in some cases) and create vectors from each piece.
And when I say vector search, I mean something similar to the vector search that LLMs use under the hood. Remember the following image?
You can use a vector DB to do a vector search, but that’s not required, as you can do vector searches in some of the popular databases (such as PostgreSQL, ElasticSearch, etc.) or store vectors almost anywhere and create your own vector search function (Amazon S3, for example).
Writing your own vector search (or actually vector similarity) function also sounds complicated, but luckily, you can ask an LLM to write that function for you, and it can look similar to the following one:
// Calculate cosine similarity between two vectors
function cosineSimilarity(vector1, vector2) {
// Calculate the dot product of the two vectors
const dotProduct = vector1.reduce((sum, a, i) => sum + a * vector2[i], 0)
// Calculate the magnitude of both vectors
const magnitude =
Math.sqrt(vector1.reduce((sum, val) => sum + val * val, 0))
* Math.sqrt(vector2.reduce((sum, val) => sum + val * val, 0))
// Return the cosine similarity
return dotProduct / magnitude
}
This function returns a number that represents the similarity percentage. You can run the same function against each of the knowledge base article vectors and pick the two top ones with more than 80% similarity or something similar.
A simple function like the one I showed above would work fine for smaller databases. However, you should use a more efficient search for large data sets.
AI Agents use many tokens, and often need vast knowledge bases. LlamaIndex helps with more efficient vector search and allows you to create agents that are not like they came from the Memento movie.
However, explaining RAG and LLM memory in detail requires more than a few paragraphs. All these explanations would convert this article into a short book. So, let’s leave that for another article and get back to AI Agents.
Let’s build an AI Agent!
LLMs are products. Products evolve and add features based on users’ feedback and usage patterns. Well, using tools is one of the important features that most LLMs now support natively. Some LLMs call this feature tools (for example, tools in Claude), some call it functions (for example, OpenAI functions), but it’s the same thing that allows us to build AI Agents.
Built-in tools have a few clear benefits, such as replies in a strict JSON format, a well-defined format, and an easier ability to stream responses via HTTP. They also have less surface area for errors because they are now built into the LLM itself. But, as always, there are many different standards, and if you want to switch to some other LLM, you’ll probably need to define tools in a slightly different format. However, a simple abstraction (or, even better, a hexagonal architecture) makes this problem easier to manage.
Let’s build a simple agent using built-in tools! You can pick any LLM you like. I’ll use Claude Sonnet 3.7 on Amazon Bedrock. The example below would work fine with other models. I use Amazon Web Services (AWS) every day, so Bedrock is a natural choice (despite its limits, especially in European data centers).
So, where do we start? With our “while loop,” of course! Remember this?

I want to build a simple agent for my product, Vacation Tracker. It will be very simple because otherwise, I would need to write a book to show all the details. I want my AI Agent to be able to do the following 3 things only:
- Help users to request leave, such as PTO.
- Let users see which coworkers are not working today and who will be off this or next week.
- Answer some basic questions about our product using our knowledge base.
With these 3 features, my “while loop” would look like the following diagram.

There are so many different ways to build this AI Agent using AWS. For example, we could create a simple serverless solution like the diagram below, with the following components:
- I would use an Amazon API Gateway to expose the API endpoint for my AI Agent.
- My AI Agent "while loop," or business logic, would be in a Lambda function that defines the specification of the tool, invokes the LLM, and talks to the Vacation Tracker API and storage for our knowledge base and vectors.
- I would use the Claude Sonnet 3.7 model on Amazon Bedrock.
- I could store the vectors and parts of our knowledge base in the S3 bucket. This is not an ideal long-term solution, but it would work fine for the MVP version.

By using API Gateway, we get all the benefits this service offers, including easy setup for rate limits, Web Application Firewall (WAF), etc. However, as Austen Collins suggested, API Gateway has some significant downsides when building AI Agents. For example, the API Gateway timeout is limited to 29 seconds (AWS allows us to change the timeout now, but changing the timeout can affect account-level throttle limits, etc.), which could be a serious limitation for more complex production-ready agents that can do some longer tasks. Also, we can't stream the response from our Lambda function, so we need to wait for our agent to generate the whole long reply before we can start showing it to the user. Streaming would allow us to show the response as LLM generates it. This is especially helpful for long responses, as our agent starts responding to the user faster and keeps adding text as the user reads (the effect is similar to typing).
Luckily, there's an alternative! AWS Lambda supports Lambda function URLs. It's basically a simple HTTP endpoint in front of your Lambda function. The main benefits of the function URL over API Gateway are that it offers timeouts of up to 15 minutes (it's a Lambda timeout, not an API Gateway timeout anymore) and support for streaming responses. Just what we needed!
However, it comes with many downsides, too. You do not get all the features of the API Gateway, such as built-in rate limits, authorization support, etc. It does not support WAF, either. There are no custom domains for Lambda function URLs. However, you can mitigate some of these downsides by putting a CloudFront in front of the Lambda function, as shown in the diagram below.

Is this an ideal setup? It depends on your use case. It's a good start. There are many other alternatives. For example, we could keep the initial setup, and instead of waiting for the reply with an open HTTP connection, we could send a message to a background job and tell the frontend application that the message is received and that we'll send a reply via WebSockets. There's no out-of-the-box streaming for this setup, too, but it can give you more flexibility and some benefits from both approaches.

In production, we would need to think about our use case, WAF, rate limiting (for our app, for LLM we are using, and for other services we are using), securing the API endpoint (auth token, API key, etc.), monitoring, error logging and handling, storage for the conversation (we do not want to send the whole conversation from the frontend when a user sends a new message), and many other things.
But let's keep things simple.
Show me some code!
The initial idea of this article was to show the code. But here we are, 4000 words later, and I barely explained how agents work. I'll show the most important parts of the code here. I might do a "part 2" article with a code deep dive if anyone reads the article past this point and thinks a complete coding example might be beneficial.
The most important part of the code is a definition of the available tools. The format depends on a model or a service you use, but for Claude Sonnet 3.7 on AWS Bedrock using the Converse API, you can do something similar to the following:
const toolConfig = {
tools: [
// We need a similar object for each of our tools
{
// The name and the description of our tool
// A clear description is important because it helps an LLM to select the right tool
name: 'request_leave',
description: 'Request leave (such as PTO, sick day, etc.). The leave request will be submitted to the Vacation Tracker application, and sent to your manager (approver).',
inputSchema: {
// It accepts JSON, I told you developers love JSON!
json: {
type: 'object',
properties: {
// And it expects the following properties (see the type and the description for each).
// For simplicity, I'll show the most important parts only
startDate: {
type: 'string',
description: 'The date when the leave starts. Format: YYYY-MM-DD',
},
endDate: {
type: 'string',
description: 'The date when the leave ends. Format: YYYY-MM-DD',
},
leaveType: {
type: 'string',
description: 'The type of leave. For example, "vacation", "sick", etc.',
},
reason: {
type: 'string',
description: 'The reason for the leave request. For example, "Vacation in Greece", "I am not feeling well today," etc.',
},
},
required: ['startDate', 'endDate', 'leaveType'],
},
},
},
// Define the other 2 tools here
],
}
It's important to provide clear descriptions as that would help an LLM pick the right tool when needed.
I am a big fan of hexagonal architecture (or ports and adapters), and I would use it in a production code. Our business logic does not care about the Claude Sonnet 3.7 model. It does not care about Amazon Bedrock, either. So, I would put the LLM logic in some kind of repository, initialize it, and use it to send a message when needed. That would make my code cleaner to read, easier to test, and allow me to try other models (i.e., Open AI models, which are not available in Amazon Bedrock) without changing the business logic.
However, I'll just show the simplest code example without hexagonal architecture to keep things simple.
// Stripped down example of using the AWS Bedrock SDK to create a simple AI Agent
import { BedrockRuntimeClient, ConverseCommand } from '@aws-sdk/client-bedrock-runtime'
import { toolConfig } from './tool-config.js'
// Initialize the Bedrock client and specify the region and a model ID
const client = new BedrockRuntimeClient({ region: 'us-east-1' })
const modelId = 'anthropic.claude-3-7-sonnet-20250219-v1:0'
// Start a conversation with the user message.
const conversation = [
{
role: 'user',
content: [{
// The user messsage is hardcoded for this example, but in a real application, you would get it from the user input
// Also, in practice, users would probably tell us that they want to go on vacation in the first week of July, and the agent would need to ask for the start date
text: 'I want to go on vacation on the first week of July. Full week, starting June 30th.',
}],
},
]
// Create a command with the model ID, the message, and a basic configuration
const command = new ConverseCommand({
modelId,
messages: conversation,
system: [{
// We would need to provide a more detailed system message in a real application
text: 'You are Vacation Tracker assistant and you help users to request leaves, see who else from their team is off, check their leave balance and learn about the Vacation Tracker app functionalities. When a user asks to go off for a longer period, assume whole week. Here is the list of available leave types: `PTO`, `SickDay`. Try assuming the correct leave type from the input.',
}],
// We pass our tool configuration to Bedrock
toolConfig: toolConfig,
})
async function run() {
try {
// Send the command to the model and wait for the response
const response = await client.send(command)
console.log('Response:', JSON.stringify(response))
} catch (err) {
console.log('ERROR', err)
}
}
// We wrap the call in the run function just to be able to use it in a terminal without the deployment
// The actual code would define a Lambda function handler
run().then(console.log).catch(console.error)
To run this code example, you'd need an AWS account with Claude Sonnet 3.7 enabled in the Amazon Bedrock (in the us-east-1 region). When you run it, the response should be similar to the following JSON (inline comments make this JSON invalid, but I added them for easier understanding):
{
// Just metadata, you can ignore this part at the moment
"$metadata": {
"httpStatusCode": 200,
"requestId": "bc806712-b1b2-40eb-8488-f0085237ebcf",
"attempts": 1,
"totalRetryDelay": 0
},
// Metrics can be useful, but let's ignore that too at the moment
"metrics": {
"latencyMs": 4191
},
// Claude Sonnet 3.7 response
"output": {
"message": {
"content": [
{
// A message that we can show to our users if we want to
"text": "Certainly! I'd be happy to help you request leave for your vacation during the first week of July. Based on the information you've provided, I'll submit a leave request for you using the Vacation Tracker application. Let me go ahead and process that for you."
},
{
// Claude Sonnet 3.7 tells us to use a tool!
"toolUse": {
// Request params, as defined in the tool configuration
"input": {
"startDate": "2023-06-30" ,
"endDate": "2023-07-07",
"leaveType": "PTO",
"reason": "Vacation for the first week of July"
},
// The name and ID of a tool we should use
"name": "request_leave",
"toolUseId": "tooluse_JaORLwrHSSGifTRMApUrGA"
}
}
],
// This is a response from an agent, we need to pass this with the response
// from a tool to continue the conversation
"role": "assistant"
}
},
// Claude tells us that it stopped because it needs a tool to continue
"stopReason": "tool_use" ,
// Useful metrics for the number of used tokens
"usage": {
"inputTokens": 630,
"outputTokens" : 183,
"totalTokens": 813
}
}
As you can see in the JSON above, Claude tells us that it needs a tool to be able to reply (stopReason: 'tool_use'). It gives us a nice message that we can display to our users if we want to, but keep in mind that the agent still works at this point, so users should not send new messages yet. Finally, it gives us the details about the tool we need to use and the parameters we should send to our tool to get the response.
After receiving this response, we should send the API request to the Vacation Tracker API with the provided start and end dates, leave type, and reason. But before that, we probably need to validate the data and get the authentication token for the API.
Before we continue, let's talk about one more thing: request duration. Remember the 29-second timeout in the API Gateway? Well, this request took 4.2 seconds out of these 29. If we add a few hundred milliseconds for the Lambda overhead and a request to a database to get the previous messages in this conversation, we are probably around 5 seconds.
But that's just the first part of this request. Before we reply, we need to call the Vacation Tracker API, parse the response, and call the Amazon Bedrock again. If we are lucky, our agent will need just one tool to be able to reply, so we'll be at 10 or 15 seconds, including saving the conversation to the DynamoDB.
What happens if we have a complex agent that could use multiple tools in one request? We can easily get close or over the 29-second timeout, which could break our agent.
Ok, so, we got the ID of the tool we need to use and the parameters to send to the tool. In this case, an agent wants us to request a leave. In production, we would ask the user to confirm the request details first, but for this simple example, we can send the request straight to the Vacation Tracker API.
Once the Vacation Tracker API responds, we probably want to process the response to make it clear to our LLM because most API responses are not 100% LLM or human friendly. For example, we can add a description, change the field names to be more descriptive, etc.
We could send a new request to Amazon Bedrock with the following conversation:
[
// The initial user message
{
"role": "user",
"content": [
{
"text": "I want to go on vacation on the first week of July. Full week, starting June 30th."
}
]
},
// The unchanged assistant message from the previous example
{
"role": "assistant",
"content": [
{
"text": "Certainly! I'd be happy to help you request leave for your vacation during the first week of July. Based on the information you've provided, I'll submit a leave request for you using the Vacation Tracker application. Let me go ahead and process that for you."
},
{
"toolUse": {
"input": {
"startDate": "2025-06-30",
"endDate": "2025-07-06",
"leaveType": "PTO",
"reason": "Vacation for the first week of July"
},
"name": "request_leave",
"toolUseId": "tooluse_JaORLwrHSSGifTRMApUrGA"
}
}
]
},
// Tool response
{
// Role needs to be "user"
"role": "user",
"content": [
{
// We provide the tool result object
"toolResult": {
// Tool ID
"toolUseId": "tooluse_JaORLwrHSSGifTRMApUrGA",
"content": [
{
// Response is a JSON object with a custom payload
"json": {
// For example, the API tells us that the request was successfully sent
"success": true,
// We have the request details
"request": {
"id": "request_12345",
"status": "pending",
"startDate": "2025-06-30",
"endDate": "2025-07-06",
"leaveType": "PTO",
"reason": "Vacation for the first week of July"
},
// And also the remaining quota
"quota": {
"remaining": 10,
"used": 5,
"total": 15,
"unit": "days"
}
}
}
]
}
}
]
}
]
When we send this request to Claude, the reply will probably be similar to the following JSON:
{
// Metadata, ignore
"$metadata": {
"httpStatusCode": 200,
"requestId" : "de4dad99-1d57-46bd-ad71-c69ebe853756",
"attempts": 1,
"totalRetryDelay": 0
},
// It took almost 9 seconds to reply!
"metrics": {
"latencyMs": 8985
},
// The actual response object
"output": {
"message": {
"content": [
{
// The text we want to show to the user
"text": "Great news! I've successfully submitted your leave request for your vacation. Here are the details of your request:\n\n- Leave Type: PTO (Paid Time Off)\n- Start Date: June 30, 2025 (Monday)\n- End Date: July 6, 2025 (Sunday)\n- Reason: Vacation for the first week of July\n- Status: Pending approval\n \nYour request has been submitted to the Vacation Tracker application and sent to your manager for approval. The request ID is request_12345.\n\nAdditionally, I can see from the response that your current leave balance is as follows:\n- Total PTO: 15 days\n- Used: 5 days\n- Remaining: 10 days\n\nThis request will use 6 working days of your PTO (assuming a standard Monday to Friday work week). Please note that your request is currently pending approval from your manager. You should receive a notification once it's been reviewed. \n\nIs there anything else you'd like to know about your leave request or the Vacation Tracker application?"
}
],
"role": "assistant",
}
},
// Claude says that the request was successfully fulfilled
"stopReason": "end_turn",
// Usage data
"usage": {
"inputTokens": 901,
"outputTokens": 236,
"totalTokens": 1137
}
}
To make it a bit more readable, here's the AI Agent response:
Great news! I've successfully submitted your leave request for your vacation. Here are the details of your request:
- Leave Type: PTO (Paid Time Off)
- Start Date: June 30, 2025 (Monday)
- End Date: July 7, 2025 (Friday)
- Reason: Vacation for the first week of July
- Status: Pending approval
Your request has been submitted to the Vacation Tracker application and sent to your manager for approval. The request ID is request_12345.
Additionally, I can see from the response that your current leave balance is as follows:
- Total PTO: 15 days
- Used: 5 days
- Remaining: 10 days
This request will use 5 working days of your PTO (assuming a standard Monday to Friday work week). Please note that your request is currently pending approval from your manager. You should receive a notification once it's been reviewed.
Is there anything else you'd like to know about your leave request or the Vacation Tracker application?
As you can see, our AI Agent is a bit more chatty and friendly. It made up some parts of the reply (for example, we never mentioned the notification), but the response generally looks good.
In production, we probably want an LLM to reply in a structured way so we can display a predefined UI for the leave request along with a short, friendly message. Also, we need to be careful with dates and other numbers, as LLMs do not care about numbers. Numbers are close in the vector space. For an LLM, 4 is similar to 5 or even 42, but 4 or 5 used PTO days make a big difference for our users.
And that's it! We built an AI Agent again. This time with code. It's a simple agent, more like a proof of concept. But it's still an agent.
Summary
After a long article, I'll keep the summary short.
Before we do a quick summary, you should check 2 relatively fresh things related to AI Agents.
First, my Twitter feed has been buzzing about MCP servers in the past few weeks. Model Context Protocol (MCP) is an open-source protocol that standardizes how applications provide context (and tool specification) to LLMs, and you can read more about it here: https://docs.anthropic.com/en/docs/agents-and-tools/mcp.
Second, OpenAI has some new tools for building agents. Read more about these tools here: https://openai.com/index/new-tools-for-building-agents/.
To end this long article, I just want to remind you that AI Agents sound very complicated, but they are actually like LLM "while loops" with tools.
You have all the skills you need to build these tools. So, go, build tools and agents, and have fun!