![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)















































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
























































































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)












































































































![Apple Drops New Immersive Adventure Episode for Vision Pro: 'Hill Climb' [Video]](https://www.iclarified.com/images/news/97133/97133/97133-640.jpg)

![Most iPhones Sold in the U.S. Will Be Made in India by 2026 [Report]](https://www.iclarified.com/images/news/97130/97130/97130-640.jpg)
![Apple to Shift Robotics Unit From AI Division to Hardware Engineering [Report]](https://www.iclarified.com/images/news/97128/97128/97128-640.jpg)























































































































Advancements in Information Retrieval: Efficiency, Multimodality, and Security in Contemporary Computer Science Research
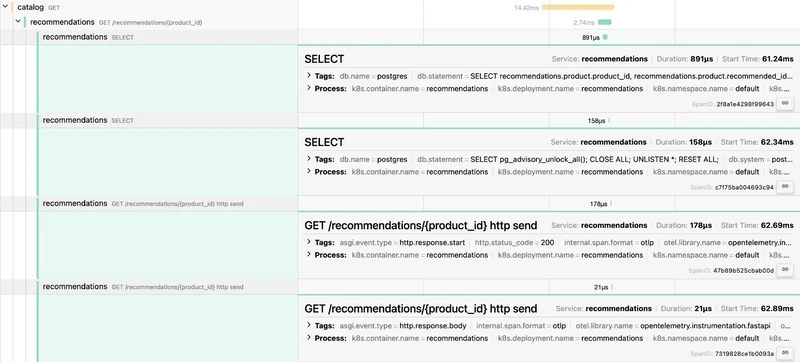
This article is part of AI Frontiers, a series exploring groundbreaking computer science and artificial intelligence research from arXiv. Key papers are summarized, complex concepts in machine learning and computational theory are demystified, and innovations shaping our technological future are highlighted. The focus here is on recent developments in the field of information retrieval within computer science, drawing from a selection of papers published on April 23, 2025. This synthesis examines the state of the art, identifies central themes, evaluates methodologies, and discusses critical findings while pointing to future research directions. The discussion is structured to provide both depth and accessibility for a broad academic audience. Introduction: Scope and Significance of Information Retrieval Information retrieval, a pivotal subfield of computer science, encompasses the design of algorithms and systems to locate, organize, and present relevant information from vast and diverse datasets. This field underpins essential technologies such as search engines, recommendation systems, and personalized content delivery platforms. Its importance lies in addressing the challenge of information overload in the digital era, where data generation outpaces human capacity to process it. Effective retrieval systems not only enhance access to knowledge but also influence decision-making across domains like education, commerce, and healthcare. The papers reviewed in this synthesis, all published on April 23, 2025, reflect cutting-edge efforts to tackle persistent and emerging challenges in this domain. Through an analysis of these works, this article elucidates key trends, methodologies, and implications for the future of information retrieval. Defining Information Retrieval and Its Broader Impact At its core, information retrieval involves the extraction of pertinent data—be it text, images, or multimedia—from large repositories in response to user queries or needs. The significance of this field extends beyond technical implementation; it shapes how individuals interact with information in daily life. Search engines like Google rely on sophisticated retrieval algorithms to deliver results in milliseconds, while recommendation systems on platforms like Netflix or Amazon personalize user experiences by predicting preferences. The societal impact is profound, as these systems mediate access to information, influence consumer behavior, and even affect cultural trends through content curation. However, challenges such as balancing speed with accuracy, ensuring privacy, and handling diverse data types persist. The research discussed herein addresses these issues, offering novel solutions and highlighting areas requiring further exploration. Major Themes in Contemporary Information Retrieval Research Several thematic threads emerge from the body of work under review, reflecting the multifaceted nature of information retrieval challenges. These themes provide a framework for understanding the direction of current research and its potential applications. First, efficient search and retrieval optimization stand out as a primary concern. Techniques aimed at reducing latency without compromising result quality are critical for real-time applications. For instance, Carlson et al. (2025) propose superblock pruning, a method to accelerate document retrieval by hierarchically organizing data and skipping irrelevant segments, demonstrating significant speed improvements on benchmark datasets. This approach underscores the push for accessible, high-performance systems even on constrained hardware. Second, multimodal recommendation systems represent a growing area of interest, focusing on integrating diverse data types such as text, images, and audio to enhance personalization. A notable example is the work by Guo et al. (2025), which employs multi-modal hypergraph contrastive learning to connect users and items across modalities, addressing data sparsity issues. This theme highlights the shift toward richer, more context-aware systems capable of capturing nuanced user preferences. Third, security and privacy in data representations have gained prominence as dense vector embeddings become ubiquitous in retrieval tasks. Tragoudaras et al. (2025) expose vulnerabilities in sentence embeddings, showing how generative inversion attacks can reconstruct original text, thus risking sensitive information leakage. This theme emphasizes the urgent need for secure data handling in an era of pervasive digital footprints. Fourth, the integration of large language models and foundation models into retrieval and recommendation frameworks marks a transformative trend. Huang et al. (2025) provide a comprehensive survey of how these models enhance feature representation, enable generative recommendations, and support interactive agent systems, pointing to a future of more intuitive and adaptive technologies. Finally, handling missing or incom

This article is part of AI Frontiers, a series exploring groundbreaking computer science and artificial intelligence research from arXiv. Key papers are summarized, complex concepts in machine learning and computational theory are demystified, and innovations shaping our technological future are highlighted. The focus here is on recent developments in the field of information retrieval within computer science, drawing from a selection of papers published on April 23, 2025. This synthesis examines the state of the art, identifies central themes, evaluates methodologies, and discusses critical findings while pointing to future research directions. The discussion is structured to provide both depth and accessibility for a broad academic audience.
Introduction: Scope and Significance of Information Retrieval
Information retrieval, a pivotal subfield of computer science, encompasses the design of algorithms and systems to locate, organize, and present relevant information from vast and diverse datasets. This field underpins essential technologies such as search engines, recommendation systems, and personalized content delivery platforms. Its importance lies in addressing the challenge of information overload in the digital era, where data generation outpaces human capacity to process it. Effective retrieval systems not only enhance access to knowledge but also influence decision-making across domains like education, commerce, and healthcare. The papers reviewed in this synthesis, all published on April 23, 2025, reflect cutting-edge efforts to tackle persistent and emerging challenges in this domain. Through an analysis of these works, this article elucidates key trends, methodologies, and implications for the future of information retrieval.
Defining Information Retrieval and Its Broader Impact
At its core, information retrieval involves the extraction of pertinent data—be it text, images, or multimedia—from large repositories in response to user queries or needs. The significance of this field extends beyond technical implementation; it shapes how individuals interact with information in daily life. Search engines like Google rely on sophisticated retrieval algorithms to deliver results in milliseconds, while recommendation systems on platforms like Netflix or Amazon personalize user experiences by predicting preferences. The societal impact is profound, as these systems mediate access to information, influence consumer behavior, and even affect cultural trends through content curation. However, challenges such as balancing speed with accuracy, ensuring privacy, and handling diverse data types persist. The research discussed herein addresses these issues, offering novel solutions and highlighting areas requiring further exploration.
Major Themes in Contemporary Information Retrieval Research
Several thematic threads emerge from the body of work under review, reflecting the multifaceted nature of information retrieval challenges. These themes provide a framework for understanding the direction of current research and its potential applications. First, efficient search and retrieval optimization stand out as a primary concern. Techniques aimed at reducing latency without compromising result quality are critical for real-time applications. For instance, Carlson et al. (2025) propose superblock pruning, a method to accelerate document retrieval by hierarchically organizing data and skipping irrelevant segments, demonstrating significant speed improvements on benchmark datasets. This approach underscores the push for accessible, high-performance systems even on constrained hardware.
Second, multimodal recommendation systems represent a growing area of interest, focusing on integrating diverse data types such as text, images, and audio to enhance personalization. A notable example is the work by Guo et al. (2025), which employs multi-modal hypergraph contrastive learning to connect users and items across modalities, addressing data sparsity issues. This theme highlights the shift toward richer, more context-aware systems capable of capturing nuanced user preferences.
Third, security and privacy in data representations have gained prominence as dense vector embeddings become ubiquitous in retrieval tasks. Tragoudaras et al. (2025) expose vulnerabilities in sentence embeddings, showing how generative inversion attacks can reconstruct original text, thus risking sensitive information leakage. This theme emphasizes the urgent need for secure data handling in an era of pervasive digital footprints.
Fourth, the integration of large language models and foundation models into retrieval and recommendation frameworks marks a transformative trend. Huang et al. (2025) provide a comprehensive survey of how these models enhance feature representation, enable generative recommendations, and support interactive agent systems, pointing to a future of more intuitive and adaptive technologies.
Finally, handling missing or incomplete data remains a critical challenge, particularly in multimodal contexts. Kim et al. (2025) introduce a framework to disentangle and generate missing modality features using available data, ensuring robust performance despite incomplete information. Collectively, these themes illustrate the diversity of obstacles and innovations in information retrieval, from operational efficiency to ethical considerations.
Methodological Approaches in Information Retrieval Research
The methodologies employed across these studies reveal a blend of established techniques and novel adaptations tailored to specific challenges. One prevalent approach is contrastive learning, often used to refine feature representations by distinguishing between similar and dissimilar data points. This method, as applied by Guo et al. (2025), enhances the quality of embeddings in multimodal recommendation systems. While effective in capturing complex relationships, contrastive learning demands careful design of training pairs and significant computational resources, posing scalability concerns.
Another common methodology involves generative models, which are leveraged for data synthesis and process unification. Zhang et al. (2025) utilize a generative model to combine retrieval and ranking stages, minimizing information loss and boosting performance. Although powerful, these models require extensive training data and computational power, and their lack of interpretability can complicate error analysis.
Hierarchical structuring and pruning techniques also feature prominently, particularly in efforts to optimize search efficiency. The superblock pruning method by Carlson et al. (2025) organizes data into nested groups, enabling early exclusion of irrelevant segments. This approach excels in resource-constrained environments but risks overlooking relevant results if pruning criteria are overly stringent.
Additionally, multimodal fusion with weighting mechanisms is widely adopted to integrate diverse data sources. Dong et al. (2025) apply weighting schemes to balance the influence of different modalities based on reliability, improving recommendation robustness. However, determining optimal weights often requires domain-specific assumptions, limiting generalizability.
Lastly, embedding and vector space analysis underpin many retrieval tasks by representing data in high-dimensional spaces. Fu et al. (2025) explore dimension-reduction methods to preserve nearest-neighbor relationships in vector search, though such techniques can distort critical structures if not carefully tailored. These methodologies collectively balance innovation with practical constraints, shaping the technical landscape of information retrieval.
Key Findings and Comparative Analysis
The findings from these studies offer valuable insights into the progress and potential of information retrieval systems. A standout result is the efficacy of superblock pruning, as demonstrated by Carlson et al. (2025), which achieves significant speed gains over existing baselines on datasets like MS MARCO, even on single-threaded CPUs. This contrasts with traditional methods that often rely on hardware acceleration, highlighting a pathway to democratized access to fast retrieval systems.
In the realm of data security, Tragoudaras et al. (2025) reveal a critical vulnerability: sentence embeddings can be inverted to reconstruct original text, exposing sensitive content. This finding differs from prior assumptions of embeddings as secure abstractions, necessitating a reevaluation of their use in privacy-sensitive applications compared to more safeguarded sparse representations.
On the recommendation front, Zhang et al. (2025) present a unified generative model for retrieval and ranking, outperforming sequential approaches by reducing inter-stage information loss. This contrasts with conventional systems where separate modules often lead to inefficiencies, suggesting a more integrated future for content delivery platforms.
Huang et al. (2025) synthesize evidence that foundation models surpass traditional recommendation methods across multiple tasks, particularly in handling cold-start scenarios and multimodal data. This broad improvement contrasts with earlier models limited by data specificity, indicating a paradigm shift toward general-purpose, adaptable systems.
Lastly, Kim et al. (2025) address missing modalities in recommendations by generating absent features from available data, a method that maintains performance where traditional systems falter. Compared to approaches ignoring incomplete data, this framework offers a practical solution for real-world applications with imperfect datasets. These findings collectively underscore rapid advancements while revealing trade-offs between efficiency, security, and adaptability.
Influential Works in the Current Landscape
Among the reviewed papers, several stand out for their originality and potential impact on information retrieval. Carlson et al. (2025) provide a seminal contribution with their dynamic superblock pruning technique, redefining efficiency in sparse retrieval systems. Their focus on speed without accuracy loss addresses a core operational challenge, making their work a benchmark for future optimization studies.
Tragoudaras et al. (2025) offer a critical perspective on data security through their analysis of generative embedding inversion attacks. By demonstrating the privacy risks inherent in sentence embeddings, this study serves as a catalyst for developing secure representation methods, influencing both research and application design.
Huang et al. (2025) deliver an authoritative survey on foundation model-powered recommender systems, mapping out paradigms from feature enhancement to agentic interactions. This comprehensive overview not only consolidates current knowledge but also guides future explorations into large-scale model integration, positioning it as a foundational reference for the field.
Guo et al. (2025) advance multimodal recommendations through hypergraph contrastive learning, tackling data sparsity with innovative data structuring. Their approach exemplifies the potential of cross-modal integration, offering a model for personalized systems in diverse contexts.
Finally, Kim et al. (2025) address a practical yet underexplored issue with their framework for missing modality scenarios in recommendations. By generating absent features, their method ensures robustness, providing a blueprint for handling incomplete data in real-world settings. These works collectively represent the breadth and depth of current research, each contributing uniquely to the evolving discourse.
Critical Assessment of Progress and Future Directions
The body of research reviewed reflects substantial progress in information retrieval, particularly in enhancing efficiency, leveraging multimodal data, and integrating advanced models. Techniques like superblock pruning and unified generative models demonstrate how operational challenges can be addressed through innovative structuring and process integration. Meanwhile, the adoption of foundation models signals a shift toward more versatile, context-aware systems capable of meeting complex user needs. Efforts to handle missing data further illustrate adaptability to real-world constraints, ensuring relevance beyond controlled environments.
Nevertheless, significant challenges remain. Privacy and security concerns, as highlighted by studies on embedding vulnerabilities, pose ethical and technical dilemmas. The risk of information leakage in widely used representations necessitates urgent development of privacy-preserving techniques, potentially through differential privacy or secure computation methods. Additionally, the computational intensity of advanced models, such as foundation models and generative approaches, limits accessibility for smaller organizations or resource-constrained settings. Lightweight adaptations or optimization strategies could bridge this gap, broadening the impact of cutting-edge technologies.
Generalizability across diverse datasets and application contexts also warrants further investigation. Many proposed methods excel on specific benchmarks but lack evidence of robustness in varied scenarios, a gap that future research must address through cross-domain testing. Ethical considerations, including bias in pretrained data and the societal implications of personalized recommendations, represent another frontier. As retrieval systems increasingly influence behavior, ensuring fairness and transparency becomes paramount.
Looking ahead, several directions appear promising. First, interdisciplinary approaches combining information retrieval with human-computer interaction could yield systems that better understand and adapt to user intent in real time. Second, advancements in privacy-preserving embeddings and secure data handling will be critical to maintaining trust in digital systems. Third, the development of scalable, lightweight models could democratize access to state-of-the-art retrieval technologies, particularly in underserved regions or sectors. Finally, addressing ethical challenges through frameworks for bias mitigation and accountability will ensure that technological progress aligns with societal values. The trajectory of information retrieval research, as evidenced by these papers, suggests a field poised for transformative impact, provided these challenges are met with rigorous, collaborative effort.
Conclusion
This synthesis of recent research in information retrieval, drawn from papers published on April 23, 2025, underscores the dynamic evolution of the field. From optimizing search efficiency to securing data representations and harnessing multimodal data, the studies reviewed illuminate both achievements and obstacles. Methodological diversity, spanning contrastive learning to generative modeling, reflects a robust toolkit for innovation, while key findings highlight practical advancements and critical vulnerabilities. Influential works provide a foundation for future inquiry, guiding efforts to balance performance with ethical considerations. As the digital landscape continues to expand, the insights and directions outlined here offer a roadmap for advancing information retrieval in ways that are efficient, secure, and equitable.
References
- Carlson et al. (2025). Dynamic Superblock Pruning for Fast Learned Sparse Retrieval. arXiv:2504.17045
- Tragoudaras et al. (2025). Information Leakage of Sentence Embeddings via Generative Embedding Inversion Attacks. arXiv:2504.16609
- Guo et al. (2025). MMHCL: Multi-Modal Hypergraph Contrastive Learning for Recommendation. arXiv:2504.16576
- Huang et al. (2025). A Survey of Foundation Model-Powered Recommender Systems: From Feature-Based, Generative to Agentic Paradigms. arXiv:2504.16420
- Kim et al. (2025). Disentangling and Generating Modalities for Recommendation in Missing Modality Scenarios. arXiv:2504.16352
- Zhang et al. (2025). Killing Two Birds with One Stone: Unifying Retrieval and Ranking with a Single Generative Recommendation Model. arXiv:2504.16454
- Dong et al. (2025). Modality Reliability Guided Multimodal Recommendation. arXiv:2504.16524
- Fu et al. (2025). MPAD: A New Dimension-Reduction Method for Preserving Nearest Neighbors in High-Dimensional Vector Search. arXiv:2504.16335