











































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)














































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)






















































































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)











































































































![Apple Drops New Immersive Adventure Episode for Vision Pro: 'Hill Climb' [Video]](https://www.iclarified.com/images/news/97133/97133/97133-640.jpg)

![Most iPhones Sold in the U.S. Will Be Made in India by 2026 [Report]](https://www.iclarified.com/images/news/97130/97130/97130-640.jpg)
![Apple to Shift Robotics Unit From AI Division to Hardware Engineering [Report]](https://www.iclarified.com/images/news/97128/97128/97128-640.jpg)























































































































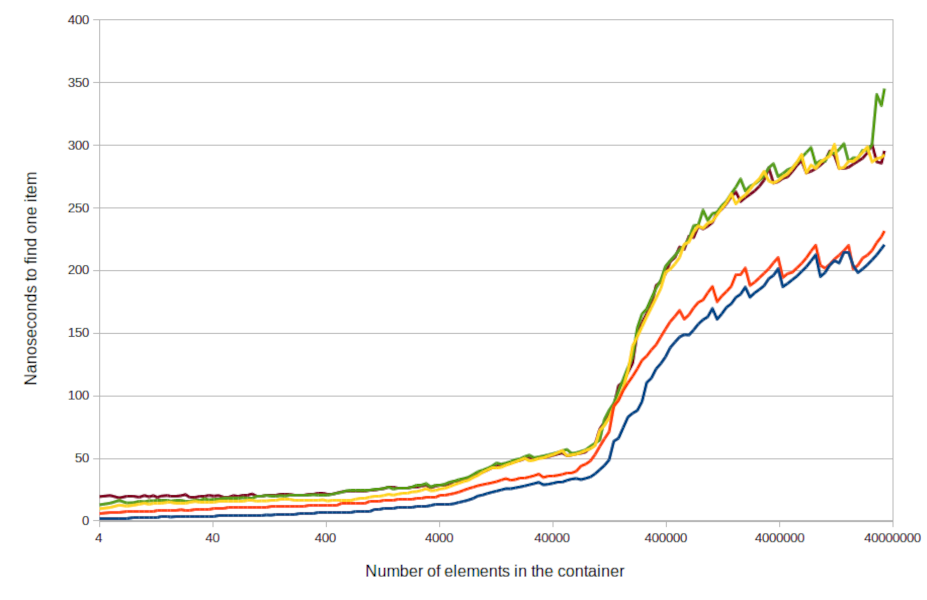
tl;dr Developers often struggle with the applicability of benchmarks, understanding semantic versioning, and identifying a common standard to effectively leverage the right models. These challenges often surface directly in developer workflows—whether it’s wiring up a model inside an IDE or deploying a feature that depends on consistent outputs across model versions. Devs also face frustration when trying to improve results—particularly since prompting techniques and optimisation mechanisms are still not fully understood. Beyond cost-to-performance ratio as the primary lens for model selection, the future of AI native developer workflow lie in a call for abstraction layers that simplify multi-model integration. How does GPT-4.1 measure up? GPT-4.1 was recently released, and OpenAI disclosed its 54.6% score on SWE-bench Verified, improving by 21.4% abs over GPT‑4o and 26.6% abs over GPT‑4.5—making it a leading model for coding within OpenAI: Are these results significant? Those figures are slightly under the scores reported by Google and Anthropic for Gemini 2.5 Pro (63.8%) and Claude 3.7 Sonnet (62.3%), on the same benchmark. More importantly, the release of this new model is raising some frustrations into how developers are thinking about the state of the ecosystem. Wider ecosystem frustrations Frustration 1: Alignment on Benchmarks “The benchmarks are so whack, how does [GPT-4.1] score so high on SWE bench (20% higher almost) and fall behind deepseek on [Aider Benchmark]? - Reddit user. Benchmark results (like SWE-bench, Aider Polyglot, etc.) have their own sets of requirements, making it challenging to understand and trust the true high performers within a domain. For example, when switching to a model with superior benchmark scores in your dev tool, it may fail to execute your requirements as effectively as the previous model—despite the improved metrics. Developers are thus struggling to agree on model performance as the results are so specific to the task, codebase and prompts. Internal benchmarking is emerging as a critical practice, with teams developing custom evaluation frameworks suited to their specific needs. For instance, in the aim to build a secure AI native development platform, Tessl is leveraging known benchmarks as well as their own to assess the most fitting model for their use cases. While there are valid reasons for enterprises and developers to do this, many devs still just want to get work done—not manage model quirks. It’s worth noting, as a side point, that Michelle Pokrass @OpenAI mentioned that “[GPT‑4.1] has a focus on real work usage and utility, and less on benchmarks,” further highlighting the idea that benchmarks shouldn’t be considered the ultimate source of truth. Frustration 2: Lack of Standardisation “4o with scheduled tasks”—why on earth is that a model and not a tool that other models can use?! — HackerNews user There’s a growing outcry from developers over the lack of standardisation across models—in features, and interfaces. Feature fragmentation has forced manual model selection for each task. If you’re building a dev assistant that uses image generation, CoT reasoning, and code completion, this often means duct-taping together multiple APIs and writing fallback logic. This is reminiscent of the browser wars before the 2000s—different versions of websites for Internet Explorer, Netscape, and later Firefox, because there were no standard implementations of HTML, CSS, or JavaScript. Standardisation often comes not from vendors agreeing, but from users banding together out of shared pain—think of the lock-in and interoperability pain prior to SQL. The good news is that we are seeing this already in a couple of places, think OpenAI’s API as the defacto standard, as well as Anthropic’s MCP. Prompt routers will be also be significant part of the solution. Analogous to HTTP router + HTML standard, a combination of prompt routing and standardisation may be the path to absolving these frustrations. Frustration 3: Semantic Drift in Model Versions GPT-4.1’s release highlights confusion. There was a lot of hype around GPT-5 coming out, and after the disappointing results from GPT-4.5, OpenAI released 4.1. Why GPT-4.1? The move back toward 4.1 feels like a semantic step backward (GPT-4.1 vs. GPT-4o vs. GPT-4 Turbo—what’s going on here?). While the claims and early results show improvement, and the focus between 4.5 and 4.1 differ, it still leaves room for confusion. If you’ve been building repeatable prompting flows, you will at the very least feel mildly overwhelmed by the “model maze”——is higher better? faster? newer? That said, this ambiguity hasn’t gone unnoticed. OpenAI has acknowledged these naming confusions, and we should expect future iterations to bring more clarity to the semantics and categorisation framework. Frustration 4: Prompting and Hand-W

tl;dr
- Developers often struggle with the applicability of benchmarks, understanding semantic versioning, and identifying a common standard to effectively leverage the right models.
- These challenges often surface directly in developer workflows—whether it’s wiring up a model inside an IDE or deploying a feature that depends on consistent outputs across model versions.
- Devs also face frustration when trying to improve results—particularly since prompting techniques and optimisation mechanisms are still not fully understood.
- Beyond cost-to-performance ratio as the primary lens for model selection, the future of AI native developer workflow lie in a call for abstraction layers that simplify multi-model integration.
How does GPT-4.1 measure up?
GPT-4.1 was recently released, and OpenAI disclosed its 54.6% score on SWE-bench Verified, improving by 21.4% abs over GPT‑4o and 26.6% abs over GPT‑4.5—making it a leading model for coding within OpenAI:
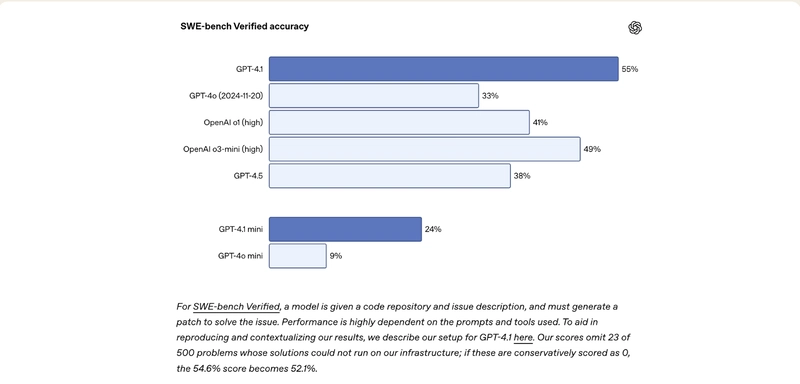
Are these results significant? Those figures are slightly under the scores reported by Google and Anthropic for Gemini 2.5 Pro (63.8%) and Claude 3.7 Sonnet (62.3%), on the same benchmark. More importantly, the release of this new model is raising some frustrations into how developers are thinking about the state of the ecosystem.
Wider ecosystem frustrations
Frustration 1: Alignment on Benchmarks
“The benchmarks are so whack, how does [GPT-4.1] score so high on SWE bench (20% higher almost) and fall behind deepseek on [Aider Benchmark]? - Reddit user.
Benchmark results (like SWE-bench, Aider Polyglot, etc.) have their own sets of requirements, making it challenging to understand and trust the true high performers within a domain. For example, when switching to a model with superior benchmark scores in your dev tool, it may fail to execute your requirements as effectively as the previous model—despite the improved metrics. Developers are thus struggling to agree on model performance as the results are so specific to the task, codebase and prompts.

Internal benchmarking is emerging as a critical practice, with teams developing custom evaluation frameworks suited to their specific needs. For instance, in the aim to build a secure AI native development platform, Tessl is leveraging known benchmarks as well as their own to assess the most fitting model for their use cases. While there are valid reasons for enterprises and developers to do this, many devs still just want to get work done—not manage model quirks.
It’s worth noting, as a side point, that Michelle Pokrass @OpenAI mentioned that “[GPT‑4.1] has a focus on real work usage and utility, and less on benchmarks,” further highlighting the idea that benchmarks shouldn’t be considered the ultimate source of truth.
Frustration 2: Lack of Standardisation
“4o with scheduled tasks”—why on earth is that a model and not a tool that other models can use?! — HackerNews user
There’s a growing outcry from developers over the lack of standardisation across models—in features, and interfaces. Feature fragmentation has forced manual model selection for each task. If you’re building a dev assistant that uses image generation, CoT reasoning, and code completion, this often means duct-taping together multiple APIs and writing fallback logic. This is reminiscent of the browser wars before the 2000s—different versions of websites for Internet Explorer, Netscape, and later Firefox, because there were no standard implementations of HTML, CSS, or JavaScript.
Standardisation often comes not from vendors agreeing, but from users banding together out of shared pain—think of the lock-in and interoperability pain prior to SQL. The good news is that we are seeing this already in a couple of places, think OpenAI’s API as the defacto standard, as well as Anthropic’s MCP. Prompt routers will be also be significant part of the solution. Analogous to HTTP router + HTML standard, a combination of prompt routing and standardisation may be the path to absolving these frustrations.
Frustration 3: Semantic Drift in Model Versions
GPT-4.1’s release highlights confusion. There was a lot of hype around GPT-5 coming out, and after the disappointing results from GPT-4.5, OpenAI released 4.1. Why GPT-4.1? The move back toward 4.1 feels like a semantic step backward (GPT-4.1 vs. GPT-4o vs. GPT-4 Turbo—what’s going on here?).
While the claims and early results show improvement, and the focus between 4.5 and 4.1 differ, it still leaves room for confusion. If you’ve been building repeatable prompting flows, you will at the very least feel mildly overwhelmed by the “model maze”——is higher better? faster? newer?
That said, this ambiguity hasn’t gone unnoticed. OpenAI has acknowledged these naming confusions, and we should expect future iterations to bring more clarity to the semantics and categorisation framework.

Frustration 4: Prompting and Hand-Waving

OpenAI publishing recommended workflow is a sign that prompting is becoming systematic, not just vibes. Yet, there’s frustration among the community where these practices still feel more like guesswork than true, quantifiable methods.
Developers report that small prompt changes lead to big performance differences, revealing the lack of standard prompting guidelines. Also, developers need to prompt different model in different ways—which is tricky to manage. Prompting today thus resembles alchemy before the scientific method—part intuition, part ritual, often surprisingly effective, but lacking universal principles.
That said, tools like DSPy already offer a path toward a framework turning prompt design into a repeatable, testable, and improvable process. If you are a developer reading this, one last piece of advice would be to adopt the mindset of an “Explorer”. We’re in the prototyping phase of a new engineering discipline, and we need to shift our mental models accordingly.
Future Implications
The optimal model choice often depends more on practical constraints (budget, speed, use case) than raw coding performance. Cost-to-performance ratio will become the primary lens for model selection—replacing the “latest and greatest” mindset. Indeed, LLM ecosystem is entering the “infrastructure layer wars,” where optimisation and integration trump novelty.
For instance, Google’s TPUs with Gemini 2.5 is not only leading on Aider’s coding benchmarks, but it is cheaper and faster to serve (scored 73% on Aider Polyglot for ~$6, vs. GPT-4.1’s ~$10). Even if GPT swing back with GPT-5, the hardware war with latency and costs, may ultimately decide which vendor developers and businesses favour. Read between the lines, and this is great news for developers and organisations. We’re benefiting from a race to the bottom on cost and a rise in serving efficiency!
At the same time, developers are voicing a roaming trend: devs don’t enjoy hand-picking models—they want abstraction layers to handle this automatically. This shift prioritises developer experience, where developers expect multi-model environments to take on this work—think of a Cursor who automatically hand picks the best fitting model for the task you require.
This evolution isn’t just about benchmark performance—it’s about empowering developers to fine-tune their infra: using leaner, cheaper models for routine jobs and automatically switching to more powerful ones when the stakes are higher. The future of AI native development doesn’t lie in manually picking models—it lies in building abstraction layers that make those choices invisible, so developers can focus on building, not juggling APIs.
All in all, it’s a shift from toolsmith to architect, one that perfectly mirrors the implementation to intent pattern from Patrick’s 4 Patterns of AI Native Development. If you haven’t explored it yet, it’s a must-read—it offers a compelling blueprint for where we’re headed.
If you enjoyed this piece, make sure to subscribe to our newsletter to keep up to date with the latest insights in the AI native development space.


