![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)
















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)








































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)








































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


































































































![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)





























































































































พื้นฐาน Clustering ใน Machine Learning
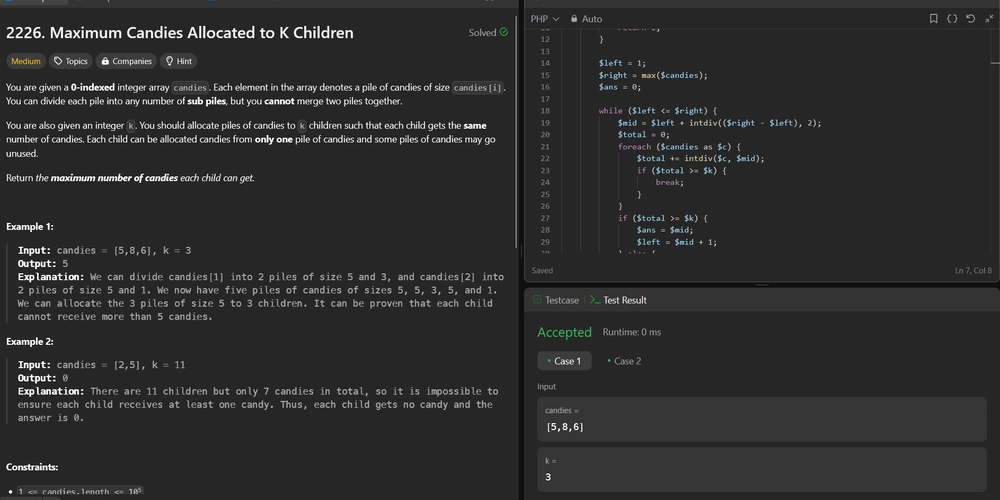
Clustering Model Clustering Model คือ Machine Learning Model ประเภท Unsupervised ที่ไม่มี Target หรือ ไม่มีต้นแบบของผลลัพธ์ ซึ่งเป็น Model ที่นำไปใช้ในการจัดกลุ่มของข้อมูลที่ไม่เคยมีการจัดกลุ่มมาก่อน โดยจะแบ่งกลุ่มข้อมูลจากความคล้าย เช่น การจัดกลุ่มลูกค้าจากพฤติกรรมการซื้อสินค้าของลูกค้าที่มีลักษณะคล้ายกันจะเป็นกลุ่มลูกค้าประเภทเดียวกัน Algorithms ที่ใช้ในการทำ Clustering Model ได้แก่ K-Mean และ DBSCAN ทำความรู้จัก K-Mean กันก่อน K-means คือ วิธีการหนึ่งใน Data mining อยู่ในกลุ่มของ Unsupervised Learning หรือแปลตรงๆคือการเรียนรู้แบบไม่ต้องสอน (Supervised Learning ต้องสอนก่อนต้องจับ Train และต้อง Test เป็นต้น) โดยหน้าที่หลักของ K-Mean คือการแบ่งกลุ่ม แบบ Clustering ซึ่งการแบ่งกลุ่มในลักษณะนี้จะใช้พื้นฐานทางสถิติ ซึ่งแน่นอนว่าต้องมีตัวเลขประกอบ อย่างน้อย 2 ตัวแปรขึ้นไป บทความนี้ เราจะมาดู K-Mean ใน Python กัน เราจะใช้ Google Colab ในการรันโค้ด โดย ตัวอย่างคือ การใช้ K-Mean แบ่งกลุ่มลูกค้าจากรายได้และพฤติกรรมการใช้จ่าย ขั้นตอนที่ 1: โหลดข้อมูลจาก CSV ใช้ pandas โหลดข้อมูลจากลิงก์ .csv ของลูกค้าในห้าง ใช้ .head() เพื่อดู 5 แถวแรกของข้อมูล ผลที่ได้จาก code ขั้นตอนที่ 2: เลือกข้อมูลที่ใช้วิเคราะห์ เราเลือกใช้แค่ 2 คอลัมน์: รายได้ต่อปี (Annual Income)กับคะแนนการใช้จ่าย (Spending Score) ผลที่ได้จาก code ขั้นตอนที่ 3: แสดงข้อมูลแบบ Scatter Plot แสดงกราฟกระจายของลูกค้าตาม 2 แกน เพื่อดูว่ากลุ่มลูกค้ามีลักษณะแยกกันอย่างไร ผลที่ได้จาก code ขั้นตอนที่ 4: ใช้ Elbow Method เพื่อหา K ที่เหมาะสม ทดสอบแบ่งกลุ่มตั้งแต่ 2 ถึง 9 กลุ่ม คำนวณ inertia (ระยะห่างรวมภายในกลุ่ม) พล็อตกราฟเพื่อดูว่า K ไหนเหมาะที่สุด (ดูจากจุดหักศอกของกราฟ) ผลที่ได้จาก code ขั้นตอนที่ 5: สร้างโมเดล K-Means ที่ K=5 ใช้ KMeans เพื่อแบ่งกลุ่มลูกค้าเป็น 5 กลุ่ม (ตามที่ได้จาก Elbow Method) ผลที่ได้จาก code ขั้นตอนที่ 6: หาศูนย์กลางของแต่ละคลัสเตอร์ ดูพิกัดของ ศูนย์กลางของแต่ละกลุ่ม (cluster centers) ช่วยให้เราเข้าใจว่ากลุ่มไหนมีรายได้/พฤติกรรมแบบไหน ผลที่ได้จาก code ขั้นตอนที่ 7: รวมข้อมูลลูกค้ากับ centroid และเพิ่ม label นำข้อมูลลูกค้า + centroid มารวมกันในตารางเดียว ใส่ label ของ cluster (0–4) สำหรับลูกค้า ใส่ label พิเศษ "20" ให้จุด centroid เพื่อใช้แสดงแยกจากลูกค้า ผลที่ได้จาก code ขั้นตอนที่ 8: แสดงกราฟกลุ่มลูกค้าแบบแยกสี ใช้ pairplot เพื่อแสดงกลุ่มลูกค้าในกราฟแบบแยกสีตาม cluster ผลที่ได้จาก code ขั้นตอนที่ 9: ดูค่า Inertia สุดท้าย ดูว่าโมเดลที่สร้างไว้มีความแม่นยำแค่ไหน (ยิ่งค่าน้อยยิ่งดี) ใช้ประกอบการประเมินคุณภาพการแบ่งกลุ่ม ผลที่ได้จาก code จากตัวอย่างจะได้ว่า K-Means เป็นวิธีที่แบ่งกลุ่มข้อมูลโดยอิงจากระยะห่างจากจุดศูนย์กลางของแต่ละกลุ่ม (Centroid) ซึ่งผู้ใช้งานต้องกำหนดจำนวนกลุ่ม (K) ล่วงหน้า จากนั้นจึงใช้การคำนวณซ้ำๆ เพื่อหาตำแหน่งของจุดศูนย์กลางใหม่จนกว่าระบบจะนิ่ง ข้อดีของ K-Means คือใช้งานง่าย เหมาะสำหรับผู้เริ่มต้น แต่ข้อจำกัดคือไม่สามารถรับมือกับข้อมูลนอกกลุ่ม (Outlier) ได้ดี และเหมาะกับกลุ่มที่มีรูปร่างคล้ายวงกลม ตัวอย่างเพิ่มเติม เราจะลองใช้ตัวอย่างข้อมูลอื่นบ้าง เช่น ข้อมูลของDBSCAN (Density-Based Spatial Clustering of Applications with Noise) ทำความรู้จัก DBSCAN กันก่อน DBSCAN (Density-based spatial clustering of applications with noise) เป็นการหาบริเวณที่ข้อมูลเกาะกลุ่มกัน ซึ่งสามารถคำนวณได้จาก data point ที่อยู่รอบๆ ในรัศมีที่กำหนด เราจะมาดู DBSCAN ใน Python กัน เราจะใช้ Google Colab ในการรันโค้ด โดย ตัวอย่างคือ การแบ่งกลุ่มลูกค้า โดยใช้เทคนิค DBSCAN ขั้นตอนที่ 1: โหลดข้อมูล โหลดข้อมูลจาก URL ที่กำหนดไว้ ซึ่งเป็นข้อมูลเกี่ยวกับลูกค้าในห้างสรรพสินค้า (Mall Customers) ผลที่ได้จาก code ขั้นตอนที่ 2: เลือกคอลัมน์ที่ต้องการ เลือกคอลัมน์ Annual Income (k$) และ Spending Score (1-100) เพราะเป็นข้อมูลที่เราต้องการใช้ในการจัดกลุ่มลูกค้า ผลที่ได้จาก code ขั้นตอนที่ 3: การปรับขนาดข้อมูล (Standardization) ปรับขนาดข้อมูลเพื่อให้ค่าของทั้งสองตัวแปร (Annual Income และ Spending Score) อยู่ในสเกลเดียวกัน (มีค่าเฉลี่ย 0 และเบี่ยงเบนมาตรฐาน 1) ซึ่งจะช่วยให้การทำ clustering มีความแม่นยำมากขึ้น ผลที่ได้จาก code ขั้นตอนที่ 4: การใช้ DBSCAN ในการจัดกลุ่ม ใช้ DBSCAN เพื่อจัดกลุ่มข้อมูลโดยใช้ค่า eps (ขนาดของรัศมีที่ใช้ในการเชื่อมโยงจุดข้อมูล) และ min_samples (จำนวนจุดที่ต้องมีในกลุ่มเพื่อให้จุดนั้นสามารถสร้างกลุ่มได้) eps=0.3: กำหนดระยะห่างสูงสุดระหว่างจุดสองจุดที่สามารถรวมเป็นกลุ่มเดียวกัน min_samples=10: กำหนดจำนวนจุดขั้นต่ำในกลุ่มที่จะถือว่าเป็นกลุ่มได้ ใส่ผลลัพธ์การจัดกลุ่ม (labels) เข้าไปในคอลัมน์ cluster ของ DataFrame ผลที่ได้จาก code ขั้นตอนที่ 5: การแสดงผลลัพธ์ด้วยกราฟ ใช้ Seaborn และ Matplotlib ในการสร้างกราฟ Scatter plot เพื่อแสดงข้อมูลที่ถูกจัดกลุ่มโดย DBSCAN เราจะเห็นข้อมูลในแต่ละกลุ่ม (Cluster 0, Cluster 1, Cluster -1) ถูกแสดงในสีและสัญลักษณ์ที่ต่างกัน ผลที่ได้จาก code จากตัวอย่างจะได้ว่า DBSCAN เป็นเทคนิคที่ไม่ต้องกำหนดจำนวนกลุ่มล่วงหน้า โดยจะใช้แนวคิด “ความหนาแน่น” ของข้อมูลเพื่อจัดกลุ่ม หากบริเวณใดมีข้อมูลกระจุกตัวกันมากพอ ก็จะถือว่าเป็นกลุ่ม ส่วนข้อมูลที่อยู่นอกกลุ่มจะถูกระบุเป็น “Noise” หรือจุดรบกวน DBSCAN มีความยืดหยุ่นกว่า K-Means เพราะสามารถจัดการกับข้อมูลที่มีรูปร่างซับซ้อนและมี Outlier ได้ดี แต่ต้องเลือกค่าพารามิเตอร์ เช่น eps และ min_samples อย่างระมัดระวัง สรุปผล สำหรับบทความนี้ เราได้แสดงตัวอย่างการทำ Clustering จากข้

Clustering Model
Clustering Model คือ Machine Learning Model ประเภท Unsupervised ที่ไม่มี Target หรือ ไม่มีต้นแบบของผลลัพธ์ ซึ่งเป็น Model ที่นำไปใช้ในการจัดกลุ่มของข้อมูลที่ไม่เคยมีการจัดกลุ่มมาก่อน โดยจะแบ่งกลุ่มข้อมูลจากความคล้าย เช่น การจัดกลุ่มลูกค้าจากพฤติกรรมการซื้อสินค้าของลูกค้าที่มีลักษณะคล้ายกันจะเป็นกลุ่มลูกค้าประเภทเดียวกัน
Algorithms ที่ใช้ในการทำ Clustering Model ได้แก่ K-Mean และ DBSCAN
ทำความรู้จัก K-Mean กันก่อน
K-means คือ วิธีการหนึ่งใน Data mining อยู่ในกลุ่มของ Unsupervised Learning หรือแปลตรงๆคือการเรียนรู้แบบไม่ต้องสอน (Supervised Learning ต้องสอนก่อนต้องจับ Train และต้อง Test เป็นต้น) โดยหน้าที่หลักของ K-Mean คือการแบ่งกลุ่ม แบบ Clustering ซึ่งการแบ่งกลุ่มในลักษณะนี้จะใช้พื้นฐานทางสถิติ ซึ่งแน่นอนว่าต้องมีตัวเลขประกอบ อย่างน้อย 2 ตัวแปรขึ้นไป
บทความนี้ เราจะมาดู K-Mean ใน Python กัน เราจะใช้ Google Colab ในการรันโค้ด
โดย ตัวอย่างคือ การใช้ K-Mean แบ่งกลุ่มลูกค้าจากรายได้และพฤติกรรมการใช้จ่าย
ขั้นตอนที่ 1: โหลดข้อมูลจาก CSV
- ใช้ pandas โหลดข้อมูลจากลิงก์ .csv ของลูกค้าในห้าง
- ใช้ .head() เพื่อดู 5 แถวแรกของข้อมูล
ผลที่ได้จาก code
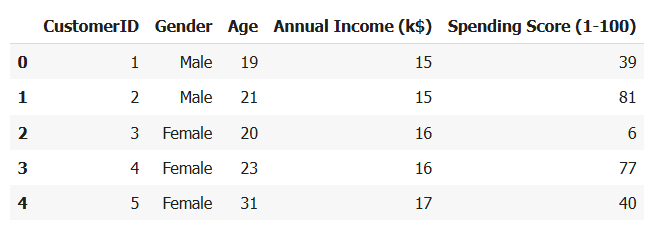
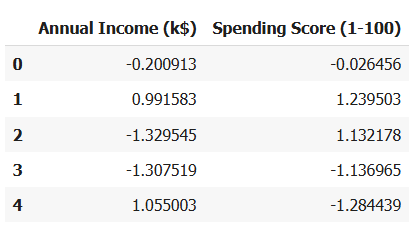
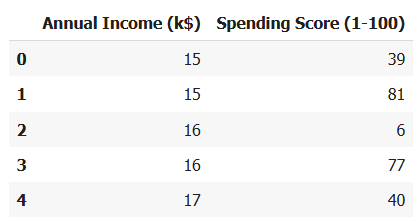
ขั้นตอนที่ 2: เลือกข้อมูลที่ใช้วิเคราะห์

- เราเลือกใช้แค่ 2 คอลัมน์: รายได้ต่อปี (Annual Income)กับคะแนนการใช้จ่าย (Spending Score)
ผลที่ได้จาก code
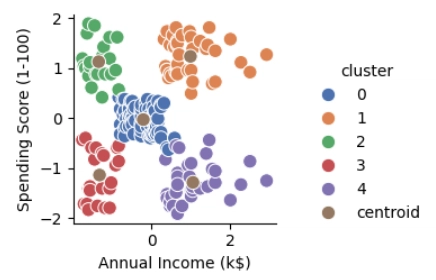
ขั้นตอนที่ 3: แสดงข้อมูลแบบ Scatter Plot

- แสดงกราฟกระจายของลูกค้าตาม 2 แกน เพื่อดูว่ากลุ่มลูกค้ามีลักษณะแยกกันอย่างไร
ผลที่ได้จาก code
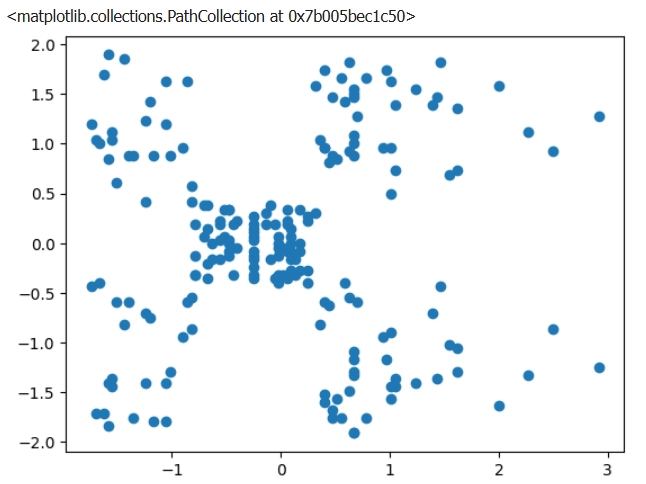
ขั้นตอนที่ 4: ใช้ Elbow Method เพื่อหา K ที่เหมาะสม

- ทดสอบแบ่งกลุ่มตั้งแต่ 2 ถึง 9 กลุ่ม
- คำนวณ inertia (ระยะห่างรวมภายในกลุ่ม)
- พล็อตกราฟเพื่อดูว่า K ไหนเหมาะที่สุด (ดูจากจุดหักศอกของกราฟ)
ผลที่ได้จาก code
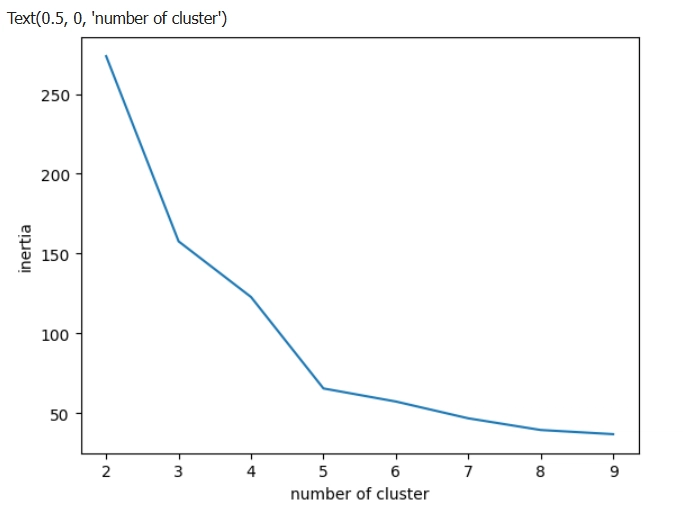
ขั้นตอนที่ 5: สร้างโมเดล K-Means ที่ K=5

- ใช้ KMeans เพื่อแบ่งกลุ่มลูกค้าเป็น 5 กลุ่ม (ตามที่ได้จาก Elbow Method)
ผลที่ได้จาก code

ขั้นตอนที่ 6: หาศูนย์กลางของแต่ละคลัสเตอร์

- ดูพิกัดของ ศูนย์กลางของแต่ละกลุ่ม (cluster centers)
- ช่วยให้เราเข้าใจว่ากลุ่มไหนมีรายได้/พฤติกรรมแบบไหน
ผลที่ได้จาก code
ขั้นตอนที่ 7: รวมข้อมูลลูกค้ากับ centroid และเพิ่ม label

- นำข้อมูลลูกค้า + centroid มารวมกันในตารางเดียว
- ใส่ label ของ cluster (0–4) สำหรับลูกค้า
- ใส่ label พิเศษ "20" ให้จุด centroid เพื่อใช้แสดงแยกจากลูกค้า
ผลที่ได้จาก code
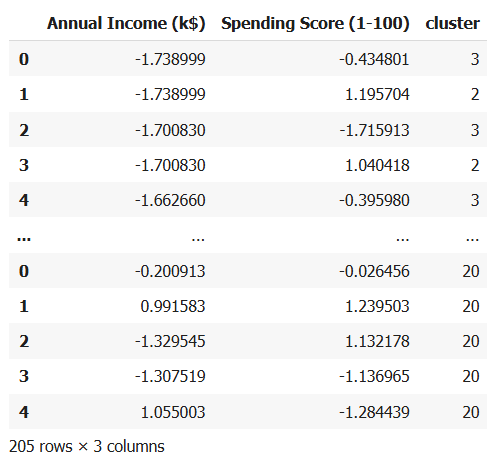
ขั้นตอนที่ 8: แสดงกราฟกลุ่มลูกค้าแบบแยกสี

- ใช้ pairplot เพื่อแสดงกลุ่มลูกค้าในกราฟแบบแยกสีตาม cluster
ผลที่ได้จาก code
ขั้นตอนที่ 9: ดูค่า Inertia สุดท้าย
![]()
- ดูว่าโมเดลที่สร้างไว้มีความแม่นยำแค่ไหน (ยิ่งค่าน้อยยิ่งดี)
- ใช้ประกอบการประเมินคุณภาพการแบ่งกลุ่ม
ผลที่ได้จาก code
![]()
จากตัวอย่างจะได้ว่า K-Means เป็นวิธีที่แบ่งกลุ่มข้อมูลโดยอิงจากระยะห่างจากจุดศูนย์กลางของแต่ละกลุ่ม (Centroid) ซึ่งผู้ใช้งานต้องกำหนดจำนวนกลุ่ม (K) ล่วงหน้า จากนั้นจึงใช้การคำนวณซ้ำๆ เพื่อหาตำแหน่งของจุดศูนย์กลางใหม่จนกว่าระบบจะนิ่ง
ข้อดีของ K-Means คือใช้งานง่าย เหมาะสำหรับผู้เริ่มต้น แต่ข้อจำกัดคือไม่สามารถรับมือกับข้อมูลนอกกลุ่ม (Outlier) ได้ดี และเหมาะกับกลุ่มที่มีรูปร่างคล้ายวงกลม
ตัวอย่างเพิ่มเติม
เราจะลองใช้ตัวอย่างข้อมูลอื่นบ้าง เช่น ข้อมูลของDBSCAN (Density-Based Spatial Clustering of Applications with Noise)
ทำความรู้จัก DBSCAN กันก่อน
DBSCAN (Density-based spatial clustering of applications with noise) เป็นการหาบริเวณที่ข้อมูลเกาะกลุ่มกัน ซึ่งสามารถคำนวณได้จาก data point ที่อยู่รอบๆ ในรัศมีที่กำหนด
เราจะมาดู DBSCAN ใน Python กัน เราจะใช้ Google Colab ในการรันโค้ด
โดย ตัวอย่างคือ การแบ่งกลุ่มลูกค้า โดยใช้เทคนิค DBSCAN
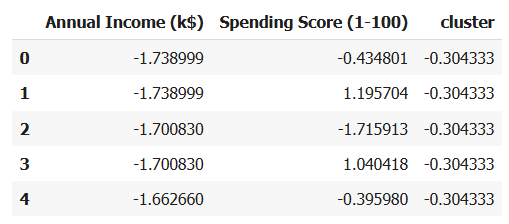
ขั้นตอนที่ 1: โหลดข้อมูล

- โหลดข้อมูลจาก URL ที่กำหนดไว้ ซึ่งเป็นข้อมูลเกี่ยวกับลูกค้าในห้างสรรพสินค้า (Mall Customers)
ผลที่ได้จาก code
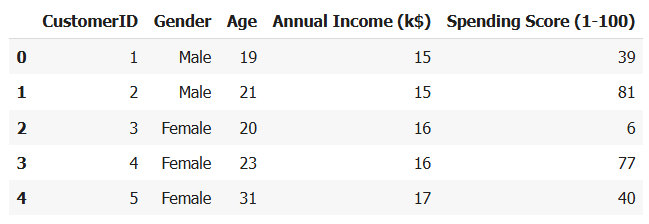
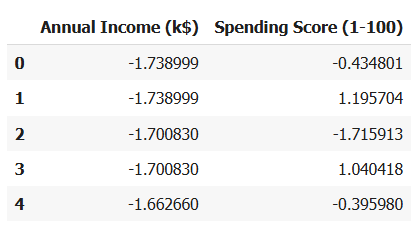
ขั้นตอนที่ 2: เลือกคอลัมน์ที่ต้องการ
![]()
- เลือกคอลัมน์ Annual Income (k$) และ Spending Score (1-100) เพราะเป็นข้อมูลที่เราต้องการใช้ในการจัดกลุ่มลูกค้า
ผลที่ได้จาก code
ขั้นตอนที่ 3: การปรับขนาดข้อมูล (Standardization)

- ปรับขนาดข้อมูลเพื่อให้ค่าของทั้งสองตัวแปร (Annual Income และ Spending Score) อยู่ในสเกลเดียวกัน (มีค่าเฉลี่ย 0 และเบี่ยงเบนมาตรฐาน 1) ซึ่งจะช่วยให้การทำ clustering มีความแม่นยำมากขึ้น
ผลที่ได้จาก code
ขั้นตอนที่ 4: การใช้ DBSCAN ในการจัดกลุ่ม

- ใช้ DBSCAN เพื่อจัดกลุ่มข้อมูลโดยใช้ค่า eps (ขนาดของรัศมีที่ใช้ในการเชื่อมโยงจุดข้อมูล) และ min_samples (จำนวนจุดที่ต้องมีในกลุ่มเพื่อให้จุดนั้นสามารถสร้างกลุ่มได้)
- eps=0.3: กำหนดระยะห่างสูงสุดระหว่างจุดสองจุดที่สามารถรวมเป็นกลุ่มเดียวกัน
- min_samples=10: กำหนดจำนวนจุดขั้นต่ำในกลุ่มที่จะถือว่าเป็นกลุ่มได้
- ใส่ผลลัพธ์การจัดกลุ่ม (labels) เข้าไปในคอลัมน์ cluster ของ DataFrame
ผลที่ได้จาก code

ขั้นตอนที่ 5: การแสดงผลลัพธ์ด้วยกราฟ

- ใช้ Seaborn และ Matplotlib ในการสร้างกราฟ Scatter plot เพื่อแสดงข้อมูลที่ถูกจัดกลุ่มโดย DBSCAN
- เราจะเห็นข้อมูลในแต่ละกลุ่ม (Cluster 0, Cluster 1, Cluster -1) ถูกแสดงในสีและสัญลักษณ์ที่ต่างกัน
ผลที่ได้จาก code
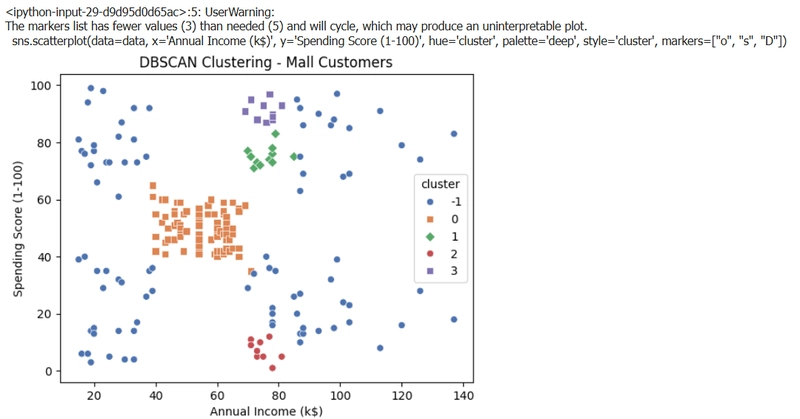
จากตัวอย่างจะได้ว่า DBSCAN เป็นเทคนิคที่ไม่ต้องกำหนดจำนวนกลุ่มล่วงหน้า โดยจะใช้แนวคิด “ความหนาแน่น” ของข้อมูลเพื่อจัดกลุ่ม หากบริเวณใดมีข้อมูลกระจุกตัวกันมากพอ ก็จะถือว่าเป็นกลุ่ม ส่วนข้อมูลที่อยู่นอกกลุ่มจะถูกระบุเป็น “Noise” หรือจุดรบกวน
DBSCAN มีความยืดหยุ่นกว่า K-Means เพราะสามารถจัดการกับข้อมูลที่มีรูปร่างซับซ้อนและมี Outlier ได้ดี แต่ต้องเลือกค่าพารามิเตอร์ เช่น eps และ min_samples อย่างระมัดระวัง
สรุปผล
สำหรับบทความนี้ เราได้แสดงตัวอย่างการทำ Clustering จากข้อมูล 2 ชุด ได้แก่ข้อมูลของ K-Mean และ DBSCAN เราสามารถลองเปลี่ยนตัวแปรเพื่อสร้างสมการ Linear Regression แบบอื่นๆ อีกได้ด้วยตัวเอง
อ้างอิง
1.Clustering — DBSCAN คืออะไร
2.การทำ Machine Learning ด้วย Clustering Model
3.BLOG for chakrit
4.colab
5.chatgpt