![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)






























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)








































































































.png?#)




.jpg?#)
































_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)


































































































![Rapidus in Talks With Apple as It Accelerates Toward 2nm Chip Production [Report]](https://www.iclarified.com/images/news/96937/96937/96937-640.jpg)





























































































































Workflow Scheduling Must-Know! The Four Core Trends You Can't Ignore in 2025
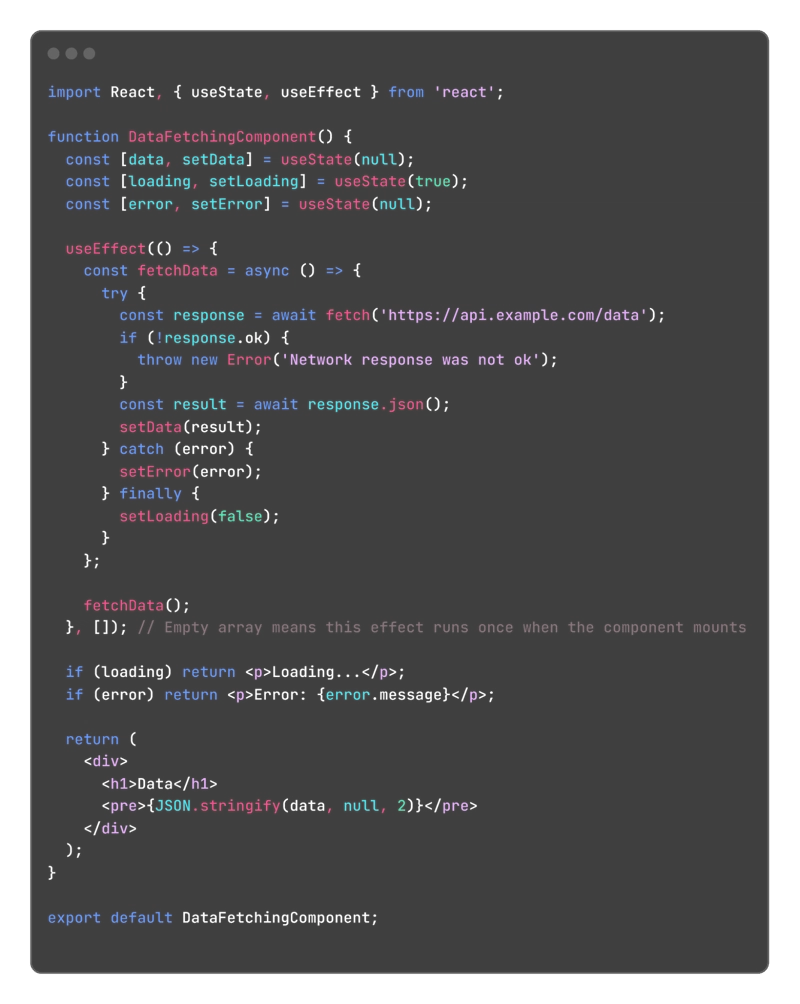
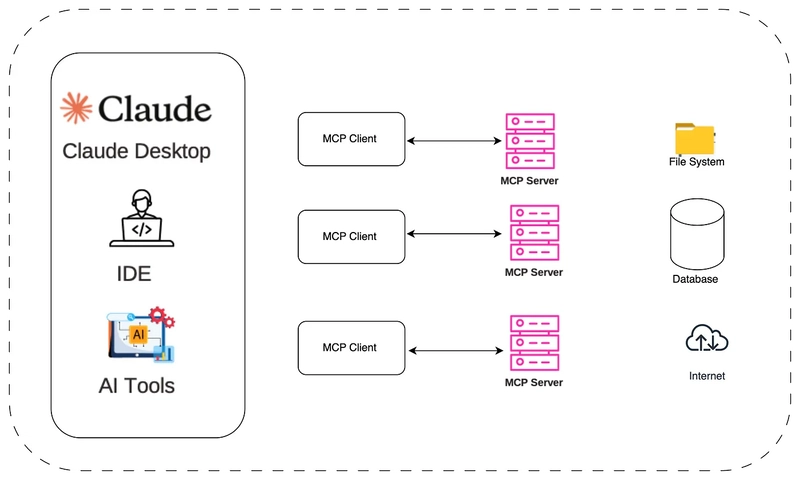
In the digital era, data is like the blood flowing through the veins of an enterprise, continuously supplying nutrients for business decision-making. A big data workflow scheduling system acts as a precise conductor, coordinating various stages of the data processing flow to ensure the efficient movement of data and the realization of its value. So, what exactly is a big data workflow scheduling system? Where does it stand in the current technological landscape? And what future trends will it follow? Let’s explore. Big Data Workflow Scheduling System: Concept and Architecture A big data workflow scheduling system is a core tool for managing and coordinating data processing workflows. Its primary goal is to ensure the efficient execution of complex data processing tasks through task orchestration, dependency management, and resource optimization. Simply put, it is a system that automates the management and execution of big data processing task sequences. It decomposes complex data processing workflows into multiple manageable tasks and schedules them precisely according to predefined rules and dependencies. A typical system uses a Directed Acyclic Graph (DAG) as its core model, linking tasks in a logical order while supporting visual configuration, real-time monitoring, and dynamic adjustments. For example, Apache DolphinScheduler provides an intuitive DAG visualization interface (as shown in Figure 1), enabling users to clearly see task linkages, supporting complex ETL (Extract, Transform, Load) processes, and allowing users to quickly build high-performance workflows with a low-code approach. Take a typical e-commerce data processing workflow as an example. The workflow might include tasks such as extracting user behavior data from a database, cleaning and transforming the data, loading the processed data into a data warehouse, and generating various business reports based on the data warehouse. The big data workflow scheduling system ensures that these tasks are executed in the correct sequence. For instance, the data extraction must be completed before starting the data cleaning task, and only after successful completion of the cleaning and transformation tasks can the data be loaded. From an architectural perspective, big data workflow scheduling systems typically consist of the following core components, as illustrated in Figure 1: Workflow Definition Module: Allows users to define the workflow structure through a visual interface or code, including task nodes, dependencies, and execution conditions. For example, users can drag and drop various data processing tasks as nodes onto a canvas and connect them with lines to indicate their sequence and dependencies. Scheduling Engine: The core component of the system, responsible for parsing workflow definitions and scheduling tasks based on time-based strategies (e.g., periodic or scheduled execution) and dependency-based strategies (e.g., determining the execution of subsequent tasks based on the success of prior tasks). Execution Environment: The actual environment where tasks are executed. It can be a distributed computing cluster (e.g., Hadoop, Spark) or a containerized environment (e.g., Docker). The execution environment receives tasks from the scheduling engine and calls the necessary computing resources to process them. Monitoring and Management Module: Provides real-time monitoring of workflow and task execution statuses, including whether tasks are running, completed successfully, or failed. If anomalies occur, the system promptly alerts administrators and provides execution logs for troubleshooting and performance optimization. Figure 1: Workflow Scheduling System Key Modules (Example: Apache DolphinScheduler Architecture) Technological Evolution and Current Applications From a technological perspective, workflow scheduling has evolved through several stages: Script-based Scheduling → XML Configuration Systems → Visual Low-Code Platforms → AI-Driven Intelligent Scheduling. Figure 2: Workflow Scheduling Technology Evolution Chart Currently, workflow scheduling technologies are widely used across industries and have become an essential part of enterprise digital transformation. Whether it is risk assessment in finance, supply chain data analysis in manufacturing, or user behavior analysis in internet services, workflow scheduling plays a critical role. There are numerous open-source and commercial workflow scheduling tools, such as Apache DolphinScheduler, Azkaban, Oozie, XXL-job, and others. Each tool has its strengths and is suited to different scenarios. Among them, Apache DolphinScheduler stands out in workflow scheduling with its unique advantages. It is a distributed workflow task scheduling system designed to address the complex dependencies in ETL tasks. Thanks to its visualization and ease of use, rich task support (Shell, MapReduce, Spark, SQL, Python, sub-processes, stored procedures, etc.),

In the digital era, data is like the blood flowing through the veins of an enterprise, continuously supplying nutrients for business decision-making. A big data workflow scheduling system acts as a precise conductor, coordinating various stages of the data processing flow to ensure the efficient movement of data and the realization of its value.
So, what exactly is a big data workflow scheduling system? Where does it stand in the current technological landscape? And what future trends will it follow? Let’s explore.
Big Data Workflow Scheduling System: Concept and Architecture
A big data workflow scheduling system is a core tool for managing and coordinating data processing workflows. Its primary goal is to ensure the efficient execution of complex data processing tasks through task orchestration, dependency management, and resource optimization. Simply put, it is a system that automates the management and execution of big data processing task sequences. It decomposes complex data processing workflows into multiple manageable tasks and schedules them precisely according to predefined rules and dependencies.
A typical system uses a Directed Acyclic Graph (DAG) as its core model, linking tasks in a logical order while supporting visual configuration, real-time monitoring, and dynamic adjustments. For example, Apache DolphinScheduler provides an intuitive DAG visualization interface (as shown in Figure 1), enabling users to clearly see task linkages, supporting complex ETL (Extract, Transform, Load) processes, and allowing users to quickly build high-performance workflows with a low-code approach.
Take a typical e-commerce data processing workflow as an example. The workflow might include tasks such as extracting user behavior data from a database, cleaning and transforming the data, loading the processed data into a data warehouse, and generating various business reports based on the data warehouse. The big data workflow scheduling system ensures that these tasks are executed in the correct sequence. For instance, the data extraction must be completed before starting the data cleaning task, and only after successful completion of the cleaning and transformation tasks can the data be loaded.
From an architectural perspective, big data workflow scheduling systems typically consist of the following core components, as illustrated in Figure 1:
- Workflow Definition Module: Allows users to define the workflow structure through a visual interface or code, including task nodes, dependencies, and execution conditions. For example, users can drag and drop various data processing tasks as nodes onto a canvas and connect them with lines to indicate their sequence and dependencies.
- Scheduling Engine: The core component of the system, responsible for parsing workflow definitions and scheduling tasks based on time-based strategies (e.g., periodic or scheduled execution) and dependency-based strategies (e.g., determining the execution of subsequent tasks based on the success of prior tasks).
- Execution Environment: The actual environment where tasks are executed. It can be a distributed computing cluster (e.g., Hadoop, Spark) or a containerized environment (e.g., Docker). The execution environment receives tasks from the scheduling engine and calls the necessary computing resources to process them.
- Monitoring and Management Module: Provides real-time monitoring of workflow and task execution statuses, including whether tasks are running, completed successfully, or failed. If anomalies occur, the system promptly alerts administrators and provides execution logs for troubleshooting and performance optimization.
Figure 1: Workflow Scheduling System Key Modules (Example: Apache DolphinScheduler Architecture)
Technological Evolution and Current Applications
From a technological perspective, workflow scheduling has evolved through several stages:
Script-based Scheduling → XML Configuration Systems → Visual Low-Code Platforms → AI-Driven Intelligent Scheduling.

Figure 2: Workflow Scheduling Technology Evolution Chart
Currently, workflow scheduling technologies are widely used across industries and have become an essential part of enterprise digital transformation. Whether it is risk assessment in finance, supply chain data analysis in manufacturing, or user behavior analysis in internet services, workflow scheduling plays a critical role.
There are numerous open-source and commercial workflow scheduling tools, such as Apache DolphinScheduler, Azkaban, Oozie, XXL-job, and others. Each tool has its strengths and is suited to different scenarios.

Among them, Apache DolphinScheduler stands out in workflow scheduling with its unique advantages. It is a distributed workflow task scheduling system designed to address the complex dependencies in ETL tasks. Thanks to its visualization and ease of use, rich task support (Shell, MapReduce, Spark, SQL, Python, sub-processes, stored procedures, etc.), powerful scheduling functions, high availability (HA clusters), and multi-tenant support (resource isolation and permission management), DolphinScheduler has quickly gained popularity among users.
However, with the explosive growth of data, increasing complexity of processing scenarios, and rising demand for real-time capabilities, existing workflow scheduling technologies face several challenges:
- How to improve scheduling efficiency and reliability when handling large-scale distributed tasks to prevent task backlog and resource wastage?
- How to better support heterogeneous computing environments, ensuring collaboration between different computing resources (CPU, GPU, FPGA)?
- How to achieve more intelligent task scheduling, dynamically adjusting scheduling strategies based on real-time system load and task priorities?
To address these needs, future workflow scheduling technology must keep pace with cutting-edge trends and explore new technological directions.
Future Trends and Predictions for Workflow Scheduling
Based on the current state of workflow scheduling technology and the development of related advanced technologies, we predict that workflow scheduling will revolve around four core directions: