












































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)












































































































































































































































































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)














































































































![M4 MacBook Air Drops to New All-Time Low of $912 [Deal]](https://www.iclarified.com/images/news/97108/97108/97108-640.jpg)
![New iPhone 17 Dummy Models Surface in Black and White [Images]](https://www.iclarified.com/images/news/97106/97106/97106-640.jpg)


























































































































Why You Shouldn’t Invest In Vector Databases?
Technologies behind vector databases In traditional relational databases, data is typically organized in tables. However, the emergence of the AI era has brought about a vast amount of unstructured data, including images, audio, and text. Storing such data in a tabular format is not suitable, necessitating the conversion of this data into “features” represented by vectors using machine learning algorithms. Vector databases have arisen to tackle the storage and processing of these vectors. The foundation of vector databases lies in data indexing. Through techniques like inverted indexing, vector databases can efficiently conduct similarity searches by grouping and indexing vector features. Furthermore, vector quantization techniques aid in mapping high-dimensional vectors to lower-dimensional spaces, resulting in reduced storage and computational requirements. By leveraging indexing techniques, vector databases enable efficient searching of vectors using various operations such as vector addition, similarity calculation, and clustering analysis. Regarding the storage aspect of vector databases, it is noteworthy that indexing techniques take precedence over the choice of underlying storage. In fact, many databases have the capability to incorporate indexing modules directly, enabling efficient vector search. Existing OLAP databases that are designed for real-time analytics and utilizing columnar storage, such as ClickHouse, Apache Pinot, and Apache Druid, already demonstrate impressive data compression rates. When it comes to vector data, which typically comprises a significant number of dimensions, the adoption of columnar storage for continuous storage of data pertaining to the same dimensions greatly enhances storage efficiency and query performance.Furthermore, columnar databases excel in optimizing operations at the column level, including vector similarity calculations and aggregation operations. Chroma is (or used to be) a vector database built atop the renowned real-time OLAP database, ClickHouse. Being criticized for being “just a lightweight wrapper on top of ClickHouse,” the one-year-old startup has landed $18 million seed round funding from its vectors. Chroma’s rise demonstrates that incorporating vector search functionality into existing databases is a relatively straightforward endeavor. Note that Chroma’s founder, Jeff Huber, replied on Twitter that Chroma will soon remove ClickHouse dependence and become a full cloud-native database! Vector databases and large-scale generative AI models Let’s explore the reasons behind the recent surge in the popularity of vector databases. While vector databases have been around for several years, with companies like Zilliz (founded in 2017), Pinecone (founded in 2019), Weaviate (founded in 2019), and others already establishing their presence, the rise of large-scale generative AI models has further propelled the demand for vector databases. Here’s why: Accommodating vast amounts of data: Large-scale generative AI models require extensive data for training to capture intricate semantic and contextual information. Consequently, the volume of data has exploded. Vector databases, as adept data managers, play a crucial role in efficiently handling and managing such massive amounts of data. Enabling accurate similarity searches and matching: Generated text from large-scale generative AI models often necessitates similarity searches and matching to provide precise replies, recommendations, or matching results. Traditional keyword-based search methods may fall short when it comes to complex semantics and context. Vector databases shine in this domain, offering high relevance and effectiveness for these tasks. Supporting multimodal data processing: Large-scale generative AI models extend beyond text data and can handle multimodal data like images and speech. As comprehensive systems capable of storing and processing diverse data types, vector databases effectively support the storage, indexing, and querying of multimodal data, enhancing their versatility. Considering these factors, the development of vector databases is intricately linked to the evolution of large-scale generative AI models. With the rapid advancements expected in the coming years, the demand for vector databases will undoubtedly continue to grow substantially. Market Demand and Landscape of Vector Databases Following our discussion on the technology and applications of vector databases, let’s shift our focus to the market aspect. The primary objective of any investment activity is to achieve favorable returns. To gauge these returns, it becomes essential to evaluate the current market demand and supply scenario and ascertain if the investment can generate attractive profits. Why do I discourage entering the vector database market at present? It’s because the market is already saturated with a plethora of vector database products, and potential users c
Technologies behind vector databases
In traditional relational databases, data is typically organized in tables. However, the emergence of the AI era has brought about a vast amount of unstructured data, including images, audio, and text. Storing such data in a tabular format is not suitable, necessitating the conversion of this data into “features” represented by vectors using machine learning algorithms. Vector databases have arisen to tackle the storage and processing of these vectors.
The foundation of vector databases lies in data indexing. Through techniques like inverted indexing, vector databases can efficiently conduct similarity searches by grouping and indexing vector features. Furthermore, vector quantization techniques aid in mapping high-dimensional vectors to lower-dimensional spaces, resulting in reduced storage and computational requirements. By leveraging indexing techniques, vector databases enable efficient searching of vectors using various operations such as vector addition, similarity calculation, and clustering analysis.
Regarding the storage aspect of vector databases, it is noteworthy that indexing techniques take precedence over the choice of underlying storage. In fact, many databases have the capability to incorporate indexing modules directly, enabling efficient vector search. Existing OLAP databases that are designed for real-time analytics and utilizing columnar storage, such as ClickHouse, Apache Pinot, and Apache Druid, already demonstrate impressive data compression rates. When it comes to vector data, which typically comprises a significant number of dimensions, the adoption of columnar storage for continuous storage of data pertaining to the same dimensions greatly enhances storage efficiency and query performance.Furthermore, columnar databases excel in optimizing operations at the column level, including vector similarity calculations and aggregation operations.
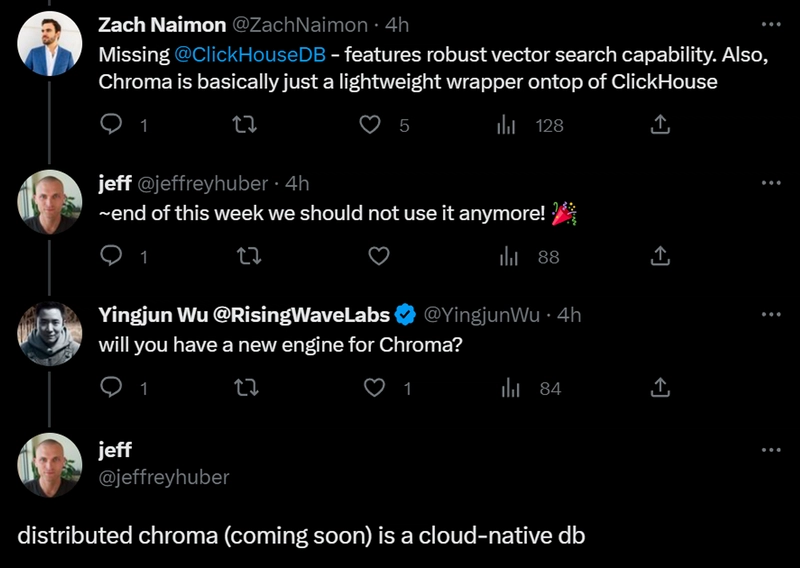
Chroma is (or used to be) a vector database built atop the renowned real-time OLAP database, ClickHouse. Being criticized for being “just a lightweight wrapper on top of ClickHouse,” the one-year-old startup has landed $18 million seed round funding from its vectors. Chroma’s rise demonstrates that incorporating vector search functionality into existing databases is a relatively straightforward endeavor.
Note that Chroma’s founder, Jeff Huber, replied on Twitter that Chroma will soon remove ClickHouse dependence and become a full cloud-native database!
Vector databases and large-scale generative AI models
Let’s explore the reasons behind the recent surge in the popularity of vector databases.
While vector databases have been around for several years, with companies like
Zilliz (founded in 2017), Pinecone (founded in 2019), Weaviate (founded in 2019), and others already establishing their presence, the rise of large-scale generative AI models has further propelled the demand for vector databases. Here’s why:
- Accommodating vast amounts of data: Large-scale generative AI models require extensive data for training to capture intricate semantic and contextual information. Consequently, the volume of data has exploded. Vector databases, as adept data managers, play a crucial role in efficiently handling and managing such massive amounts of data.
- Enabling accurate similarity searches and matching: Generated text from large-scale generative AI models often necessitates similarity searches and matching to provide precise replies, recommendations, or matching results. Traditional keyword-based search methods may fall short when it comes to complex semantics and context. Vector databases shine in this domain, offering high relevance and effectiveness for these tasks.
- Supporting multimodal data processing: Large-scale generative AI models extend beyond text data and can handle multimodal data like images and speech. As comprehensive systems capable of storing and processing diverse data types, vector databases effectively support the storage, indexing, and querying of multimodal data, enhancing their versatility.
Considering these factors, the development of vector databases is intricately linked to the evolution of large-scale generative AI models. With the rapid advancements expected in the coming years, the demand for vector databases will undoubtedly continue to grow substantially.
Market Demand and Landscape of Vector Databases
Following our discussion on the technology and applications of vector databases, let’s shift our focus to the market aspect. The primary objective of any investment activity is to achieve favorable returns. To gauge these returns, it becomes essential to evaluate the current market demand and supply scenario and ascertain if the investment can generate attractive profits. Why do I discourage entering the vector database market at present? It’s because the market is already saturated with a plethora of vector database products, and potential users can readily find suitable options within the existing market. This reality poses significant challenges for new entrants in identifying opportunities.

In cases where a company possesses a strong technological foundation and faces a substantial workload demanding advanced vector search capabilities, its ideal solution lies in adopting a specialized vector database. Prominent options in this domain include Chroma (having raised $20 million), Zilliz (having raised $113 million), Pinecone (having raised $138 million), Qdrant (having raised $9.8 million), Weaviate (having raised $67.7 million), LanceDB (YC W22), Vespa, Marqo, and others. Many of these players have secured significant funding in recent years and are well-positioned to capture notable market share. These vector databases offer efficient storage, indexing, and similarity search functionalities for vectors. They often incorporate specific optimizations tailored for vector data, such as similarity search based on inverted indexes and efficient vector computations. As a result, they cater to the requirements of companies operating in areas like recommendation systems, image search, and natural language processing.
On the other hand, if a company has already adopted commercial databases like Elastic, Redis, SingleStore, or Rockset and does not necessitate highly advanced vector search capabilities, they can fully utilize the existing functionality of these databases. These commercial databases excel in processing non-vector data and are suitable for various use cases and scenarios. While their performance in vector data processing may be satisfactory rather than exceptional, they can still fulfill the general requirements of most users. Moreover, the field of database technology is constantly evolving, and many databases are considering incorporating vector search capabilities to meet the demands of their current user base. For databases that currently lack vector search functionality, it is only a matter of time before they implement these features.
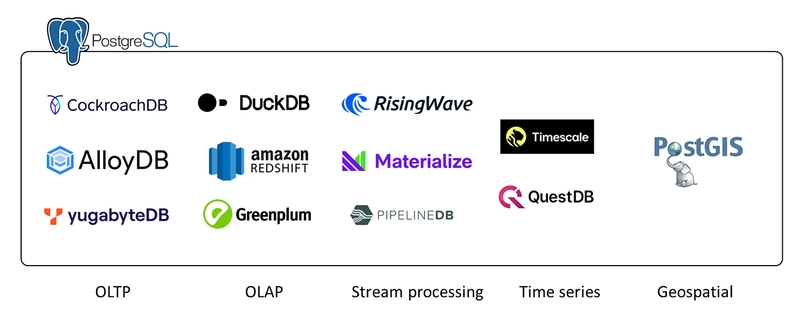
In fact, even in the absence of these commercial databases, users can effortlessly install PostgreSQL and leverage its built-in pgvector functionality for vector search. PostgreSQL stands as the benchmark in the realm of open-source databases, offering comprehensive support across various domains of database management. It excels in transaction processing (e.g., CockroachDB), online analytics (e.g., DuckDB), stream processing (e.g., RisingWave), time series analysis (e.g., Timescale), spatial analysis (e.g., PostGIS), and more. For non-professional users seeking to explore vector databases, they can readily download the open-source PostgreSQL or utilize managed services like Supabase and Neon to establish their own basic AI applications. Other than PostgreSQL, several open-source databases, including OpenSearch, ClickHouse, and Cassandra, have implemented their own vector search functionality. You do not need to adopt a new vector database if you have already used these systems.
The market landscape of vector databases has already indicated that fierce competition awaits in the future, given the availability of mature solutions catering to diverse user demands. Starting from scratch and establishing a presence in this market is undeniably a challenging endeavor.
Summary
I am filled with optimism for the future of generative AI models, and my confidence in the vector database industry remains strong. However, if someone intends to venture into the vector database field from scratch, I can only discourage them. Instead of investing in new vector database projects, it would be more advisable to concentrate on existing databases and explore opportunities to enhance them with vector engines, making them even more robust and powerful.


