![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






















































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)



























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
































































































































VirtualBox: Using host's Ollama from guest VMs.
In this article we'll be looking at using locally hosted AI in a VirtualBox environment. At the end you'll have a VirtualBox Guest running VSCode/VSCodium with the Continue extension using the VirtualBox host's Ollama service. Why would you want to do this? I don't know, I'm not you, but it is a situation I needed to solve. I have a host machine running Windows, but the work I do is almost exclusively for Linux projects. Rather than dual boot I've opted to keep Windows as the host and setup VirtualBox guest virtual machines. I am assuming you already have VirtualBox installed and your Guest VM running VSCode and now want to install Ollama and access it from the guest. The host will be providing the Ollama service. I've tried in the past to have Ollama running in a guest and exposing the host GPU for it to use. It is possible to make this work, but doing so always leaves me feeling empty and unfulfilled due to what I perceive as the inefficiency in such a setup. Also its usually a pain to setup. This is easy-peasy so lets get started. Install Ollama On Windows installing Ollama couldn't be easier. You can download the installer here: https://ollama.com/download/windows Find OllamaSetup.exe in your Downloads folder and run it. Click the Install button and !boom! done. The setup program not only installs Ollama, but starts the background service automatically. Next we need to install one or more models. There are tons of choices here. Which ones you use are largely user and task specific. You can find a list of the models Ollama supports and instructions to install them at https://ollama.com/library. The models I am using, llama3 and qwen2.5-coder can be installed using these commands from a terminal window: ollama pull llama3.1:8b ollama pull qwen2.5-coder:latest These two have very good performance on my system with an AMD Radeon RX 7700S with 8 gigabytes of VRAM. Accessing Ollama from the Guest VM This is our environment. Host running Ollama and Guest wanting to access it. The Guest networking is being provided by VirtualBox's "NAT" network. If you've left everything as default then as seen from the Guest, the Host's IP address is 10.0.2.2. The Ollama service runs on port 11434. So you can access it with the URL "http://10.0.2.2:11434" in the Guest just to make sure it is working: Since we're inside the Guest VM lets take care of getting Continue added to VSCode. To do that click the Extensions button on the left side of the VSCode window. In the Search field type "Continue" then click the install button for the extension. Once it is installed you're ready to configure it to use your local Ollama service. To do that you need to edit a text file inside the Guest VM. This is where the file is for Linux and Windows guests: Linux: *~/.continue/config.yaml* Windows: *%USERPROFILE%\\.continue\\config.yaml* Regardless of the Guest OS here is what to put in that file, replacing the Local Assistant section entirely. name: Local Assistant version: 1.0.0 schema: v1 models: - name: chat provider: ollama model: llama3.1:8b apiBase: http://10.0.2.2:11434 type: chat - name: autocomplete provider: ollama model: qwen2.5-coder:latest apiBase: http://10.0.2.2:11434 type: autocomplete context: - provider: code - provider: docs - provider: diff - provider: terminal - provider: problems - provider: folder - provider: codebase After you save the file Continue will probably pick up the changes automatically. If it doesn't click on Extensions again and see if Continue has a "reload" button displayed and click that if so. Otherwise if it still hasn't picked up the changes just restart VSCode. Conclusion If everything has gone well then you can highlight some code and press CTRL-L and Continue will open a pane to let you ask questions about the block of code. Above I'm asking it why my overly complex Hello World program isn't working and Continue is pointing out my obvious mistake and offering to fix it. Fantastic. Incidentally you can use the same URL to expose the Host's Ollama service to other applications and services running in your Guest. For instance here is a Docker Compose file that will run the Open WebUI service inside of your Guest: version: '3.8' services: open-webui: image: ghcr.io/open-webui/open-webui:main container_name: open-webui ports: - "3000:8080" environment: - OLLAMA_BASE_URL=http://10.0.2.2:11434 volumes: - open-webui:/app/backend/data restart: always deploy: mode: replicated replicas: 1 volumes: open-webui: Have fun with your locally hosted AI coding assistant!
In this article we'll be looking at using locally hosted AI in a VirtualBox environment. At the end you'll have a VirtualBox Guest running VSCode/VSCodium with the Continue extension using the VirtualBox host's Ollama service. Why would you want to do this? I don't know, I'm not you, but it is a situation I needed to solve. I have a host machine running Windows, but the work I do is almost exclusively for Linux projects. Rather than dual boot I've opted to keep Windows as the host and setup VirtualBox guest virtual machines.
I am assuming you already have VirtualBox installed and your Guest VM running VSCode and now want to install Ollama and access it from the guest. The host will be providing the Ollama service. I've tried in the past to have Ollama running in a guest and exposing the host GPU for it to use. It is possible to make this work, but doing so always leaves me feeling empty and unfulfilled due to what I perceive as the inefficiency in such a setup. Also its usually a pain to setup. This is easy-peasy so lets get started.
Install Ollama
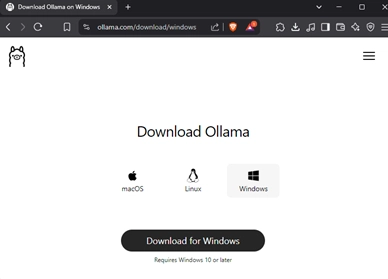
On Windows installing Ollama couldn't be easier. You can download the installer here: https://ollama.com/download/windows
Find OllamaSetup.exe in your Downloads folder and run it. Click the Install button and !boom! done.
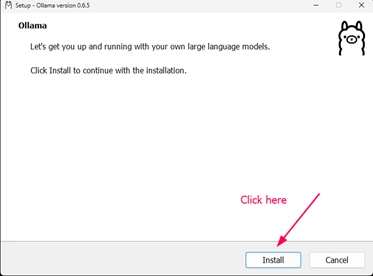
The setup program not only installs Ollama, but starts the background service automatically.
Next we need to install one or more models. There are tons of choices here. Which ones you use are largely user and task specific. You can find a list of the models Ollama supports and instructions to install them at https://ollama.com/library. The models I am using, llama3 and qwen2.5-coder can be installed using these commands from a terminal window:
ollama pull llama3.1:8b
ollama pull qwen2.5-coder:latest
These two have very good performance on my system with an AMD Radeon RX 7700S with 8 gigabytes of VRAM.
Accessing Ollama from the Guest VM
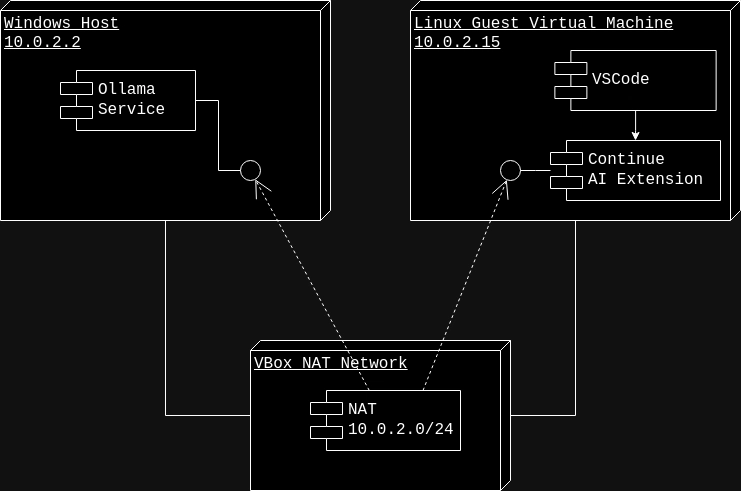
This is our environment. Host running Ollama and Guest wanting to access it. The Guest networking is being provided by VirtualBox's "NAT" network. If you've left everything as default then as seen from the Guest, the Host's IP address is 10.0.2.2. The Ollama service runs on port 11434. So you can access it with the URL "http://10.0.2.2:11434" in the Guest just to make sure it is working:

Since we're inside the Guest VM lets take care of getting Continue added to VSCode. To do that click the Extensions button on the left side of the VSCode window.
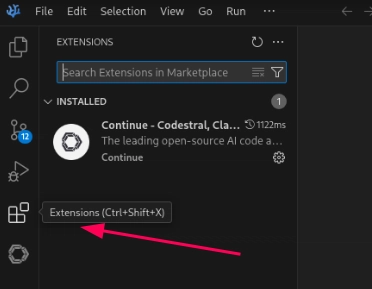
In the Search field type "Continue" then click the install button for the extension. Once it is installed you're ready to configure it to use your local Ollama service. To do that you need to edit a text file inside the Guest VM. This is where the file is for Linux and Windows guests:
Linux: *~/.continue/config.yaml*
Windows: *%USERPROFILE%\\.continue\\config.yaml*
Regardless of the Guest OS here is what to put in that file, replacing the Local Assistant section entirely.
name: Local Assistant
version: 1.0.0
schema: v1
models:
- name: chat
provider: ollama
model: llama3.1:8b
apiBase: http://10.0.2.2:11434
type: chat
- name: autocomplete
provider: ollama
model: qwen2.5-coder:latest
apiBase: http://10.0.2.2:11434
type: autocomplete
context:
- provider: code
- provider: docs
- provider: diff
- provider: terminal
- provider: problems
- provider: folder
- provider: codebase
After you save the file Continue will probably pick up the changes automatically. If it doesn't click on Extensions again and see if Continue has a "reload" button displayed and click that if so. Otherwise if it still hasn't picked up the changes just restart VSCode.
Conclusion
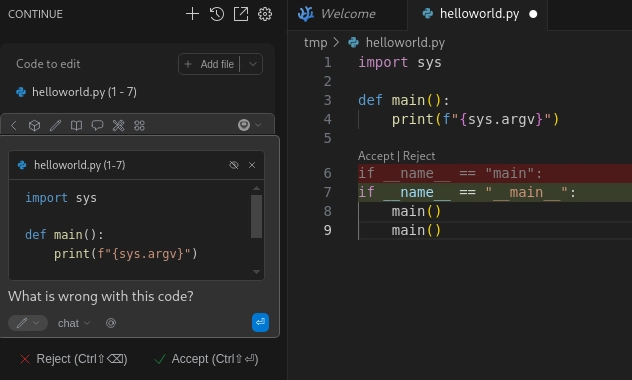
If everything has gone well then you can highlight some code and press CTRL-L and Continue will open a pane to let you ask questions about the block of code. Above I'm asking it why my overly complex Hello World program isn't working and Continue is pointing out my obvious mistake and offering to fix it. Fantastic.
Incidentally you can use the same URL to expose the Host's Ollama service to other applications and services running in your Guest. For instance here is a Docker Compose file that will run the Open WebUI service inside of your Guest:
version: '3.8'
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
ports:
- "3000:8080"
environment:
- OLLAMA_BASE_URL=http://10.0.2.2:11434
volumes:
- open-webui:/app/backend/data
restart: always
deploy:
mode: replicated
replicas: 1
volumes:
open-webui:
Have fun with your locally hosted AI coding assistant!