![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)

































































































































![From fast food worker to cybersecurity engineer with Tae'lur Alexis [Podcast #169]](https://cdn.hashnode.com/res/hashnode/image/upload/v1745242807605/8a6cf71c-144f-4c91-9532-62d7c92c0f65.png?#)






















![BPMN-procesmodellering [closed]](https://i.sstatic.net/l7l8q49F.png)























































































.jpg?#)
.jpg?#)



































.webp?#)

















































































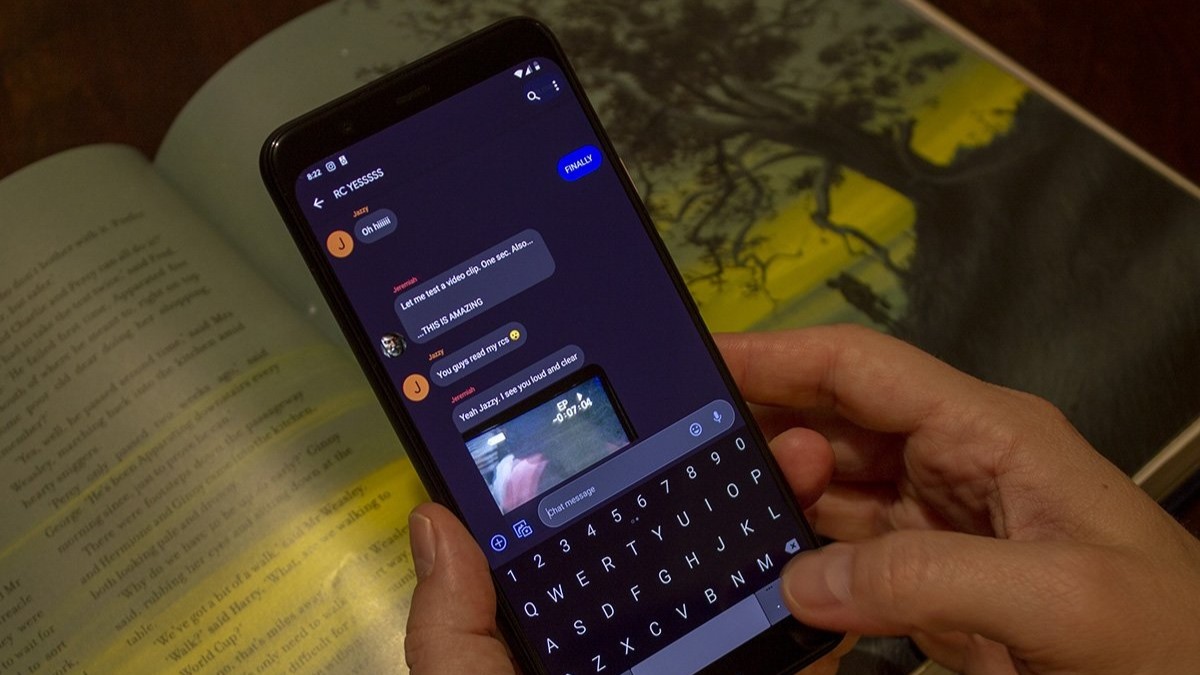







![CarPlay app with web browser for streaming video hits App Store [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2024/11/carplay-apple.jpeg?resize=1200%2C628&quality=82&strip=all&ssl=1)



![What’s new in Android’s April 2025 Google System Updates [U: 4/21]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










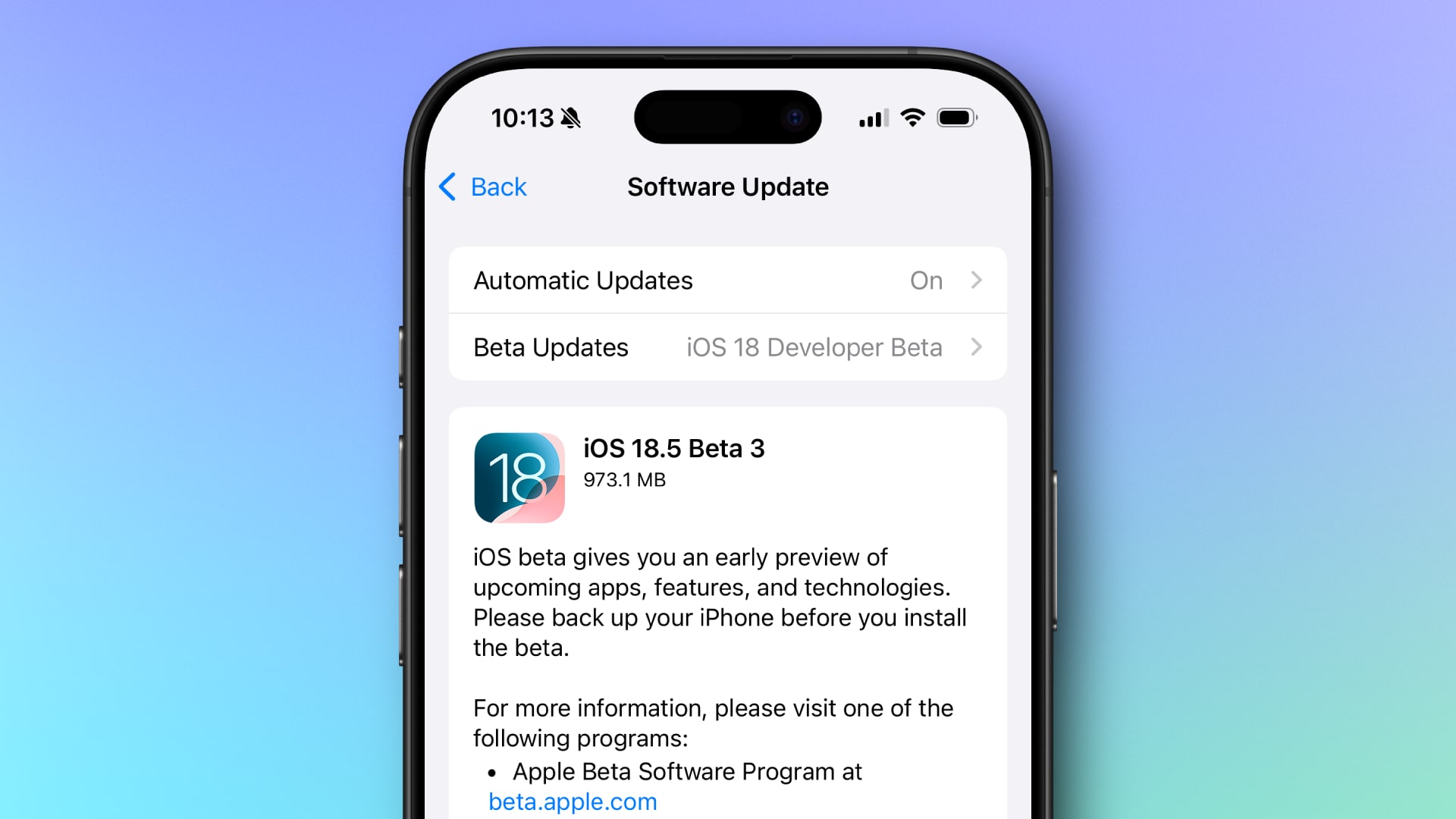
![Apple Releases iOS 18.5 Beta 3 and iPadOS 18.5 Beta 3 [Download]](https://www.iclarified.com/images/news/97076/97076/97076-640.jpg)
![Apple Seeds visionOS 2.5 Beta 3 to Developers [Download]](https://www.iclarified.com/images/news/97077/97077/97077-640.jpg)
![Apple Seeds tvOS 18.5 Beta 3 to Developers [Download]](https://www.iclarified.com/images/news/97078/97078/97078-640.jpg)
![Apple Seeds watchOS 11.5 Beta 3 to Developers [Download]](https://www.iclarified.com/images/news/97079/97079/97079-640.jpg)




















































































































Understanding How Neural Networks Can Beat Chess Champions [Simplified Explanation]
Whether Chess, Fortnite or Tekken. Neural Networks have the potential to master any game due to engineers developing a way to automatically train machines to learn from their mistakes. This is called NEAT (NeuroEvolution of Augmenting Topologies). NEAT is a genetic algorithm that mimics the process of natural selection to solve problems. This means the best solutions survive and reproduce, lesser one's do not. In this exploration of NEAT, I'll be sharing my personal understanding of how these algorithms function, drawing parallels between their optimization strategies in the clearly defined world of games and the more complex, often ambiguous landscape of real-world decision-making. By examining the concept of "fitness" in both artificial and human contexts, we can gain insights into the challenges and opportunities presented by applying evolutionary principles to problems beyond the game board. How it all works Researchers often create or use existing games as environments for training neural networks. These games provide a structured framework with clear rules and objectives, making it easier to define reward and punishment functions (also known as reward signals or feedback). The reward and punishment functions are crucial for guiding the learning process. They provide feedback to the AI, indicating whether its actions are desirable or undesirable. The design of these reward functions is critical, as they shape the AI's behavior. A poorly designed reward function can lead to unintended consequences or suboptimal performance. The entire field of Reinforcement Learning is dedicated to developing algorithms that learn effectively from these reward and punishment signals. For example, Google's DeepMind created AlphaZero, an AI that became incredibly good at Go, chess, and shogi just by playing against itself millions of times. It used a simple reward system: win (+1), lose (-1), or draw (0). This basic setup, combined with the rules of the games, was enough for AlphaZero to become stronger than any human player. You can read more about it in DeepMind's paper. Similarly, OpenAI trained AI bots to play the complex video game Dota 2. These bots also learned by playing against themselves, but the rewards were tied to things like destroying enemy structures and collecting gold. This showed that this type of learning could work even in games with many more possible actions and complicated strategies. Speed of Feedback and Parallel Learning The advantage for neural networks in games like chess stems from rapid feedback and parallel learning, allowing for faster iteration and optimization than humans. 100 Agents can learn at once compared to your one agent, you. Think about Naruto's shadow clones, if you're an anime fan. He creates clones of himself, each clone able to operate and learn individually. If that clone doesn't survive in a fight the information learned is not lost. Naruto gets a download of everything the clone experienced. Similarly, in parallel learning, each agent operates independently, but their collective experience contributes to the overall learning process, significantly accelerating optimization compared to a single learner. Unlike Naruto's clones or parallel AI agents, humans can't directly copy the neural connections and learned information from another person's brain. We rely on imperfect methods like language, demonstration, and imitation to convey knowledge. This has largely been an advantage for human's to form communities throughout history, shared lessons is an evolutionary advantage. When learning from others, we interpret and reconstruct the information based on our existing knowledge, biases, and understanding. This process introduces potential for error and loss of fidelity. What one person finds obvious, another may misinterpret. Explicit knowledge (facts, procedures) is easier to share than tacit knowledge (skills, intuition, experience). Tacit knowledge often requires prolonged practice and immersion to acquire, making it difficult to transfer efficiently. You can explain how to ride a bike, but actually learning requires practice and developing a "feel" for it. This tacit knowledge is hard us as humans to transmit. Fixed Rules vs. Real-World Complexity While there are defined rules of games providing clear win/loss conditions, accelerating learning. Real-life is more complex. Making it harder to define objective functions for optimisation. I personally believe that we create "internal games" with personalised win/loss conditions based on values like money, social status, or happiness. These are often unconscious and can be influenced by the environment. Multi-Dimensional Optimization Donald Trump's actions can be interpreted through the lens of multi-objective optimization, where he seeks to maximize both wealth and social status. Each decision he makes can be viewed as a move in two interconnected "games"—one focused on financial gain, the other on social influence
![Understanding How Neural Networks Can Beat Chess Champions [Simplified Explanation]](https://media2.dev.to/dynamic/image/width%3D1000,height%3D500,fit%3Dcover,gravity%3Dauto,format%3Dauto/https:%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2F2iegyse2rm5fqrnf11dg.jpg)
Whether Chess, Fortnite or Tekken. Neural Networks have the potential to master any game due to engineers developing a way to automatically train machines to learn from their mistakes. This is called NEAT (NeuroEvolution of Augmenting Topologies). NEAT is a genetic algorithm that mimics the process of natural selection to solve problems. This means the best solutions survive and reproduce, lesser one's do not.
In this exploration of NEAT, I'll be sharing my personal understanding of how these algorithms function, drawing parallels between their optimization strategies in the clearly defined world of games and the more complex, often ambiguous landscape of real-world decision-making. By examining the concept of "fitness" in both artificial and human contexts, we can gain insights into the challenges and opportunities presented by applying evolutionary principles to problems beyond the game board.
How it all works
Researchers often create or use existing games as environments for training neural networks. These games provide a structured framework with clear rules and objectives, making it easier to define reward and punishment functions (also known as reward signals or feedback). The reward and punishment functions are crucial for guiding the learning process. They provide feedback to the AI, indicating whether its actions are desirable or undesirable. The design of these reward functions is critical, as they shape the AI's behavior. A poorly designed reward function can lead to unintended consequences or suboptimal performance. The entire field of Reinforcement Learning is dedicated to developing algorithms that learn effectively from these reward and punishment signals.
For example, Google's DeepMind created AlphaZero, an AI that became incredibly good at Go, chess, and shogi just by playing against itself millions of times. It used a simple reward system: win (+1), lose (-1), or draw (0). This basic setup, combined with the rules of the games, was enough for AlphaZero to become stronger than any human player. You can read more about it in DeepMind's paper.
Similarly, OpenAI trained AI bots to play the complex video game Dota 2. These bots also learned by playing against themselves, but the rewards were tied to things like destroying enemy structures and collecting gold. This showed that this type of learning could work even in games with many more possible actions and complicated strategies.
Speed of Feedback and Parallel Learning
The advantage for neural networks in games like chess stems from rapid feedback and parallel learning, allowing for faster iteration and optimization than humans. 100 Agents can learn at once compared to your one agent, you. Think about Naruto's shadow clones, if you're an anime fan. He creates clones of himself, each clone able to operate and learn individually. If that clone doesn't survive in a fight the information learned is not lost. Naruto gets a download of everything the clone experienced. Similarly, in parallel learning, each agent operates independently, but their collective experience contributes to the overall learning process, significantly accelerating optimization compared to a single learner.
Unlike Naruto's clones or parallel AI agents, humans can't directly copy the neural connections and learned information from another person's brain. We rely on imperfect methods like language, demonstration, and imitation to convey knowledge. This has largely been an advantage for human's to form communities throughout history, shared lessons is an evolutionary advantage. When learning from others, we interpret and reconstruct the information based on our existing knowledge, biases, and understanding. This process introduces potential for error and loss of fidelity. What one person finds obvious, another may misinterpret.
Explicit knowledge (facts, procedures) is easier to share than tacit knowledge (skills, intuition, experience). Tacit knowledge often requires prolonged practice and immersion to acquire, making it difficult to transfer efficiently. You can explain how to ride a bike, but actually learning requires practice and developing a "feel" for it. This tacit knowledge is hard us as humans to transmit.
Fixed Rules vs. Real-World Complexity
While there are defined rules of games providing clear win/loss conditions, accelerating learning. Real-life is more complex. Making it harder to define objective functions for optimisation. I personally believe that we create "internal games" with personalised win/loss conditions based on values like money, social status, or happiness. These are often unconscious and can be influenced by the environment.
Multi-Dimensional Optimization
Donald Trump's actions can be interpreted through the lens of multi-objective optimization, where he seeks to maximize both wealth and social status. Each decision he makes can be viewed as a move in two interconnected "games"—one focused on financial gain, the other on social influence and recognition. He constantly weighs the potential rewards and penalties within each game, seeking actions that offer the greatest combined benefit. For example, a business deal might increase his wealth but potentially damage his social standing if perceived as unethical, requiring him to balance competing incentives. His pronouncements and policies often generate controversy, which may negatively impact his wealth game but simultaneously boost his social status game by keeping him in the public eye and energizing his base. This constant juggling act suggests a complex decision-making process driven by a desire to "win" in multiple arenas simultaneously, even if those arenas have conflicting rules and objectives.
Herein, lies a potential challenge for evolving artificial neural networks (ANNs). Some games you cannot clone yourself, Trump may only have one chance to negotiate a peace deal, and what worked while negotiating deals in North America may not work in China. Real-world scenarios often present unique, non-repeatable situations with limited opportunities for trial and error. Unlike in a game of chess where countless matches can be simulated, real-life decisions often carry irreversible consequences. Transferring knowledge learned in one context to a vastly different one, as with international diplomacy, becomes exceedingly difficult. An ANN trained on historical data might struggle to adapt to novel geopolitical landscapes or cultural nuances, highlighting the limitations of relying solely on past experience in complex, dynamic environments where the rules themselves are constantly evolving and the stakes are exceptionally high. The ability to generalize from limited data and adapt to unforeseen circumstances remains a significant hurdle in developing truly intelligent AI systems capable of navigating the complexities of the real world.
Fitness function and optimization
Fitness function and optimization in real life, when viewed through the lens of game theory, suggests a more fundamental goal than simply individual success: ensuring the continuity of the game itself—the continuation of life on Earth. If the ultimate objective is to be the richest person, a two-stage strategy might emerge. Stage one focuses on accumulating maximum wealth. However, stage two presents a dilemma: to maintain this position requires preventing others from surpassing you. This could manifest as actively hindering competition, potentially to the point of societal collapse, effectively ending the game by rendering humanity extinct. Alternatively, it could involve manipulating the rules to such an extent that the game becomes unfairly skewed, discouraging participation and innovation from others. Such a strategy, while potentially effective in the short term, ultimately undermines the long-term sustainability of the game, highlighting a critical tension between individual gain and collective well-being. True optimization, therefore, might involve maximizing not just personal wealth but also the overall health and resilience of the system, ensuring the game continues for all players. This perspective suggests a need for cooperation and a more holistic definition of "winning" that considers the long-term consequences of individual actions on the entire system.
This concept of optimizing for long-term sustainability, rather than solely for individual gain, presents a crucial challenge in evolving artificial neural networks (ANNs). Current AI systems are often trained with narrow, specific objectives, much like the short-sighted goal of maximizing individual wealth. This can lead to unintended consequences if the ANN's actions negatively impact the broader system it operates within. For example, an AI tasked with maximizing advertising revenue might resort to manipulative or intrusive tactics that ultimately degrade user experience and erode trust, harming the long-term viability of the platform it operates on.
Just as in the hypothetical scenario of the ultra-rich individual, optimizing solely for a narrow objective can lead to the degradation or even collapse of the overall system. Therefore, developing robust and beneficial AI requires incorporating broader, system-level objectives into the fitness function, encouraging ANNs to evolve strategies that promote not just immediate performance but also the long-term health and stability of the environment they inhabit. This shift necessitates a move beyond simple reward functions towards more holistic evaluation metrics that consider the broader impact of AI actions on the overall ecosystem.