








































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)
































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)
































































































![Switch 2 Pre-Order Rules Are Some BS: Here's How They Work [Update]](https://i.kinja-img.com/image/upload/c_fill,h_675,pg_1,q_80,w_1200/485ec87fd3cea832387b2699e4cbd2a1.jpg)











.png?#)




(1).jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)




-Mario-Kart-World-Hands-On-Preview-Is-It-Good-00-08-36.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)






















_NicoElNino_Alamy.png?#)
_Igor_Mojzes_Alamy.jpg?#)

.webp?#)
.webp?#)








































































































![Blackmagic Design Unveils DaVinci Resolve 20 With Over 100 New Features and AI Tools [Video]](https://www.iclarified.com/images/news/96951/96951/96951-640.jpg)


![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)





















































































































Understanding Data Pipelines: The Backbone of Modern Data Systems
In today’s data-driven world, organizations are collecting vast amounts of data from various sources — websites, applications, sensors, APIs, and more. But raw data is rarely useful on its own. It needs to be ingested, transformed, cleaned, stored, and analyzed. This is where data pipelines come into play. A data pipeline is a series of processes and tools that automate the movement and transformation of data from its source to its final destination — whether that’s a data warehouse, business intelligence dashboard, or machine learning model. ⸻ What Makes Up a Data Pipeline? A typical data pipeline consists of several core stages: Source: Where the data originates (e.g., databases, APIs, logs, IoT devices). Ingestion: Moving data into the pipeline (batch or real-time). Transformation: Cleaning, joining, enriching, or aggregating data. Storage: Saving data to a data lake, data warehouse, or operational database. Destination: The final consumer — BI tools, reporting dashboards, ML systems, or analytics apps. ⸻ Advantages of Data Pipelines Automation and Efficiency Data pipelines eliminate the need for manual data handling. This automation saves time, reduces errors, and increases reliability. Scalability Modern cloud-based pipelines (like Google Cloud Dataflow, AWS Glue, and Azure Data Factory) scale easily as your data grows, making it easy to handle terabytes or even petabytes of data. Real-Time Processing With tools like Apache Kafka, Apache Flink, and Spark Streaming, pipelines can process data in near real-time, enabling fast decision-making and live analytics. Improved Data Quality Pipelines can include data validation, error handling, deduplication, and transformation logic to ensure only clean, consistent data makes it to the destination. Support for Complex Architectures They are essential in microservices environments, hybrid clouds, and data mesh architectures — making them versatile across modern data landscapes. Observability and Monitoring Tools like Apache Airflow, Dagster, and Prefect offer visibility into pipeline performance, helping detect bottlenecks and failures quickly. ⸻ Challenges and Disadvantages While data pipelines offer immense benefits, they are not without challenges: Complexity and Maintenance Overhead As pipelines scale, so does their complexity. Managing dependencies, retries, and data integrity across multiple components can become overwhelming. High Costs Real-time pipelines and cloud storage can incur significant costs if not managed properly. Unused compute resources and inefficient data transfers can lead to budget overruns. Latency in Batch Pipelines Batch-oriented pipelines may not be suitable for applications requiring real-time data, introducing delays in data availability. Data Quality Dependency A pipeline is only as good as the data fed into it. Without proper upstream data governance, the entire system can suffer. Security and Compliance Ensuring compliance with regulations like GDPR or HIPAA adds another layer of complexity — pipelines must handle encryption, anonymization, and access control properly. Tool Overload and Integration Friction The abundance of tools — dbt, Kafka, Airflow, Snowflake, Fivetran, etc. — can make tool selection and integration a daunting task. ⸻ New Trends and Emerging Advantages As the field evolves, new capabilities are transforming how we think about data pipelines: Low-Code/No-Code Pipeline Builders Platforms like Azure Data Factory, Alteryx, and Power Automate allow non-developers to build pipelines, democratizing data engineering. DataOps and CI/CD for Pipelines Bringing DevOps practices into data pipelines ensures better testing, versioning, deployment, and rollback — increasing stability and agility. AI-Augmented Pipelines With built-in ML, pipelines can now detect anomalies, self-heal, and optimize performance on the fly. Serverless and Event-Driven Architectures Services like AWS Lambda and Google Cloud Functions allow pipelines to react to data events without provisioning or managing servers. Unified Batch and Streaming Frameworks like Apache Beam let you design one pipeline that can handle both batch and real-time data — simplifying architecture and development. End-to-End Observability and Governance Modern solutions come with deep monitoring, data lineage, and auditing capabilities that enhance trust and compliance. ⸻ Conclusion Data pipelines are no longer just “back-end plumbing” — they are strategic assets that empower organizations to move fast, scale efficiently, and make data-driven decisions. While they come with challenges in cost, complexity, and maintenance, advancements in AI, low-code platforms, and DataOps are helping teams build smarter, more resilient pipelines. As organizations continue to generate and rely on data, investing in robust data pipelines is no longer optional — it’s essential.

In today’s data-driven world, organizations are collecting vast amounts of data from various sources — websites, applications, sensors, APIs, and more. But raw data is rarely useful on its own. It needs to be ingested, transformed, cleaned, stored, and analyzed. This is where data pipelines come into play.
A data pipeline is a series of processes and tools that automate the movement and transformation of data from its source to its final destination — whether that’s a data warehouse, business intelligence dashboard, or machine learning model.
⸻
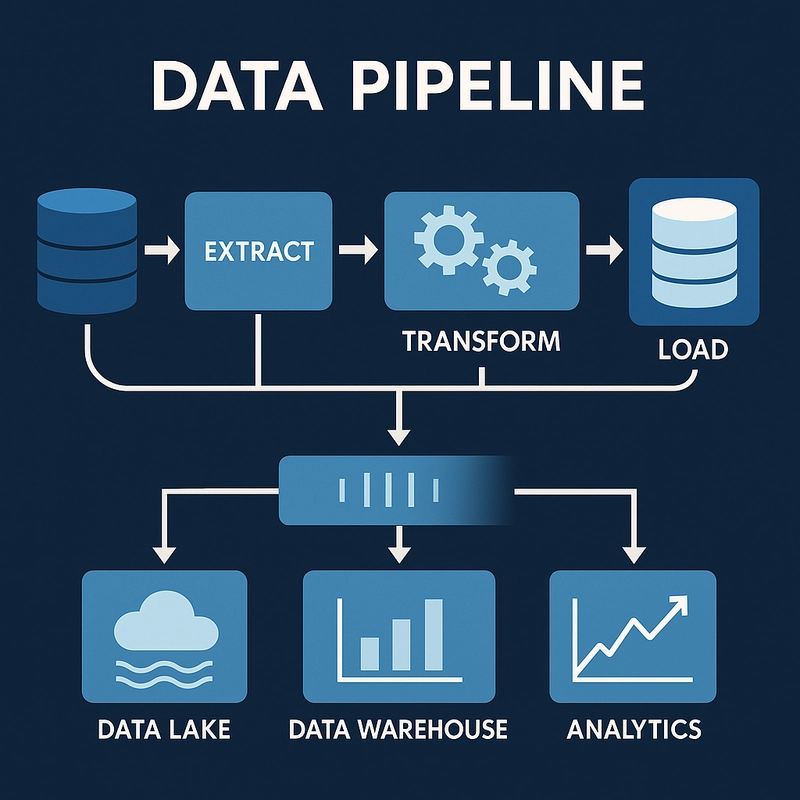
What Makes Up a Data Pipeline?
A typical data pipeline consists of several core stages:
Source: Where the data originates (e.g., databases, APIs, logs, IoT devices).
Ingestion: Moving data into the pipeline (batch or real-time).
Transformation: Cleaning, joining, enriching, or aggregating data.
Storage: Saving data to a data lake, data warehouse, or operational database.
Destination: The final consumer — BI tools, reporting dashboards, ML systems, or analytics apps.
⸻
Advantages of Data Pipelines
Automation and Efficiency
Data pipelines eliminate the need for manual data handling. This automation saves time, reduces errors, and increases reliability.Scalability
Modern cloud-based pipelines (like Google Cloud Dataflow, AWS Glue, and Azure Data Factory) scale easily as your data grows, making it easy to handle terabytes or even petabytes of data.Real-Time Processing
With tools like Apache Kafka, Apache Flink, and Spark Streaming, pipelines can process data in near real-time, enabling fast decision-making and live analytics.Improved Data Quality
Pipelines can include data validation, error handling, deduplication, and transformation logic to ensure only clean, consistent data makes it to the destination.Support for Complex Architectures
They are essential in microservices environments, hybrid clouds, and data mesh architectures — making them versatile across modern data landscapes.Observability and Monitoring
Tools like Apache Airflow, Dagster, and Prefect offer visibility into pipeline performance, helping detect bottlenecks and failures quickly.
⸻
Challenges and Disadvantages
While data pipelines offer immense benefits, they are not without challenges:
Complexity and Maintenance Overhead
As pipelines scale, so does their complexity. Managing dependencies, retries, and data integrity across multiple components can become overwhelming.High Costs
Real-time pipelines and cloud storage can incur significant costs if not managed properly. Unused compute resources and inefficient data transfers can lead to budget overruns.Latency in Batch Pipelines
Batch-oriented pipelines may not be suitable for applications requiring real-time data, introducing delays in data availability.Data Quality Dependency
A pipeline is only as good as the data fed into it. Without proper upstream data governance, the entire system can suffer.Security and Compliance
Ensuring compliance with regulations like GDPR or HIPAA adds another layer of complexity — pipelines must handle encryption, anonymization, and access control properly.Tool Overload and Integration Friction
The abundance of tools — dbt, Kafka, Airflow, Snowflake, Fivetran, etc. — can make tool selection and integration a daunting task.
⸻
New Trends and Emerging Advantages
As the field evolves, new capabilities are transforming how we think about data pipelines:
Low-Code/No-Code Pipeline Builders
Platforms like Azure Data Factory, Alteryx, and Power Automate allow non-developers to build pipelines, democratizing data engineering.DataOps and CI/CD for Pipelines
Bringing DevOps practices into data pipelines ensures better testing, versioning, deployment, and rollback — increasing stability and agility.AI-Augmented Pipelines
With built-in ML, pipelines can now detect anomalies, self-heal, and optimize performance on the fly.Serverless and Event-Driven Architectures
Services like AWS Lambda and Google Cloud Functions allow pipelines to react to data events without provisioning or managing servers.Unified Batch and Streaming
Frameworks like Apache Beam let you design one pipeline that can handle both batch and real-time data — simplifying architecture and development.End-to-End Observability and Governance
Modern solutions come with deep monitoring, data lineage, and auditing capabilities that enhance trust and compliance.
⸻
Conclusion
Data pipelines are no longer just “back-end plumbing” — they are strategic assets that empower organizations to move fast, scale efficiently, and make data-driven decisions. While they come with challenges in cost, complexity, and maintenance, advancements in AI, low-code platforms, and DataOps are helping teams build smarter, more resilient pipelines.
As organizations continue to generate and rely on data, investing in robust data pipelines is no longer optional — it’s essential.



