















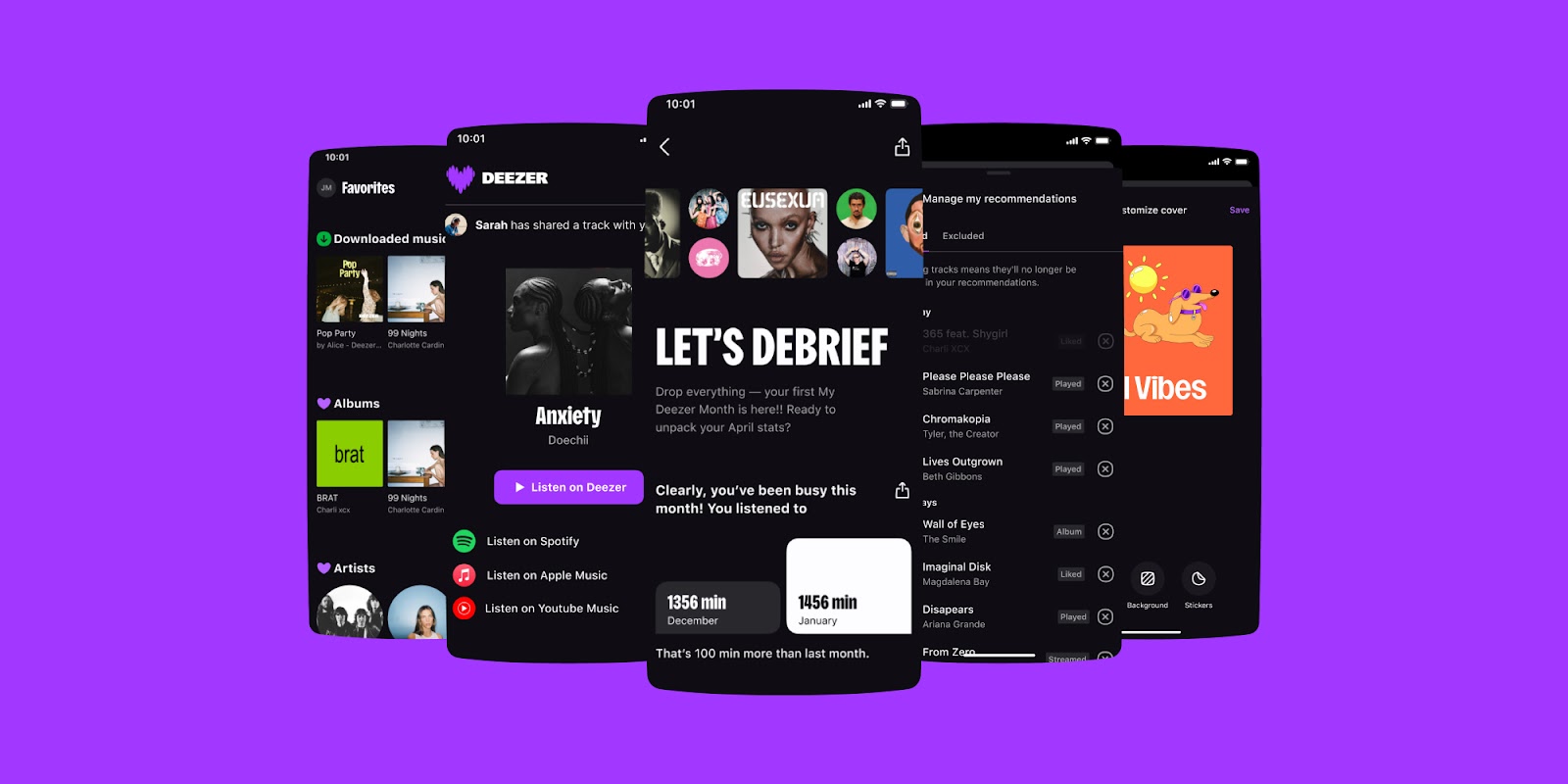


























































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)




































































































































































































![Blue Archive tier list [April 2025]](https://media.pocketgamer.com/artwork/na-33404-1636469504/blue-archive-screenshot-2.jpg?#)

































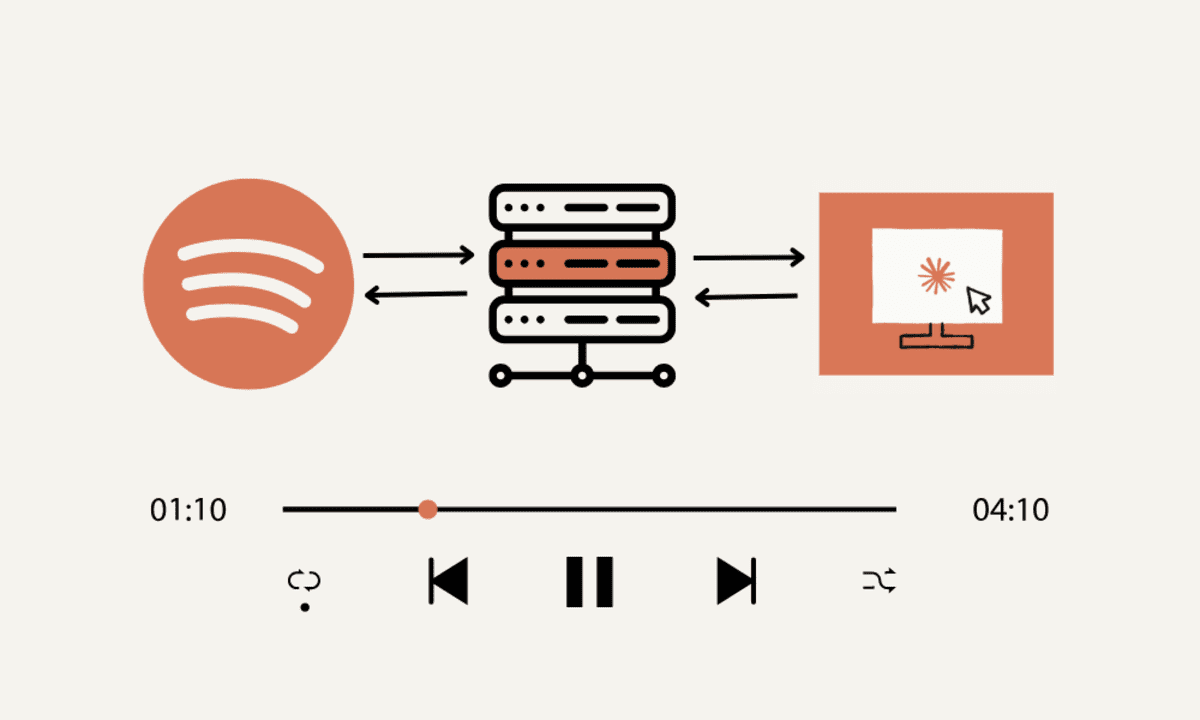
.png?#)







.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)





























.webp?#)
















































































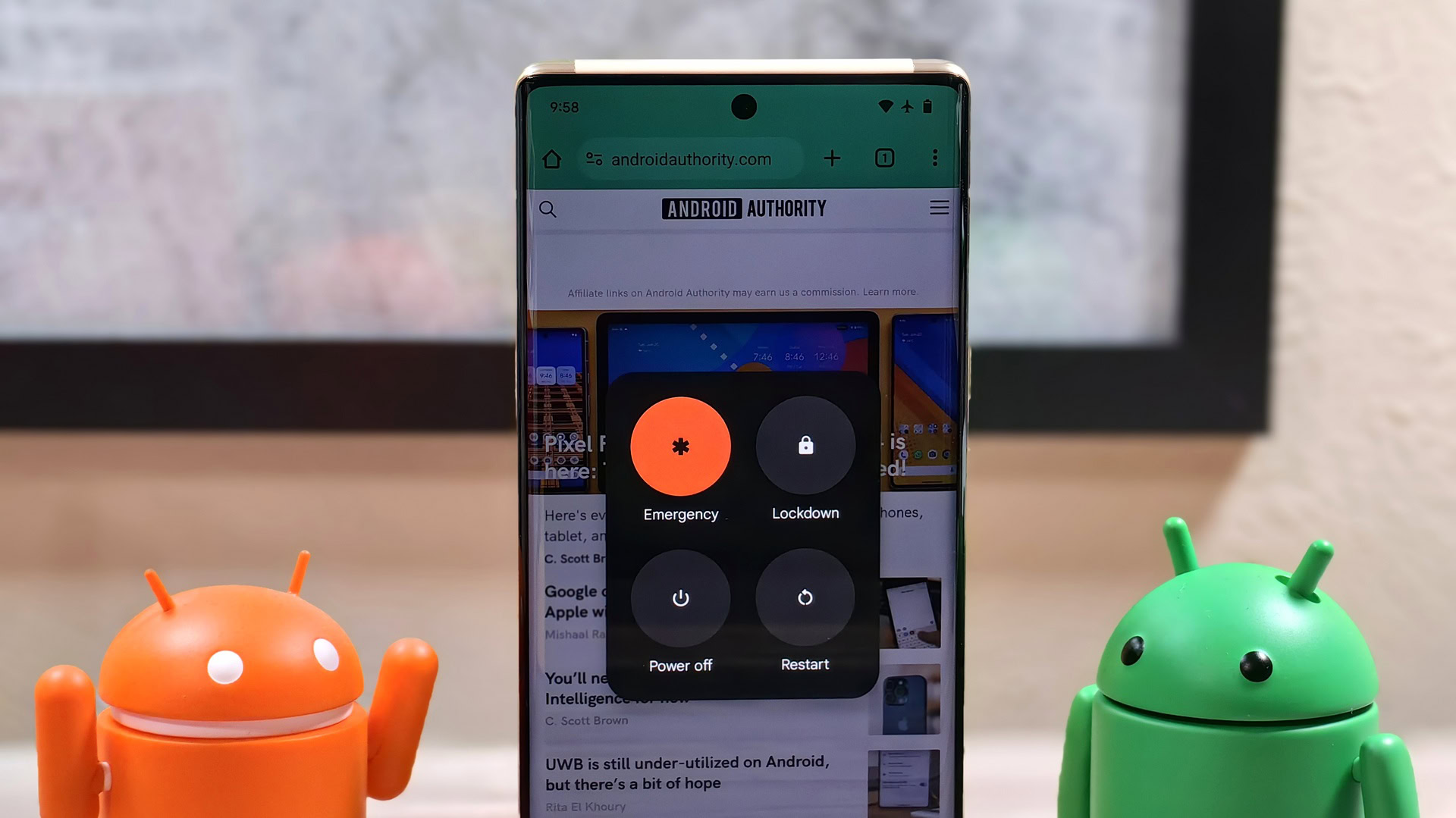



![[Update: Optional] Google rolling out auto-restart security feature to Android](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-2.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)












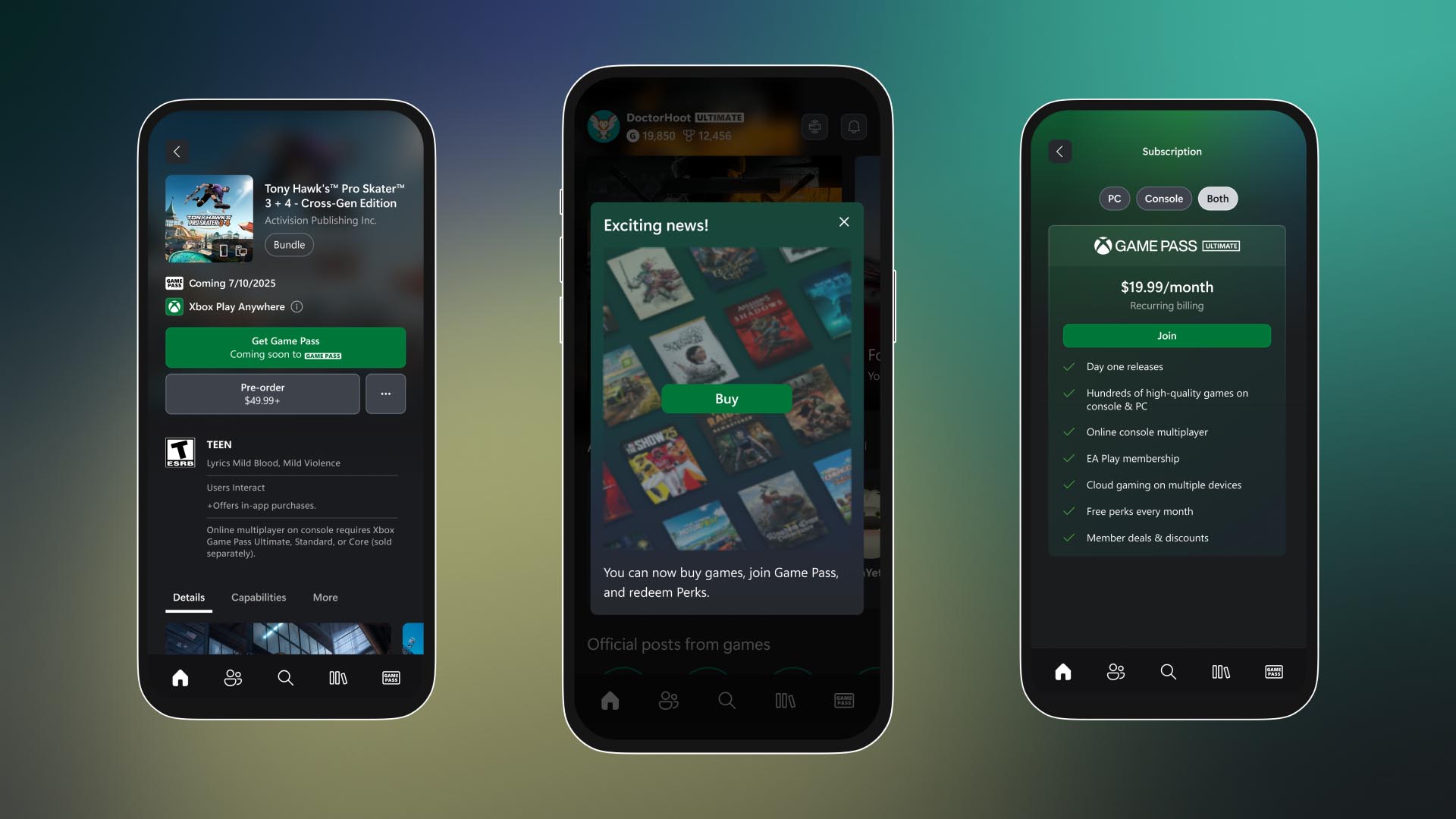
![Apple Releases iOS 18.4.1 and iPadOS 18.4.1 [Download]](https://www.iclarified.com/images/news/97043/97043/97043-640.jpg)
![Apple Releases visionOS 2.4.1 for Vision Pro [Download]](https://www.iclarified.com/images/news/97046/97046/97046-640.jpg)
![Apple Vision 'Air' Headset May Feature Titanium and iPhone 5-Era Black Finish [Rumor]](https://www.iclarified.com/images/news/97040/97040/97040-640.jpg)




















































































































Understanding Data Abstraction in Databases
In the intricate world of Database Management Systems (DBMS), the sheer volume and complexity of data can be overwhelming. Developers and end-users need to interact with this data without getting bogged down in the low-level details of how it's physically stored and organized. This is where data abstraction in DBMS comes to the rescue. It's a fundamental concept that simplifies the interaction with databases by hiding unnecessary implementation complexities and presenting different levels of data views. Essentially, data abstraction in DBMS is the process of hiding the intricate details of data storage and retrieval while providing users with a conceptual view of the data that is easy to understand and work with. Imagine trying to find a specific book in a massive library where the books are scattered randomly without any organization. It would be a chaotic and inefficient process. Data abstraction provides the organizational structure, allowing you to access the information you need without knowing the exact shelf and position of the book. The Layers of Data Abstraction: To achieve this simplification, data abstraction in DBMS typically employs a three-level architecture: Physical Level (Internal Level): This is the lowest level of abstraction and describes how the data is actually stored in the database. It deals with the physical storage structures, file organization, data formats, and access methods. Details like disk allocation, indexing techniques, and data compression are managed at this level. End-users and even most developers are shielded from these intricate physical storage details. Logical Level (Conceptual Level): This level describes what data is stored in the database and the relationships that exist among the data elements. It provides a conceptual schema that defines the overall structure of the database in terms of entities, attributes, and their relationships. Database administrators and application developers primarily work at this level. For instance, the logical level would define tables like "Customers" with attributes like "CustomerID," "Name," and "Address," and the relationships between "Customers" and "Orders." It doesn't specify how this data is physically stored. View Level (External Level): This is the highest level of abstraction and describes only a part of the entire database. It provides customized views of the data tailored to the specific needs of different user groups or applications. Multiple views can be defined over the same database, each presenting the data in a way that is relevant to a particular user. For example, the sales department might have a view showing customer names and order details, while the billing department might have a view showing customer IDs and payment information. The view level hides data that is not relevant to a particular user, simplifying their interaction with the database. Benefits of Data Abstraction: Implementing data abstraction in DBMS offers several significant advantages: • Data Independence: Abstraction provides data independence, meaning that changes made at one level do not necessarily affect the levels above it. o Physical Data Independence: Changes in the physical storage structures (e.g., changing file organization or using a different storage device) can be made without affecting the logical schema or the applications that access the data. o Logical Data Independence: Changes in the logical schema (e.g., adding a new attribute or modifying relationships) can be made without necessarily affecting the user views or the applications that rely on those views. • Simplified User Interaction: By hiding the underlying complexities, data abstraction makes it easier for users to interact with the database. They can focus on the data they need without worrying about the technical details of storage and retrieval. • Improved Database Maintainability: Data independence makes it easier for database administrators to manage and maintain the database without disrupting applications. They can optimize storage structures or modify the logical schema as needed. • Enhanced Security: By providing specific views to different users, data abstraction can enhance security by limiting their access to only the data they need to see. In Conclusion: Data abstraction in DBMS is a fundamental principle that simplifies the interaction with databases by providing different levels of data views and hiding implementation complexities. The three-level architecture – physical, logical, and view – ensures data independence, simplifies user interaction, improves maintainability, and enhances security. By understanding and leveraging the power of data abstraction, we can build more user-friendly, flexible, and robust database systems.

In the intricate world of Database Management Systems (DBMS), the sheer volume and complexity of data can be overwhelming. Developers and end-users need to interact with this data without getting bogged down in the low-level details of how it's physically stored and organized. This is where data abstraction in DBMS comes to the rescue. It's a fundamental concept that simplifies the interaction with databases by hiding unnecessary implementation complexities and presenting different levels of data views.
Essentially, data abstraction in DBMS is the process of hiding the intricate details of data storage and retrieval while providing users with a conceptual view of the data that is easy to understand and work with. Imagine trying to find a specific book in a massive library where the books are scattered randomly without any organization. It would be a chaotic and inefficient process. Data abstraction provides the organizational structure, allowing you to access the information you need without knowing the exact shelf and position of the book.
The Layers of Data Abstraction:
To achieve this simplification, data abstraction in DBMS typically employs a three-level architecture:
- Physical Level (Internal Level): This is the lowest level of abstraction and describes how the data is actually stored in the database. It deals with the physical storage structures, file organization, data formats, and access methods. Details like disk allocation, indexing techniques, and data compression are managed at this level. End-users and even most developers are shielded from these intricate physical storage details.
- Logical Level (Conceptual Level): This level describes what data is stored in the database and the relationships that exist among the data elements. It provides a conceptual schema that defines the overall structure of the database in terms of entities, attributes, and their relationships. Database administrators and application developers primarily work at this level. For instance, the logical level would define tables like "Customers" with attributes like "CustomerID," "Name," and "Address," and the relationships between "Customers" and "Orders." It doesn't specify how this data is physically stored.
- View Level (External Level): This is the highest level of abstraction and describes only a part of the entire database. It provides customized views of the data tailored to the specific needs of different user groups or applications. Multiple views can be defined over the same database, each presenting the data in a way that is relevant to a particular user. For example, the sales department might have a view showing customer names and order details, while the billing department might have a view showing customer IDs and payment information. The view level hides data that is not relevant to a particular user, simplifying their interaction with the database. Benefits of Data Abstraction: Implementing data abstraction in DBMS offers several significant advantages: • Data Independence: Abstraction provides data independence, meaning that changes made at one level do not necessarily affect the levels above it. o Physical Data Independence: Changes in the physical storage structures (e.g., changing file organization or using a different storage device) can be made without affecting the logical schema or the applications that access the data. o Logical Data Independence: Changes in the logical schema (e.g., adding a new attribute or modifying relationships) can be made without necessarily affecting the user views or the applications that rely on those views. • Simplified User Interaction: By hiding the underlying complexities, data abstraction makes it easier for users to interact with the database. They can focus on the data they need without worrying about the technical details of storage and retrieval. • Improved Database Maintainability: Data independence makes it easier for database administrators to manage and maintain the database without disrupting applications. They can optimize storage structures or modify the logical schema as needed. • Enhanced Security: By providing specific views to different users, data abstraction can enhance security by limiting their access to only the data they need to see. In Conclusion: Data abstraction in DBMS is a fundamental principle that simplifies the interaction with databases by providing different levels of data views and hiding implementation complexities. The three-level architecture – physical, logical, and view – ensures data independence, simplifies user interaction, improves maintainability, and enhances security. By understanding and leveraging the power of data abstraction, we can build more user-friendly, flexible, and robust database systems.



