








































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)

































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)












































































































.jpg?#)

































_ArtemisDiana_Alamy.jpg?#)


 (1).webp?#)




































































-xl.jpg)












![Yes, the Gemini icon is now bigger and brighter on Android [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/02/Gemini-on-Galaxy-S25.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)











![Apple Rushes Five Planes of iPhones to US Ahead of New Tariffs [Report]](https://www.iclarified.com/images/news/96967/96967/96967-640.jpg)
![Apple Vision Pro 2 Allegedly in Production Ahead of 2025 Launch [Rumor]](https://www.iclarified.com/images/news/96965/96965/96965-640.jpg)




















































































































TRISUM: A Hybrid Graph-Based Keyword Extraction Algorithm
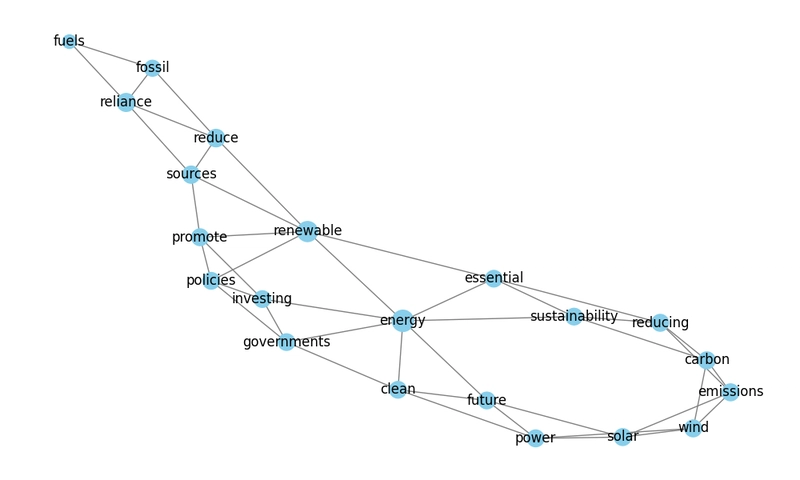
1️⃣ Introduction Keyword extraction is a crucial technique in Natural Language Processing (NLP) that automatically identifies the most important words or phrases in a document. These keywords help summarize content, improve searchability, and enhance text analysis. However, traditional keyword extraction methods have limitations, such as lacking contextual understanding or failing in short documents. To overcome these challenges, we introduce TRISUM, a hybrid graph-based keyword extraction algorithm that combines the strengths of multiple techniques to improve accuracy and relevance. Overview of Keyword Extraction in NLP Keyword extraction is widely used in: Search Engines – Identifying relevant content based on user queries. Academic Research – Summarizing research papers by extracting key concepts. Content Optimization – Improving SEO rankings by using high-impact keywords. Writing Assistance – Analyzing student essays to ensure topic relevance. For instance, if a research paper discusses climate change, a good keyword extraction method should highlight words like global warming, carbon footprint, renewable energy, and sustainability while ignoring less relevant terms. Importance of Accurate Keyword Extraction A high-quality keyword extraction algorithm is important because: ✅ Enhances Information Retrieval – Helps search engines and databases retrieve relevant content efficiently. ✅ Improves Content Summarization – Extracts key points from long documents. ✅ Optimizes SEO – Identifies high-value keywords for better ranking. ✅ Supports Writing Analysis – Ensures that an essay aligns with its given topic. If keyword extraction is inaccurate, it may miss crucial terms or extract irrelevant words, reducing its effectiveness. Limitations of Existing Methods Several existing keyword extraction techniques come with drawbacks: 1. TF-IDF (Term Frequency-Inverse Document Frequency) ✅ Simple & fast for basic keyword extraction. ❌ Lacks contextual understanding – It only counts word frequency, ignoring meaning. ❌ Fails in short texts – Cannot effectively extract keywords from small documents. 2. YAKE (Yet Another Keyword Extractor) ✅ Language-independent & works well on short texts. ❌ Limited semantic understanding – Cannot differentiate between words with multiple meanings. 3. KeyBERT (BERT-based Keyword Extraction) ✅ Understands word relationships and context. ❌ Requires high computational power (GPU). ❌ Slower on large datasets. Since no single method is perfect, we need a hybrid approach that combines multiple techniques for improved accuracy. Introduction to TRISUM TRISUM is a hybrid keyword extraction algorithm that improves accuracy by combining three graph-based ranking techniques:
1️⃣ Introduction
Keyword extraction is a crucial technique in Natural Language Processing (NLP) that automatically identifies the most important words or phrases in a document. These keywords help summarize content, improve searchability, and enhance text analysis. However, traditional keyword extraction methods have limitations, such as lacking contextual understanding or failing in short documents.
To overcome these challenges, we introduce TRISUM, a hybrid graph-based keyword extraction algorithm that combines the strengths of multiple techniques to improve accuracy and relevance.
Overview of Keyword Extraction in NLP
Keyword extraction is widely used in:
- Search Engines – Identifying relevant content based on user queries.
- Academic Research – Summarizing research papers by extracting key concepts.
- Content Optimization – Improving SEO rankings by using high-impact keywords.
- Writing Assistance – Analyzing student essays to ensure topic relevance.
For instance, if a research paper discusses climate change, a good keyword extraction method should highlight words like global warming, carbon footprint, renewable energy, and sustainability while ignoring less relevant terms.
Importance of Accurate Keyword Extraction
A high-quality keyword extraction algorithm is important because:
✅ Enhances Information Retrieval – Helps search engines and databases retrieve relevant content efficiently.
✅ Improves Content Summarization – Extracts key points from long documents.
✅ Optimizes SEO – Identifies high-value keywords for better ranking.
✅ Supports Writing Analysis – Ensures that an essay aligns with its given topic.
If keyword extraction is inaccurate, it may miss crucial terms or extract irrelevant words, reducing its effectiveness.
Limitations of Existing Methods
Several existing keyword extraction techniques come with drawbacks:
1. TF-IDF (Term Frequency-Inverse Document Frequency)
- ✅ Simple & fast for basic keyword extraction.
- ❌ Lacks contextual understanding – It only counts word frequency, ignoring meaning.
- ❌ Fails in short texts – Cannot effectively extract keywords from small documents.
2. YAKE (Yet Another Keyword Extractor)
- ✅ Language-independent & works well on short texts.
- ❌ Limited semantic understanding – Cannot differentiate between words with multiple meanings.
3. KeyBERT (BERT-based Keyword Extraction)
- ✅ Understands word relationships and context.
- ❌ Requires high computational power (GPU).
- ❌ Slower on large datasets.
Since no single method is perfect, we need a hybrid approach that combines multiple techniques for improved accuracy.
Introduction to TRISUM
TRISUM is a hybrid keyword extraction algorithm that improves accuracy by combining three graph-based ranking techniques:



