![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)
















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)




































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)








































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)









![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)































































































































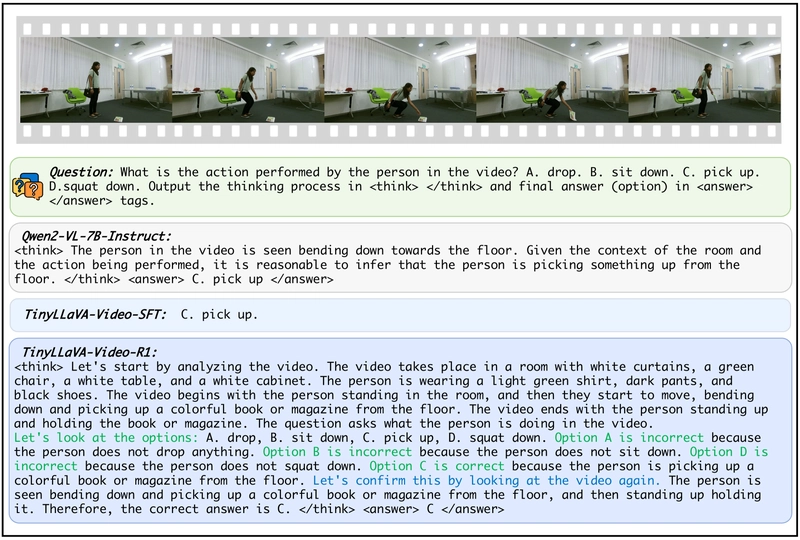
Transaction Message Header: An ELI5 Into the Transaction Message Header Semantics
A transaction is a set of signatures of serialized messages signed by the first key of the Message’s account key. The message in a transaction is a structure containing a header, account_keys, recent_blockhash and instructions. The header contains the MessageHeader which describes the organization of the Message’s account keys. Every instruction specifies which accounts it may reference, or otherwise requires specific permissions of. Those specifications are: whether the account is read-only, or read-write; and whether the account must have signed the transaction containing the instruction. Whereas individual Instructions contain a list of all accounts they may access, along with their required permissions, a Message contains a single shared flat list of all accounts required by all instructions in a transaction. When building a Message, this flat list is created and Instructions are converted to a set of CompiledInstructions. Those CompiledInstructions are then reference by index the accounts they require in the single shared account list. The shared account list is ordered by the permissions required of the accounts: accounts that are writable and signers accounts that are read-only and signers accounts that are writable and not signers accounts that are read-only and not signers Given this ordering, the fields of MessageHeader describe which accounts in a transaction require which permissions. When multiple transactions access the same read-only accounts, the runtime may process them in parallel, in a single PoH entry. Transactions that access the same read-write accounts are processed sequentially. Message Header The MessageHeader describes the organization of a transaction Message’s account keys. It’s structure is defined as: pub struct MessageHeader { pub num_required_signatures: u8, pub num_readonly_signed_accounts: u8, pub num_readonly_unsigned_accounts: u8, } Where num_required_signatures represents the number of signatures required for this message to be valid, num_readonly_signed_accounts represents the last num_readonly_signed_accounts that are read-only signers, while num_readonly_unsigned_accounts represents the last num_readonly_unsigned_accounts that are read-only non-signers.. By reading these three values in the MessageHeader and the account_keys array in the Message, the runtime can by index, deterministically: Know which accounts are signer vs non-signers Know which accounts are read-only vs writable Now consider a reverse scenario where instead of the number of read-only signatures, we have a number of writable signers? That is, simply flipping the logic to define the MessageHeader like this: pub struct FlippedMessageHeader { pub num_required_signatures: u8, pub num_writable_signed_accounts: u8, pub num_writable_unsigned_accounts: u8, } This would also work in theory but compared to the original design has some performance implications. From the flipped logic of message header, the runtime would have to infer a couple of things: The first num_writable_signed_accounts in account_keys[0..num_required_signatures] are writable. The rest are read-only signers. The first num_writable_unsigned_accounts in the rest are writable non-signers. The rest are read-only non-signers. However with this approach, we lose the suffix parsing behavior in the original design. With the original design, Read-only accounts are at the end of their respective signer/non-signer group which makes range slicing easy: account_keys[0..n] -> all signers account_keys[n..] -> all non-signers Within each, the tail can be used to mark "read-onlys" With flipped logic: Writable accounts are at the front, so we would need to slice the beginning of each group and then infer "read-onlys" as a suffix after skipping "writables" (prefix-based parsing). Consider this analogy further. Say we have account_keys= [A, B, C, D, E, F], and the header: num_required_signatures = 3 num_readonly_signed_accounts = 1 num_readonly_unsigned_accounts = 1 From this example, Signers: [A, B, C] Last one of them (C) -> read-only signer First two of them (A, B) -> writable signers Non-signers: [D, E, F] Last one of them (F) -> read-only non-signer First two of them (D, E) -> writable non-signers Slicing can be done cleanly and easily based on suffix counts like this: writable_signers = account_keys[0..(3 - 1)] = [A, B] readonly_signers = account_keys[(3 - 1)..3] = [C] writable_non_signers = account_keys[3..(6 - 1)] = [D, E] readonly_non_signers = account_keys[5..6] = [F] Now if we go along with the flipped logic and assume the header stored: num_required_signatures = 3 num_writable_signed_accounts = 2 num_writable_unsigned_accounts = 2 To find read-onlys, now we have to compute: First two in the signer section -> writable The rest -> read-only First two in the non-signer section -> writable The rest -> read-only So for read-only accounts, you have to offset forward rather

A transaction is a set of signatures of serialized messages signed by the first key of the Message’s account key.
The message in a transaction is a structure containing a header, account_keys, recent_blockhash and instructions. The header contains the MessageHeader which describes the organization of the Message’s account keys.
Every instruction specifies which accounts it may reference, or otherwise requires specific permissions of. Those specifications are: whether the account is read-only, or read-write; and whether the account must have signed the transaction containing the instruction.
Whereas individual Instructions contain a list of all accounts they may access, along with their required permissions, a Message contains a single shared flat list of all accounts required by all instructions in a transaction. When building a Message, this flat list is created and Instructions are converted to a set of CompiledInstructions. Those CompiledInstructions are then reference by index the accounts they require in the single shared account list.
The shared account list is ordered by the permissions required of the accounts:
- accounts that are writable and signers
- accounts that are read-only and signers
- accounts that are writable and not signers
- accounts that are read-only and not signers
Given this ordering, the fields of MessageHeader describe which accounts in a transaction require which permissions.
When multiple transactions access the same read-only accounts, the runtime may process them in parallel, in a single PoH entry. Transactions that access the same read-write accounts are processed sequentially.
Message Header
The MessageHeader describes the organization of a transaction Message’s account keys. It’s structure is defined as:
pub struct MessageHeader {
pub num_required_signatures: u8,
pub num_readonly_signed_accounts: u8,
pub num_readonly_unsigned_accounts: u8,
}
Where num_required_signatures represents the number of signatures required for this message to be valid, num_readonly_signed_accounts represents the last num_readonly_signed_accounts that are read-only signers, while num_readonly_unsigned_accounts represents the last num_readonly_unsigned_accounts that are read-only non-signers..
By reading these three values in the MessageHeader and the account_keys array in the Message, the runtime can by index, deterministically:
- Know which accounts are signer vs non-signers
- Know which accounts are read-only vs writable
Now consider a reverse scenario where instead of the number of read-only signatures, we have a number of writable signers? That is, simply flipping the logic to define the MessageHeader like this:
pub struct FlippedMessageHeader {
pub num_required_signatures: u8,
pub num_writable_signed_accounts: u8,
pub num_writable_unsigned_accounts: u8,
}
This would also work in theory but compared to the original design has some performance implications.
From the flipped logic of message header, the runtime would have to infer a couple of things:
- The first num_writable_signed_accounts in account_keys[0..num_required_signatures] are writable.
- The rest are read-only signers.
- The first num_writable_unsigned_accounts in the rest are writable non-signers.
- The rest are read-only non-signers.
However with this approach, we lose the suffix parsing behavior in the original design.
With the original design, Read-only accounts are at the end of their respective signer/non-signer group which makes range slicing easy:
account_keys[0..n] -> all signers
account_keys[n..] -> all non-signers
Within each, the tail can be used to mark "read-onlys"
With flipped logic:
Writable accounts are at the front, so we would need to slice the beginning of each group and then infer "read-onlys" as a suffix after skipping "writables" (prefix-based parsing).
Consider this analogy further. Say we have account_keys= [A, B, C, D, E, F], and the header:
num_required_signatures = 3
num_readonly_signed_accounts = 1
num_readonly_unsigned_accounts = 1
From this example,
Signers: [A, B, C]
Last one of them (C) -> read-only signer
First two of them (A, B) -> writable signers
Non-signers: [D, E, F]
Last one of them (F) -> read-only non-signer
First two of them (D, E) -> writable non-signers
Slicing can be done cleanly and easily based on suffix counts like this:
writable_signers = account_keys[0..(3 - 1)] = [A, B]
readonly_signers = account_keys[(3 - 1)..3] = [C]
writable_non_signers = account_keys[3..(6 - 1)] = [D, E]
readonly_non_signers = account_keys[5..6] = [F]
Now if we go along with the flipped logic and assume the header stored:
num_required_signatures = 3
num_writable_signed_accounts = 2
num_writable_unsigned_accounts = 2
To find read-onlys, now we have to compute:
First two in the signer section -> writable
The rest -> read-only
First two in the non-signer section -> writable
The rest -> read-only
So for read-only accounts, you have to offset forward rather than slice from the end.
This means we can’t just slice_from_end(count) anymore and we now need to compute and track forward ranges like:
readonly_signers = account_keys[num_writable_signed_accounts..num_required_signatures]
Which gets more awkward if counts don’t line up cleanly or if you add more categories.
Summary
While it is quite semantically logical to flip the logic in theory, in practice there would be some performance trade-off to that effect. By assuming "writability" by default and counting only the exception, the runtime not only minimizes bytes encoding but also encourages a compact, fast, suffix-parsed, position based inference.
Also with suffix-based parsing (read-only last), we can just slice from the end which is much simpler and cleaner that prefix-based parsing (writable first) where we would need to offset forward which is more difficult.
References
www.anza.xyz
https://dl.acm.org/doi/pdf/10.1145/233551.233555