![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)
























































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)























































































































_roibu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




 CISO’s Core Focus.webp?#)







































































































![M4 MacBook Air Drops to Just $849 - Act Fast! [Lowest Price Ever]](https://www.iclarified.com/images/news/97140/97140/97140-640.jpg)
![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)





























































































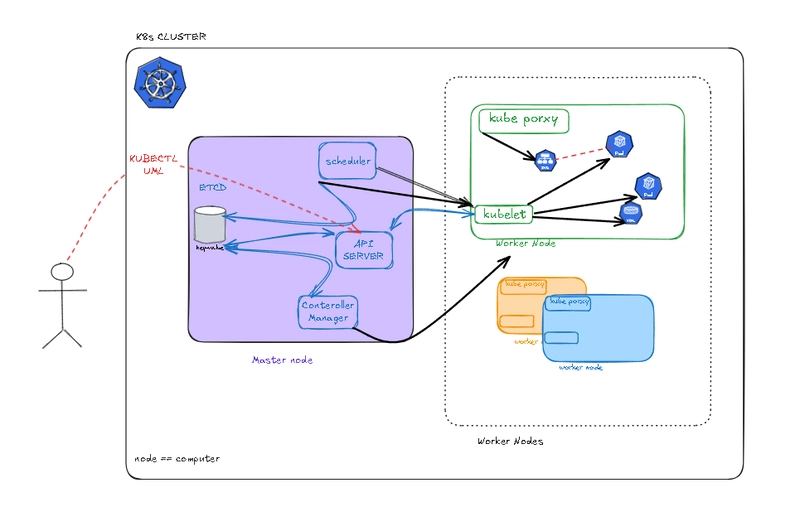
Stop Worrying About Servers: Your Beginner's Guide to AWS Lambda & Serverless
Okay, fellow cloud navigators! Let's dive into one of the most foundational and transformative services in the AWS ecosystem: Lambda. As someone who spends their days architecting, writing about, and teaching AWS, I've seen Lambda change the game for countless developers and organizations. But I also know that first step into the "serverless" world can feel a bit daunting. No worries! Grab your favorite beverage, settle in, and let's demystify AWS Lambda together. We'll break it down piece by piece, moving from "What is this thing?" to "Okay, I can actually use this!" Intro: The Late-Night Server Patching Blues Remember those late nights spent SSH'd into a server, running apt-get update or wrestling with OS patches? Or maybe you've felt the sting of paying for an EC2 instance that sits idle 95% of the time, just waiting for that occasional task to run? We've all been there. Managing infrastructure – the patching, scaling, availability – is crucial, but let's be honest, it's often undifferentiated heavy lifting. It distracts from what most of us really want to do: write code that solves problems and delivers value. What if you could just... upload your code and have it run automatically when needed, scaling effortlessly without you ever thinking about a server again? That's the core promise of serverless computing, and AWS Lambda is the engine driving it on AWS. Why It Matters: The Serverless Shift Serverless isn't just a buzzword; it's a fundamental shift in how we build and deploy applications. It represents: Reduced Operational Overhead: No servers to provision or manage. AWS handles the infrastructure, OS, patching, and scaling. Pay-for-Value: You pay only for the compute time you consume – down to the millisecond – plus the number of requests. No more paying for idle servers. Automatic Scaling: Lambda scales automatically based on the number of incoming requests, from a handful to thousands per second. Faster Development Cycles: Developers can focus purely on writing application logic, leading to quicker iteration and deployment. Understanding Lambda is becoming essential for modern cloud developers and architects. It unlocks powerful patterns for building APIs, processing data, automating tasks, and much more, often at a lower cost and with less effort than traditional server-based approaches. The Concept in Simple Terms: Lambda as the "Short-Order Cook" Imagine you own a restaurant, but instead of hiring full-time cooks who stand around waiting during quiet periods (like servers sitting idle), you employ "Short-Order Cooks" on demand. An Order Arrives (Event Trigger): A customer places an order (e.g., someone uploads a file to S3, calls an API endpoint, a message arrives in a queue). Cook Gets to Work (Lambda Invocation): A Short-Order Cook instantly appears, equipped with the specific recipe (your function code) needed for that order. They have all the necessary utensils and ingredients ready (the execution environment). Prepares the Dish (Code Execution): The cook follows the recipe precisely (executes your code) to prepare the dish (process the data, generate a response, etc.). Dish Served (Function Response/Completion): The dish is served (the result is returned or the task is completed). Cook Vanishes (Environment Cleans Up): The Short-Order Cook immediately disappears, and you only pay them for the exact time they spent actively cooking that specific dish. In this analogy: You: The application owner/developer. Short-Order Cook: The Lambda function execution environment. Recipe: Your function code. Order: The event trigger (S3 upload, API call, etc.). Cooking Time: The function execution duration. Paying only when cooking: The pay-per-use pricing model. AWS Lambda lets you run your code (the recipe) in response to events (orders) without managing the underlying kitchen (servers). AWS handles finding an available cook (provisioning compute) the moment an order comes in. Deeper Dive: How Lambda Actually Works Let's peel back the layers slightly beyond the analogy: Function Code: This is the actual code you write. You can write Lambda functions in popular languages like Node.js, Python, Java, Go, Ruby, C#, and even bring your own custom runtime. You package this code (and any dependencies) into a deployment package (usually a .zip file). Runtime: This is the environment where your code runs. It includes the operating system, the language interpreter/VM, and necessary AWS libraries. You select the runtime when creating your function (e.g., python3.9, nodejs18.x). Triggers (Event Sources): These are the AWS services or custom applications that invoke your Lambda function. Common triggers include: API Gateway: For creating serverless APIs. S3: Triggering on object creation/deletion. DynamoDB Streams: Processing changes in a DynamoDB table. SQS: Processing messages from a queue. SNS: Reacting t

Okay, fellow cloud navigators! Let's dive into one of the most foundational and transformative services in the AWS ecosystem: Lambda. As someone who spends their days architecting, writing about, and teaching AWS, I've seen Lambda change the game for countless developers and organizations. But I also know that first step into the "serverless" world can feel a bit daunting.
No worries! Grab your favorite beverage, settle in, and let's demystify AWS Lambda together. We'll break it down piece by piece, moving from "What is this thing?" to "Okay, I can actually use this!"
Intro: The Late-Night Server Patching Blues
Remember those late nights spent SSH'd into a server, running apt-get update or wrestling with OS patches? Or maybe you've felt the sting of paying for an EC2 instance that sits idle 95% of the time, just waiting for that occasional task to run? We've all been there. Managing infrastructure – the patching, scaling, availability – is crucial, but let's be honest, it's often undifferentiated heavy lifting. It distracts from what most of us really want to do: write code that solves problems and delivers value.
What if you could just... upload your code and have it run automatically when needed, scaling effortlessly without you ever thinking about a server again? That's the core promise of serverless computing, and AWS Lambda is the engine driving it on AWS.
Why It Matters: The Serverless Shift
Serverless isn't just a buzzword; it's a fundamental shift in how we build and deploy applications. It represents:
- Reduced Operational Overhead: No servers to provision or manage. AWS handles the infrastructure, OS, patching, and scaling.
- Pay-for-Value: You pay only for the compute time you consume – down to the millisecond – plus the number of requests. No more paying for idle servers.
- Automatic Scaling: Lambda scales automatically based on the number of incoming requests, from a handful to thousands per second.
- Faster Development Cycles: Developers can focus purely on writing application logic, leading to quicker iteration and deployment.
Understanding Lambda is becoming essential for modern cloud developers and architects. It unlocks powerful patterns for building APIs, processing data, automating tasks, and much more, often at a lower cost and with less effort than traditional server-based approaches.
The Concept in Simple Terms: Lambda as the "Short-Order Cook"
Imagine you own a restaurant, but instead of hiring full-time cooks who stand around waiting during quiet periods (like servers sitting idle), you employ "Short-Order Cooks" on demand.
- An Order Arrives (Event Trigger): A customer places an order (e.g., someone uploads a file to S3, calls an API endpoint, a message arrives in a queue).
- Cook Gets to Work (Lambda Invocation): A Short-Order Cook instantly appears, equipped with the specific recipe (your function code) needed for that order. They have all the necessary utensils and ingredients ready (the execution environment).
- Prepares the Dish (Code Execution): The cook follows the recipe precisely (executes your code) to prepare the dish (process the data, generate a response, etc.).
- Dish Served (Function Response/Completion): The dish is served (the result is returned or the task is completed).
- Cook Vanishes (Environment Cleans Up): The Short-Order Cook immediately disappears, and you only pay them for the exact time they spent actively cooking that specific dish.
In this analogy:
- You: The application owner/developer.
- Short-Order Cook: The Lambda function execution environment.
- Recipe: Your function code.
- Order: The event trigger (S3 upload, API call, etc.).
- Cooking Time: The function execution duration.
- Paying only when cooking: The pay-per-use pricing model.
AWS Lambda lets you run your code (the recipe) in response to events (orders) without managing the underlying kitchen (servers). AWS handles finding an available cook (provisioning compute) the moment an order comes in.
Deeper Dive: How Lambda Actually Works
Let's peel back the layers slightly beyond the analogy:
- Function Code: This is the actual code you write. You can write Lambda functions in popular languages like Node.js, Python, Java, Go, Ruby, C#, and even bring your own custom runtime. You package this code (and any dependencies) into a deployment package (usually a .zip file).
- Runtime: This is the environment where your code runs. It includes the operating system, the language interpreter/VM, and necessary AWS libraries. You select the runtime when creating your function (e.g.,
python3.9,nodejs18.x). - Triggers (Event Sources): These are the AWS services or custom applications that invoke your Lambda function. Common triggers include:
- API Gateway: For creating serverless APIs.
- S3: Triggering on object creation/deletion.
- DynamoDB Streams: Processing changes in a DynamoDB table.
- SQS: Processing messages from a queue.
- SNS: Reacting to notifications.
- CloudWatch Events/EventBridge: Running functions on a schedule or in response to AWS events.
- Direct Invocation: Calling the Lambda function directly using the AWS SDK or CLI.
- Execution Environment: When triggered, AWS securely provisions a temporary, isolated container with the necessary memory and CPU resources you configure. It downloads your code, sets up the runtime, and then executes your handler function.
- Handler Function: This is the specific method/function within your code that Lambda executes when invoked. It typically receives event data (like details about the S3 object uploaded or the API request) and a context object (with information about the invocation).
- IAM Role (Execution Role): Crucially, each Lambda function has an associated IAM role. This role grants the function permission to interact with other AWS services (e.g., permission to read from S3 or write to DynamoDB). This follows the principle of least privilege.
- Configuration: You configure settings like memory allocation (which also influences CPU power), timeout duration (how long a function can run before being stopped), environment variables, and network settings (like VPC access).
- Pricing: Primarily based on two factors:
- Number of Requests: A small charge per million requests.
- Duration: Charged per gigabyte-second (GB-s) of compute time used, measured in milliseconds. Generous free tier included!
Practical Example: Serverless Image Thumbnail Generation
Let's solidify this with a classic use case: automatically creating thumbnail images whenever a full-size image is uploaded to an S3 bucket.
- The Trigger: An S3 bucket is configured to send an "ObjectCreated" event whenever a new image file (e.g.,
my-photo.jpg) is uploaded to a specific prefix (like/originals). - The Lambda Function: A Lambda function (e.g., written in Python using the Pillow library) is created with the S3 event as its trigger. Its IAM role grants it permission to read from the
/originalsprefix in the source bucket and write to a/thumbnailsprefix in the same or a different S3 bucket. - The Event: A user uploads
originals/my-photo.jpgto the source S3 bucket. - Invocation: S3 automatically triggers the Lambda function, passing event data containing the bucket name (
your-source-bucket) and object key (originals/my-photo.jpg). - Execution:
- Lambda provisions an environment.
- The Python code starts.
- It reads the event data to get the bucket and key.
- It uses the AWS SDK (Boto3 for Python) to download
originals/my-photo.jpgfrom S3 to the Lambda's temporary storage. - It uses the Pillow library to resize the image into a thumbnail.
- It uses the AWS SDK again to upload the generated thumbnail to
thumbnails/my-photo-thumb.jpgin the target S3 bucket.
- Completion: The function finishes, logs any output to CloudWatch Logs, and the execution environment is frozen or terminated. The thumbnail is now available!
Minimal Python Handler Structure:
# Example Python Lambda handler structure (Conceptual)
# Needs Pillow library & appropriate IAM permissions
import boto3
# from PIL import Image # Would need this library packaged
import os
import logging
# Configure logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
s3_client = boto3.client('s3')
TARGET_BUCKET = os.environ.get('TARGET_BUCKET_NAME') # Get target bucket from env var
def lambda_handler(event, context):
"""
Handles S3 Put events to resize an image.
"""
logger.info("Received event: %s", event)
try:
# 1. Get bucket and key from the event
record = event['Records'][0]
source_bucket = record['s3']['bucket']['name']
source_key = record['s3']['object']['key']
# Simple validation - ensure it's from the expected path if needed
if not source_key.startswith('originals/'):
logger.warning("Object not in originals/ path, skipping.")
return {'status': 'skipped'}
# Prevent infinite loops if source and target are same bucket!
if 'thumbnail' in source_key:
logger.warning("Object appears to be a thumbnail already, skipping.")
return {'status': 'skipped'}
# Define target key
base_filename = os.path.basename(source_key)
target_key = f"thumbnails/{base_filename}-thumb.jpg" # Example target naming
logger.info(f"Processing {source_key} from bucket {source_bucket}.")
logger.info(f"Target bucket: {TARGET_BUCKET}, Target key: {target_key}")
# --- Image Resizing Logic Would Go Here ---
# 2. Download image from S3 to /tmp (Lambda's writable temp space)
# download_path = f'/tmp/{base_filename}'
# s3_client.download_file(source_bucket, source_key, download_path)
# logger.info(f"Downloaded {source_key} to {download_path}")
# 3. Resize image using Pillow (requires Pillow library in deployment package)
# with Image.open(download_path) as image:
# image.thumbnail((128, 128)) # Example size
# thumbnail_path = f'/tmp/resized-{base_filename}'
# image.save(thumbnail_path, 'JPEG')
# logger.info(f"Resized image saved to {thumbnail_path}")
# 4. Upload resized image to target S3 bucket
# s3_client.upload_file(thumbnail_path, TARGET_BUCKET, target_key)
# logger.info(f"Uploaded thumbnail to s3://{TARGET_BUCKET}/{target_key}")
# --- Placeholder Success ---
logger.info("Placeholder: Image processing logic would execute here.")
return {
'statusCode': 200,
'body': f'Successfully processed {source_key} and would upload to {target_key}'
}
except Exception as e:
logger.error("Error processing S3 event: %s", e)
# You might want more specific error handling/reporting
raise e # Re-throwing tells Lambda the invocation failed
(Note: The actual image resizing code using Pillow is commented out for brevity and because it requires packaging the library, which is beyond a Level 100 intro. This structure shows the flow.)
Common Mistakes or Misunderstandings for Beginners
- Ignoring Cold Starts: When a function hasn't been used recently, Lambda needs to provision a new environment, which takes time (from <100ms to several seconds depending on code size, language, VPC config). This delay is a "cold start." For latency-sensitive apps (like APIs), understand this and consider Provisioned Concurrency (an advanced feature) if needed. For background tasks, it's often acceptable.
- Assuming Statelessness means No State Ever: Lambda execution environments are reused for subsequent invocations if traffic is steady (a "warm start"). You can cache data or reuse database connections outside your handler function in the global scope. However, you cannot rely on state persisting between invocations – always assume each invocation might be fresh. Don't store critical state in function memory. Use DynamoDB, S3, or other services for durable state.
- Forgetting about Timeouts: Functions have a maximum execution time (default 3 seconds, max 15 minutes). Long-running tasks might hit this limit. Design functions to be focused and quick, or break down long tasks into smaller steps (e.g., using Step Functions).
- Neglecting Permissions (IAM): Functions often fail because their Execution Role doesn't have permission to access the needed AWS services (like reading from S3 or writing to CloudWatch Logs). Always start with minimal permissions and add only what's necessary. Check CloudWatch Logs for permission errors!
- Not Logging Enough (or Too Much):
print()statements (in Python) orconsole.log()(in Node.js) go to CloudWatch Logs. Good logging is essential for debugging. However, excessive logging can increase costs and make finding errors harder. Log key information and errors effectively.
Pro Tips & Hidden Features (Beginner+ Level)
- Use Environment Variables: Store configuration details (like database names, API keys, target bucket names) in Lambda Environment Variables, not hardcoded in your function. This makes your code reusable across different environments (dev, staging, prod).
- Leverage the AWS Free Tier: Lambda has a generous permanent free tier (1 million free requests per month and 400,000 GB-seconds of compute time per month). Perfect for experimenting and small applications!
- Monitor with CloudWatch: Lambda automatically integrates with CloudWatch Logs (for function output) and CloudWatch Metrics (for invocations, duration, errors, throttling). Keep an eye on these! Set up CloudWatch Alarms for error spikes or high durations.
- Keep Deployment Packages Small: Smaller zip files mean faster cold starts. Avoid including unnecessary libraries. For larger dependencies, explore Lambda Layers (a way to share common code/libraries across functions).
- Consider Infrastructure as Code (IaC): While you can use the console to start, managing serverless applications quickly becomes easier using tools like AWS SAM (Serverless Application Model) or the Serverless Framework. They let you define your functions, triggers, and permissions in code (YAML/JSON), making deployments repeatable and version-controlled.
-
Basic CLI Invocation: Test your function quickly from your terminal:
# Invoke a function named 'my-function' with an empty payload aws lambda invoke --function-name my-function output.json # Invoke with a simple JSON payload aws lambda invoke --function-name my-function --payload '{"key": "value"}' output.json # View the output file cat output.json # You can also check CloudWatch logs for detailed output
Final Thoughts + Call to Action
AWS Lambda is a cornerstone of modern cloud development. By abstracting away the underlying servers, it empowers developers to focus on building features faster, scale automatically, and often reduce costs significantly. The "Short-Order Cook" analogy helps grasp the event-driven, pay-per-use nature that makes it so powerful.
While we've covered the Level 100 basics today, the serverless world is vast and exciting.
Your Turn:
- Have you tried AWS Lambda? What was your first "aha!" moment?
- What use cases are you considering for serverless?
- Log in to the AWS Management Console and try creating a simple "Hello World" Lambda function! The free tier makes it easy to experiment.
Share your thoughts, questions, or experiences in the comments below! Let's learn together. And if you found this helpful, please share it with others who might be starting their serverless journey.