![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)












































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)







































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
































































































































SmolVLM: Tiny AI Model Beats Giants in Visual Reasoning!
This is a Plain English Papers summary of a research paper called SmolVLM: Tiny AI Model Beats Giants in Visual Reasoning!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview SmolVLM creates efficient vision-language models that require less computational power These models range from 800M to 1.3B parameters but perform like larger 7-34B models Key innovation is optimizing compute allocation between vision and language components Models excel at visual reasoning while being small enough for resource-constrained devices Achieves state-of-the-art performance compared to similar-sized multimodal models Plain English Explanation SmolVLM represents a breakthrough in making AI models that can understand both images and text while using far fewer resources. Think of traditional vision-language models like luxury... Click here to read the full summary of this paper
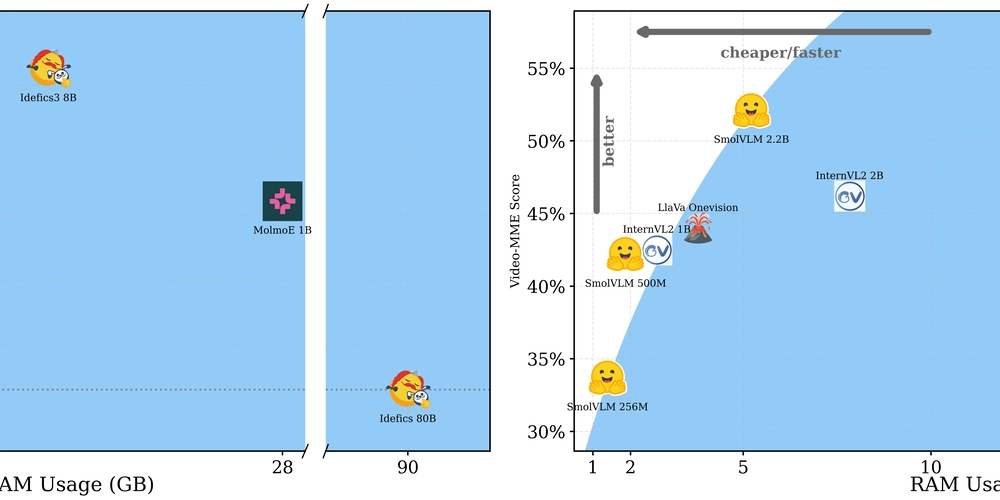
This is a Plain English Papers summary of a research paper called SmolVLM: Tiny AI Model Beats Giants in Visual Reasoning!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- SmolVLM creates efficient vision-language models that require less computational power
- These models range from 800M to 1.3B parameters but perform like larger 7-34B models
- Key innovation is optimizing compute allocation between vision and language components
- Models excel at visual reasoning while being small enough for resource-constrained devices
- Achieves state-of-the-art performance compared to similar-sized multimodal models
Plain English Explanation
SmolVLM represents a breakthrough in making AI models that can understand both images and text while using far fewer resources. Think of traditional vision-language models like luxury...