









































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)


























































































































































![BPMN-procesmodellering [closed]](https://i.sstatic.net/l7l8q49F.png)



























































































-All-will-be-revealed-00-35-05.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
-All-will-be-revealed-00-17-36.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)














































































































![What iPhone 17 model are you most excited to see? [Poll]](https://9to5mac.com/wp-content/uploads/sites/6/2025/04/iphone-17-pro-sky-blue.jpg?quality=82&strip=all&w=290&h=145&crop=1)














![Hands-On With 'iPhone 17 Air' Dummy Reveals 'Scary Thin' Design [Video]](https://www.iclarified.com/images/news/97100/97100/97100-640.jpg)
![Mike Rockwell is Overhauling Siri's Leadership Team [Report]](https://www.iclarified.com/images/news/97096/97096/97096-640.jpg)
![Instagram Releases 'Edits' Video Creation App [Download]](https://www.iclarified.com/images/news/97097/97097/97097-640.jpg)
![Inside Netflix's Rebuild of the Amsterdam Apple Store for 'iHostage' [Video]](https://www.iclarified.com/images/news/97095/97095/97095-640.jpg)


















































































































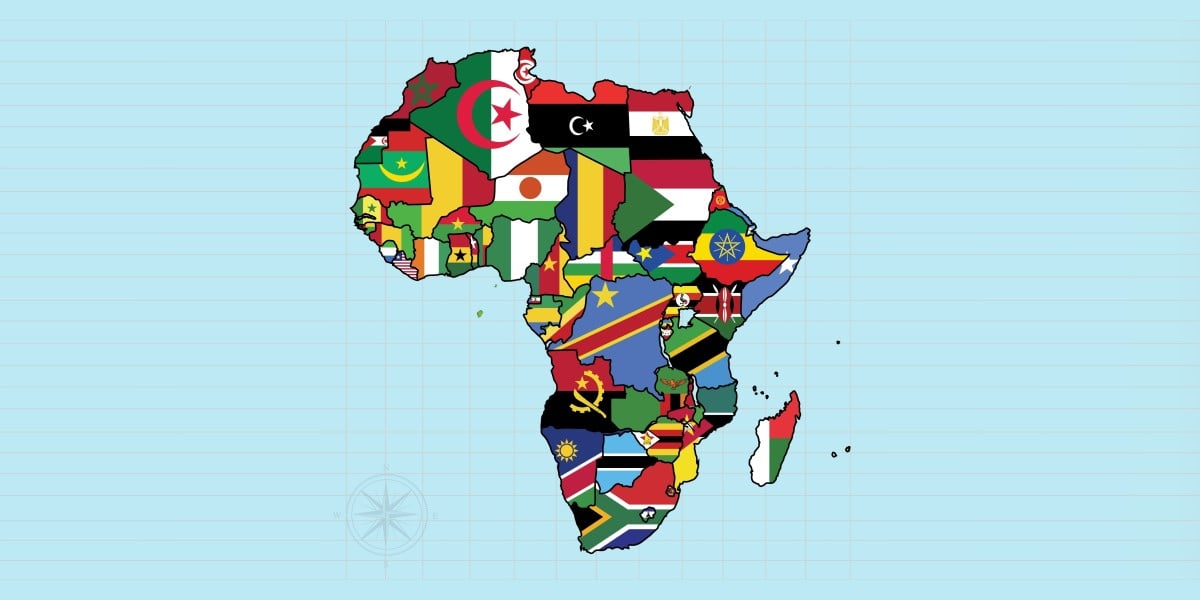
RAG for a beginner by ChatGPT
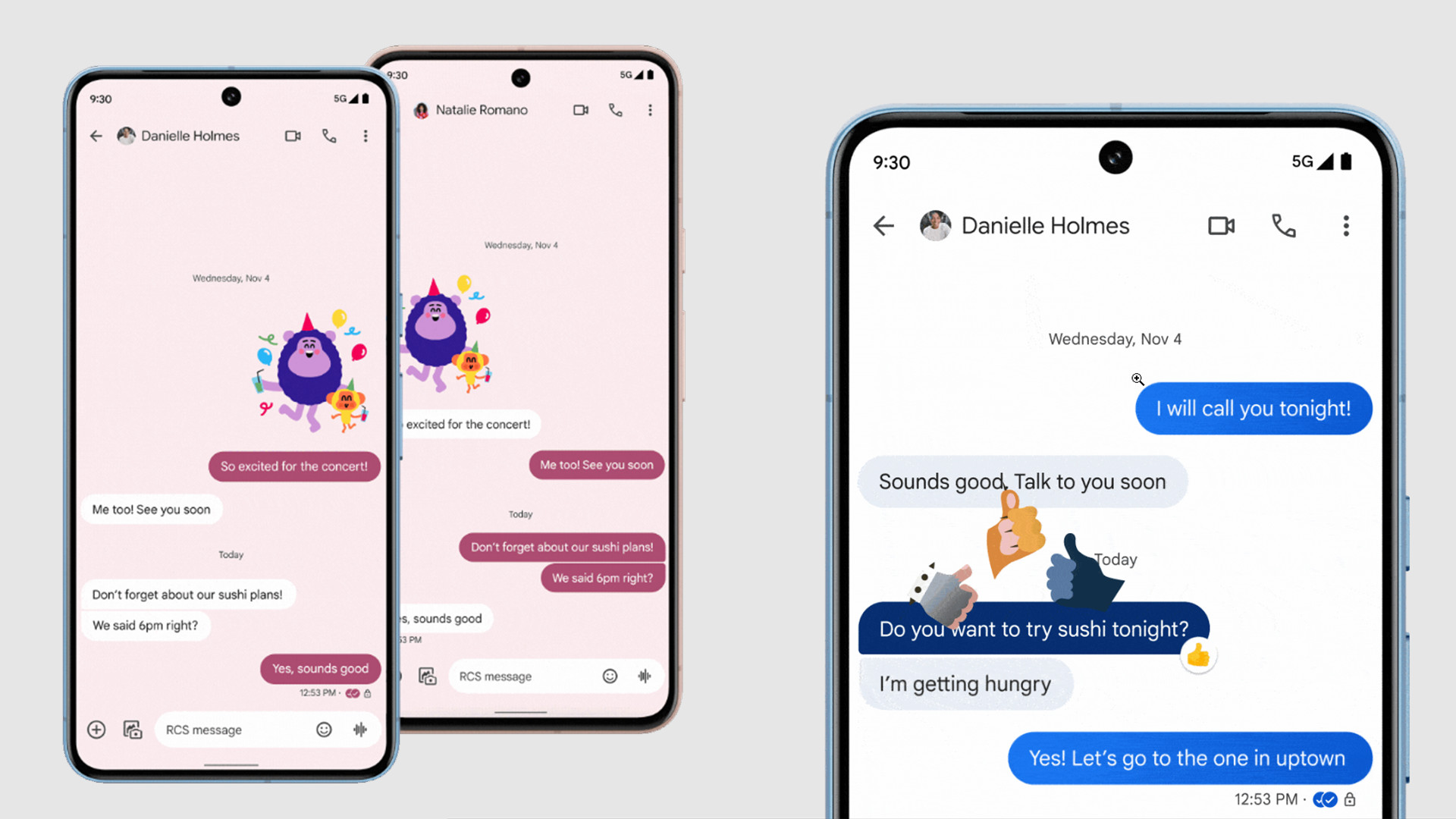
RAG is Retrieval Augmented Generation. It is an AI-technique that uses an integrated knowledge base for the information retrieval. The retrieved information in turn is used by the LLM as a context to generate the response for the user input. No tricks behind the title of this story other than just what I did. As a beginner, I did not know where to start, so I started exploring some options to learn about RAG. I came across langchain, faiss, langflow and other such libraries. Yet I wasn’t able to tie all the ends, so I did seek the knowledge of ChatGPT :D I got the response of the entire code to implement RAG using open-source libraries and then passing the context to LLM (with Groq API for llama-3–70b). Let us go through the code and understand it. Folder Structure rag_groq/ │ ├── main.py # Entry point ├── ingest.py # Load & embed PDF content ├── query.py # Ask questions using Groq API ├── config.py # Configuration (Groq key, model, etc.) ├── sample.pdf # Your test document └── requirements.txt # Required Python libraries config.py # config.py GROQ_API_KEY = "gsk_*" GROQ_MODEL = "llama3-70b-8192" # or another model hosted on Groq EMBEDDING_MODEL = "sentence-transformers/all-MiniLM-L6-v2" VECTOR_DB_PATH = "vector_store" Groq API key is required to access the llama-3 model to infer. We define the embedding model to convert the document content into embeddings and then store the chunks. We store the index for the chunks using faiss and it will be saved to the vector db path defined here. main.py from ingest import build_vector_store from query import query_pdf if __name__ == "__main__": print("

RAG is Retrieval Augmented Generation. It is an AI-technique that uses an integrated knowledge base for the information retrieval. The retrieved information in turn is used by the LLM as a context to generate the response for the user input.
No tricks behind the title of this story other than just what I did. As a beginner, I did not know where to start, so I started exploring some options to learn about RAG. I came across langchain, faiss, langflow and other such libraries. Yet I wasn’t able to tie all the ends, so I did seek the knowledge of ChatGPT :D
I got the response of the entire code to implement RAG using open-source libraries and then passing the context to LLM (with Groq API for llama-3–70b). Let us go through the code and understand it.
Folder Structure
rag_groq/
│
├── main.py # Entry point
├── ingest.py # Load & embed PDF content
├── query.py # Ask questions using Groq API
├── config.py # Configuration (Groq key, model, etc.)
├── sample.pdf # Your test document
└── requirements.txt # Required Python libraries
config.py
# config.py
GROQ_API_KEY = "gsk_*"
GROQ_MODEL = "llama3-70b-8192" # or another model hosted on Groq
EMBEDDING_MODEL = "sentence-transformers/all-MiniLM-L6-v2"
VECTOR_DB_PATH = "vector_store"
Groq API key is required to access the llama-3 model to infer. We define the embedding model to convert the document content into embeddings and then store the chunks. We store the index for the chunks using faiss and it will be saved to the vector db path defined here.
main.py
from ingest import build_vector_store
from query import query_pdf
if __name__ == "__main__":
print(" 

