











































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)
























































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)


























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)






























































































































Organisation of Data Flows
Overview Programmes are data transformers. We give the programme a task: we input initial data and expect to get some result after its transformation. Complex programmes divide the initial task into smaller tasks. Different parts of the programme - functions, classes, modules - are responsible for different subtasks. For a programme to complete the whole initial task, its parts must work together. They communicate with each other with the help of intermediate results of work - also data. The way one part of the programme receives and transmits data to other parts is called data flow and can determine the architectural structure of the whole system. Types of Data Flows In general, data flows can be organised in a huge number of ways, but the two most common in frontend practice are: Unidirectional (one-way). Bidirectional (two-way). Unidirectional Flow In a unidirectional data flow, each part of the programme can either receive data from another part or transmit it. The direction of such a flow does not change. A unidirectional flow can be schematically represented as a water pipe, and a module as a part of the pipe: In such a flow, data ‘flows’ from one module to another, and the output of the previous module becomes the input of the next: Flux / Redux The best known example of an architecture with unidirectional data flow is Flux and, as its implementation, Redux. In Flux, an application consists of 3 main components: Store; Dispatcher; View. The task of a store is similar to the task of an MVC model - it stores data. Changing the data in the store entails changing the view, i.e. redrawing the user interface. Note that store itself does not redraw the interface, it is not its task. Usually, a UI framework, for example, React, reacts to changes of data in the store. The task of the view is to show the data in a user-friendly way, to draw a user interface. When users perform some actions, such as clicking buttons, the view calls an action - a command object that tells what happened. Sometimes Flux has a 4th component, the action creator. It frees the view from the need to know how to create action objects. An action gets into the dispatcher, it distributes this action to all modules that know how to process it. (In Redux, such modules are called reducers.) These modules transform the data into storage. Updating the data causes the view to be redrawn, and the loop closes. This kind of data flow is similar to classic MVC. Bidirectional Flow Data in a bidirectional stream can be transferred between parts of a programme in both directions. This is most commonly used to bind model and view so that updating, for example, text in an input field will immediately update the data in the model - this is called two-way data binding. This ‘cutting corners’ has both pros and cons. Of advantages: Less code because you don't have to write an action and a handler for it. Works like magic if the framework does everything automatically for developers. At a disadvantage: It's harder to debug when double binding is used for something more complicated than updating text in an input field. It works like magic if the framework does everything automatically. Reactivity Frameworks that use bidirectional binding are often reactive - that is, they apply changes instantly not only to the UI, but also to computed data. Imagine we are using Excel. Let's write numerical values in two cells and a function to calculate their sum in the next cell. If we now change the value of the first cell, the value of the sum will be recalculated automatically. This automatic change of value in the third cell is the reactivity. It seems to be no different from simple double binding, but there is a difference. Let's imagine that we are writing code that should do the same thing: function sum(a, b) { return a + b } let a1 = 2 let a2 = 3 let a3 = sum(a1, a2) // 5 If we change the value of a1, the value of a3 will not change: a1 = 22 console.log(a3) // 5 In order for a value to react (to re-act) to a change, we need to restart its counting: a3 = sum(a1, a2) // 25 Frameworks like Vue take care of the reactivity of values. What to Choose There are no strict recommendations for choosing the way of organising data flows. You can take into account how convenient it will be to write code and debug it. For example, in large or complex applications or large teams you want less ‘magic’ to clearly understand what happens and under what conditions - a unidirectional flow can provide this. In small applications, bidirectional flow can save a lot of time because it replaces the same type of code that would have to be written in the case of unidirectional flow. Support ❤️ It took a lot of time and effort to create this material. If you found this article useful or interesting, please support my work wi
Overview
Programmes are data transformers. We give the programme a task: we input initial data and expect to get some result after its transformation.
Complex programmes divide the initial task into smaller tasks. Different parts of the programme - functions, classes, modules - are responsible for different subtasks.
For a programme to complete the whole initial task, its parts must work together. They communicate with each other with the help of intermediate results of work - also data.
The way one part of the programme receives and transmits data to other parts is called data flow and can determine the architectural structure of the whole system.
Types of Data Flows
In general, data flows can be organised in a huge number of ways, but the two most common in frontend practice are:
- Unidirectional (one-way).
- Bidirectional (two-way).
Unidirectional Flow
In a unidirectional data flow, each part of the programme can either receive data from another part or transmit it. The direction of such a flow does not change.
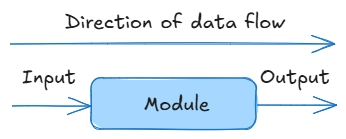
A unidirectional flow can be schematically represented as a water pipe, and a module as a part of the pipe:
In such a flow, data ‘flows’ from one module to another, and the output of the previous module becomes the input of the next:
Flux / Redux
The best known example of an architecture with unidirectional data flow is Flux and, as its implementation, Redux.
In Flux, an application consists of 3 main components:
- Store;
- Dispatcher;
- View.
The task of a store is similar to the task of an MVC model - it stores data. Changing the data in the store entails changing the view, i.e. redrawing the user interface.
Note that store itself does not redraw the interface, it is not its task. Usually, a UI framework, for example, React, reacts to changes of data in the store.
The task of the view is to show the data in a user-friendly way, to draw a user interface.
When users perform some actions, such as clicking buttons, the view calls an action - a command object that tells what happened.
Sometimes Flux has a 4th component, the action creator. It frees the view from the need to know how to create action objects.
An action gets into the dispatcher, it distributes this action to all modules that know how to process it. (In Redux, such modules are called reducers.) These modules transform the data into storage. Updating the data causes the view to be redrawn, and the loop closes.
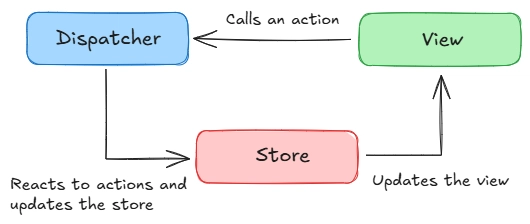
This kind of data flow is similar to classic MVC.
Bidirectional Flow
Data in a bidirectional stream can be transferred between parts of a programme in both directions.
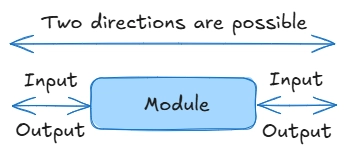
This is most commonly used to bind model and view so that updating, for example, text in an input field will immediately update the data in the model - this is called two-way data binding.

This ‘cutting corners’ has both pros and cons. Of advantages:
- Less code because you don't have to write an action and a handler for it.
- Works like magic if the framework does everything automatically for developers.
At a disadvantage:
- It's harder to debug when double binding is used for something more complicated than updating text in an input field.
- It works like magic if the framework does everything automatically.
Reactivity
Frameworks that use bidirectional binding are often reactive - that is, they apply changes instantly not only to the UI, but also to computed data.
Imagine we are using Excel. Let's write numerical values in two cells and a function to calculate their sum in the next cell.
If we now change the value of the first cell, the value of the sum will be recalculated automatically.
This automatic change of value in the third cell is the reactivity. It seems to be no different from simple double binding, but there is a difference.
Let's imagine that we are writing code that should do the same thing:
function sum(a, b) {
return a + b
}
let a1 = 2
let a2 = 3
let a3 = sum(a1, a2) // 5
If we change the value of a1, the value of a3 will not change:
a1 = 22
console.log(a3) // 5
In order for a value to react (to re-act) to a change, we need to restart its counting:
a3 = sum(a1, a2) // 25
Frameworks like Vue take care of the reactivity of values.
What to Choose
There are no strict recommendations for choosing the way of organising data flows. You can take into account how convenient it will be to write code and debug it.
For example, in large or complex applications or large teams you want less ‘magic’ to clearly understand what happens and under what conditions - a unidirectional flow can provide this.
In small applications, bidirectional flow can save a lot of time because it replaces the same type of code that would have to be written in the case of unidirectional flow.
Support ❤️
It took a lot of time and effort to create this material. If you found this article useful or interesting, please support my work with a small donation. It will help me to continue sharing my knowledge and ideas.
Make a contribution or Subscription to the author's content: Buy me a Coffee, Patreon, PayPal.


