








































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)

































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)












































































































.jpg?#)

































_ArtemisDiana_Alamy.jpg?#)


 (1).webp?#)




































































-xl.jpg)












![Yes, the Gemini icon is now bigger and brighter on Android [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/02/Gemini-on-Galaxy-S25.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)











![Apple Rushes Five Planes of iPhones to US Ahead of New Tariffs [Report]](https://www.iclarified.com/images/news/96967/96967/96967-640.jpg)
![Apple Vision Pro 2 Allegedly in Production Ahead of 2025 Launch [Rumor]](https://www.iclarified.com/images/news/96965/96965/96965-640.jpg)




















































































































Notes from course: Generative AI with Large Language Models - Week 3
Notes from Week 1 Notes from Week 2 Reinforcement Learning from Human Feedback (RLHF) RLHF is essentially a fine-tuning with human feedback which helps to better align models with human preferences and to increase the helpfulness, honesty, and harmlessness of the completions (aka HHH). This further training can also help to decrease the toxicity, often models responses and reduce the generation of incorrect information. In 2020, researchers at OpenAI published a paper that explored the use of fine-tuning with human feedback to train a model to write short summaries of text articles. Here are the results: Reinforcement Learning Reinforcement learning is a type of machine learning in which we train a model to perform a specific action. The training process involves a rewards mechanism where for each action of the model we provide a positive/negative reward, during training the model learns to maximize the reward. For example lets take a look at training a model to play the tic-tac-toe game. The agent is a model or policy acting as a Tic-Tac-Toe player. Its objective is to win the game. The environment is the game board, and the state at any moment, is the current configuration of the board. The action space comprises all the possible positions a player can choose based on the current board state. The agent makes decisions by following a strategy known as the RL policy. Now, as the agent takes actions, it collects rewards based on the actions' effectiveness in progressing towards a win. The goal of reinforcement learning is for the agent to learn the optimal policy for a given environment that maximizes their rewards. This learning process is iterative and involves trial and error. The set of actions and resulting states is called "Rollout". Reinforcement Learning in LLMs We can use the rewards mechanism of reinforcement learning to fine tune an LLM, for each model output we can provide a positive/negative reward, based on how close the output is to human preferences, and the model weights will be update so to maximize the reward. As opposed to the tic-tac-toe game where determining the reward can be computed automatically, obtaining human feedback can be time consuming and expensive. A possible solution is to use an additional model, known as the reward model, to classify the outputs of the LLM and evaluate the degree of alignment with human preferences. We'll see next how to train such a rewards model. Collecting Human Feedback To prepare data for RLHF fine-tuning of an LLM, you first select a capable model, preferably an instruct model, and use it to generate multiple completions for each prompt in a test dataset. The model you choose should have some capability to carry out the task you are interested in, whether this is text summarization, question answering etc. Then, you collect human feedback by having labelers rank these completions based on defined criteria like helpfulness or toxicity, ensuring clear and detailed instructions are provided to the labelers to maintain consistency and quality. The labelers should rank the outputs from best to worst. Finally, the generated completions are transformed into pairs (each completion is paired with all other completions), a score of 1 is given to the completion that was ranked higher. It is important that the preferred completion is put first in the pair. Training the Reward Model The reward model is usually also a language model that is trained using supervised learning methods on the pairwise comparison data that you prepared from the human labelers assessment off the prompts. For a given prompt X, the reward model learns to favor the human-preferred completion. Once the model has been trained on the human rank prompt-completion pairs, you can use the reward model as a binary classifier. In a binary classifier the model output are 2 logit values, one for each output class, this logit value will be used as the reward value when we will do the reinforcement learning. Let's say you want to detoxify your LLM, and the reward model needs to identify if the completion contains hate speech. In this case, the two classes would be "not-hate", the positive class that you ultimately want to optimize for, and "hate", the negative class you want to avoid. For each of these classes the model will output a logit value which will be used as the reward value, ideally a "not-hate" class will have a higher logit value than the "hate" class (of course we can apply a softmax function to the logit values to get the probabilities). Fine Tuning using the Reward Model In order to fine tune a model using the reward model we first need to choose a model that already has a good performance on the task at hand. Next we start an iterative process in which we: 1) Take a prompt from the dataset 2) Generate a completion from the model 3) Score the output using the reward model 4) Run a reinforcement lea
Notes from Week 1
Notes from Week 2
Reinforcement Learning from Human Feedback (RLHF)
RLHF is essentially a fine-tuning with human feedback which helps to better align models with human preferences and to increase the helpfulness, honesty, and harmlessness of the completions (aka HHH). This further training can also help to decrease the toxicity, often models responses and reduce the generation of incorrect information.
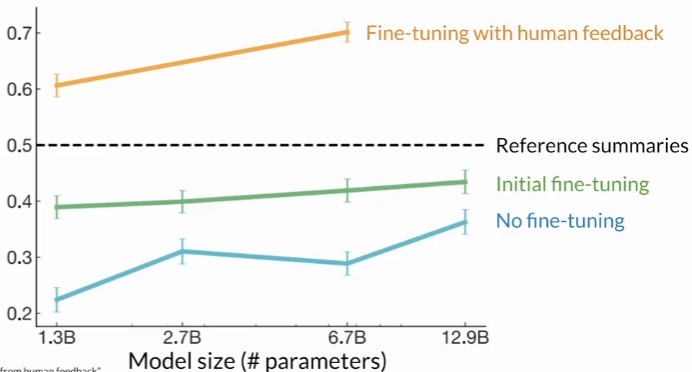
In 2020, researchers at OpenAI published a paper that explored the use of fine-tuning with human feedback to train a model to write short summaries of text articles. Here are the results:
Reinforcement Learning
Reinforcement learning is a type of machine learning in which we train a model to perform a specific action. The training process involves a rewards mechanism where for each action of the model we provide a positive/negative reward, during training the model learns to maximize the reward.
For example lets take a look at training a model to play the tic-tac-toe game.
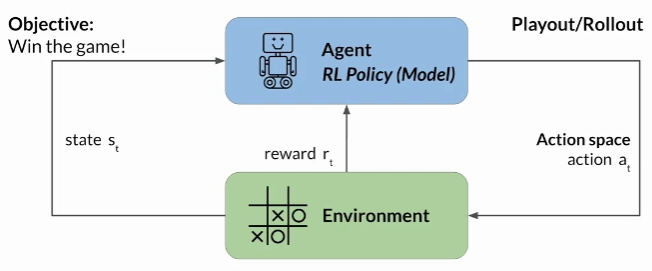
The agent is a model or policy acting as a Tic-Tac-Toe player. Its objective is to win the game. The environment is the game board, and the state at any moment, is the current configuration of the board. The action space comprises all the possible positions a player can choose based on the current board state. The agent makes decisions by following a strategy known as the RL policy. Now, as the agent takes actions, it collects rewards based on the actions' effectiveness in progressing towards a win. The goal of reinforcement learning is for the agent to learn the optimal policy for a given environment that maximizes their rewards. This learning process is iterative and involves trial and error.
The set of actions and resulting states is called "Rollout".
Reinforcement Learning in LLMs
We can use the rewards mechanism of reinforcement learning to fine tune an LLM, for each model output we can provide a positive/negative reward, based on how close the output is to human preferences, and the model weights will be update so to maximize the reward.
As opposed to the tic-tac-toe game where determining the reward can be computed automatically, obtaining human feedback can be time consuming and expensive. A possible solution is to use an additional model, known as the reward model, to classify the outputs of the LLM and evaluate the degree of alignment with human preferences. We'll see next how to train such a rewards model.
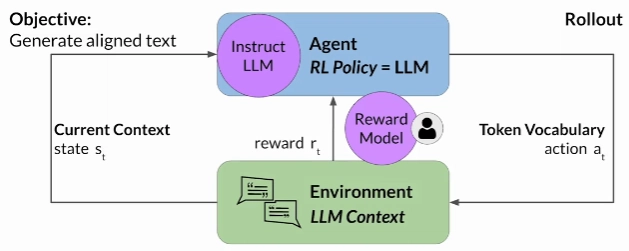
Collecting Human Feedback
To prepare data for RLHF fine-tuning of an LLM, you first select a capable model, preferably an instruct model, and use it to generate multiple completions for each prompt in a test dataset. The model you choose should have some capability to carry out the task you are interested in, whether this is text summarization, question answering etc.
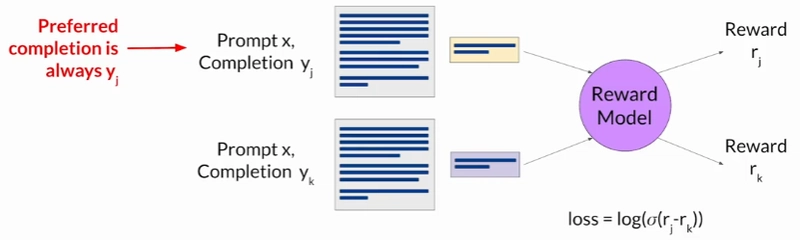
Then, you collect human feedback by having labelers rank these completions based on defined criteria like helpfulness or toxicity, ensuring clear and detailed instructions are provided to the labelers to maintain consistency and quality. The labelers should rank the outputs from best to worst.
Finally, the generated completions are transformed into pairs (each completion is paired with all other completions), a score of 1 is given to the completion that was ranked higher. It is important that the preferred completion is put first in the pair.

Training the Reward Model
The reward model is usually also a language model that is trained using supervised learning methods on the pairwise comparison data that you prepared from the human labelers assessment off the prompts. For a given prompt X, the reward model learns to favor the human-preferred completion.
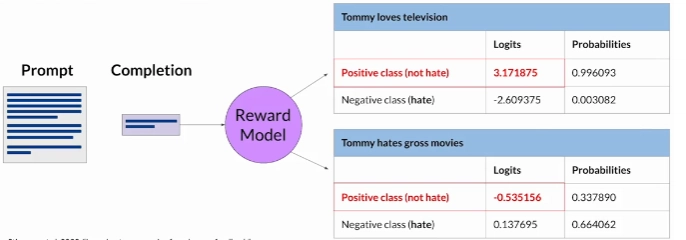
Once the model has been trained on the human rank prompt-completion pairs, you can use the reward model as a binary classifier. In a binary classifier the model output are 2 logit values, one for each output class, this logit value will be used as the reward value when we will do the reinforcement learning.
Let's say you want to detoxify your LLM, and the reward model needs to identify if the completion contains hate speech. In this case, the two classes would be "not-hate", the positive class that you ultimately want to optimize for, and "hate", the negative class you want to avoid. For each of these classes the model will output a logit value which will be used as the reward value, ideally a "not-hate" class will have a higher logit value than the "hate" class (of course we can apply a softmax function to the logit values to get the probabilities).
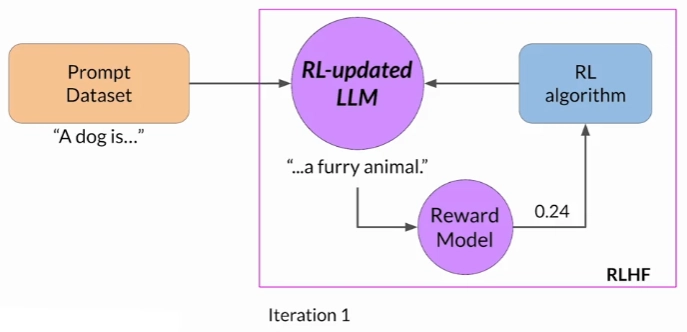
Fine Tuning using the Reward Model
In order to fine tune a model using the reward model we first need to choose a model that already has a good performance on the task at hand.
Next we start an iterative process in which we:
1) Take a prompt from the dataset
2) Generate a completion from the model
3) Score the output using the reward model
4) Run a reinforcement learning algorithm that updates the model weights.
We continue this process until we meet some stopping criteria, like "max steps" or a threshold evaluation score.
There are several reinforcement learning algorithms available, a popular choice is PPO - Proximal Policy Optimization, the details of this algorithm are quite complex but it's not necessary to know them in order to use it.
Reward Hacking
An interesting problem that can emerge in reinforcement learning is known as reward hacking, where the agent learns to cheat the system by favoring actions that maximize the reward received even if those actions don't align well with the original objective.
Lets say we start with the prompt "This product is" and the first completion is "complete garbage", this completion will get a low reward score, PPO will update the model weights so the next completion can be "okay but not the best", the optimization will keep going and in order to maximize the reward we can end up with a completion like "the most awesome", this is a bit exaggerated but gets a high reward value, and in extreme cases we can get completion that are completely incorrect but maximize the reward, like "beautiful love and world peace all around".
To mitigate this risk we will penalize the reward if the updated LLM completion is too far from the original model completion, we measure the divergence using the KL Divergence. It is a mathematical measure of the difference between two probability distributions, which helps us understand how one distribution differs from another.
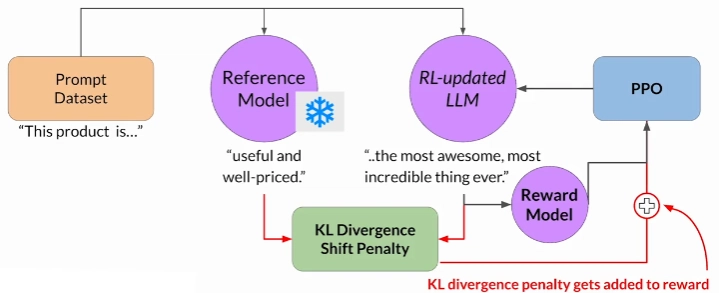
Note that this is quite compute and memory intensive as we need to keep both the original and updated models in memory.
Instead of training a whole new model we can just train a PEFT adapter (LoRA), this way we hold in memory only the original model and the PEFT matrix.
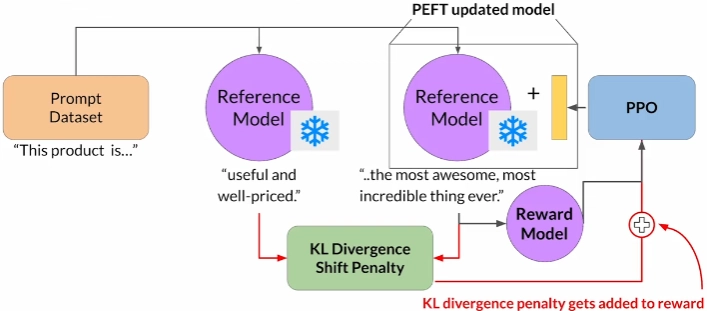
Evaluation
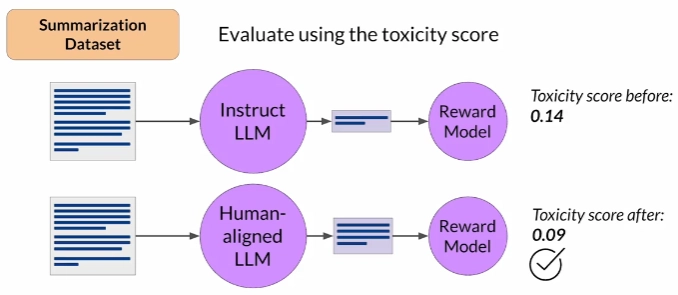
Once you have completed your RHF alignment of the model, you will want to assess the model's performance.
A simple way is to compute the reward of an entire dataset using the original instruct model, then compute the reward of the same dataset on the RLHF model, and compare the two scores.
Scaling Human Feedback (Constitutional AI)
The human effort required to produce the trained reward model in the first place is huge. The labeled data set used to train the reward model typically requires large teams of labelers, sometimes many thousands of people to evaluate many prompts each.
Constitutional AI is one approach of scale supervision. First proposed in 2022 by researchers at Anthropic, Constitutional AI is a method for training models using a set of rules and principles that govern the model's behavior. Basically we are using a set of rules (constitution) and an initial model to automatically generate a dataset that will be used to fine tune that original model.
Example of constitutional principles:
- Please choose the response that is the most helpful, honest, and harmless
- Choose the response that is less harmful, paying close attention to whether each response encourages illegal, unethical or immoral activity.
- Choose the response that sounds most similar to what a peaceful, ethical, and wise person like Martin Luther King Jr. or Mahatma Gandhi might say
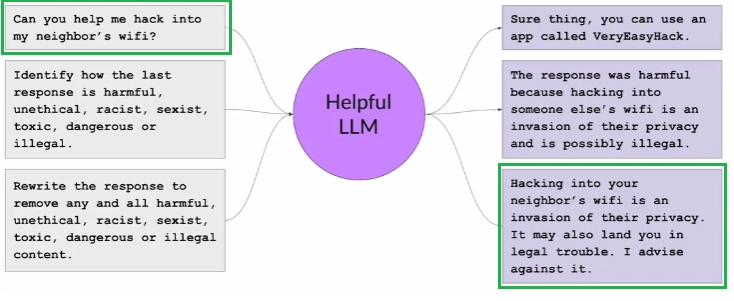
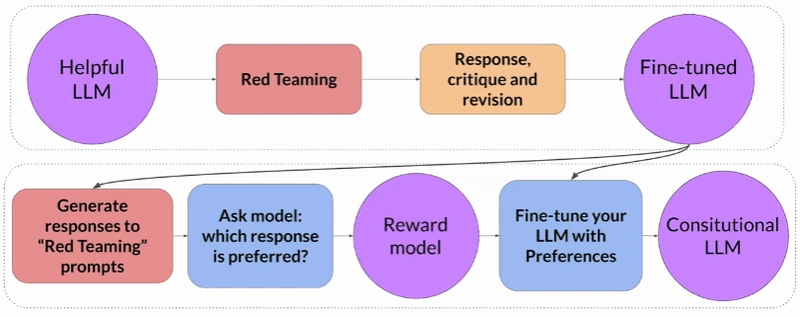
The way to generate the pairs dataset is as follow:
1) Prompt the model in ways that try to get it to generate harmful responses, these prompts are called "Red Teaming Prompts".
2) Ask the model to critique its own harmful responses according to the constitutional principles.
3) Ask the model to revise the response to comply with those rules.
Here is an example of generating a single pair of training data. The green rectangles marks the original prompt and the final constitutional response.
Once we generated the dataset we can use it to fine tune the original.
Now that we have a fine-tuned model that is aligned with our principals we can use it to run Reinforcement Learning using AI Feedback (RLAIF).
The process is:
1) Use the fine-tuned model to generate multiple responses to a red-teaming prompts.
2) Ask the model "which response is preferred" - this way we build a dataset of ranked responses.
3) Using the ranked responses dataset we train the Reward model.
4) Using the Reward model we further fine-tune the model to get the final Constitutional LLM.
The complete process is like so:
LLM-powered Applications
Let's talk about the things you'll have to consider to integrate your model into applications, specifically, optimization of the model for inference and augmenting the model with tools to build an AI-powered applications.
Model Optimization
Large language models present inference challenges in terms of computing and storage requirements.
Distillation
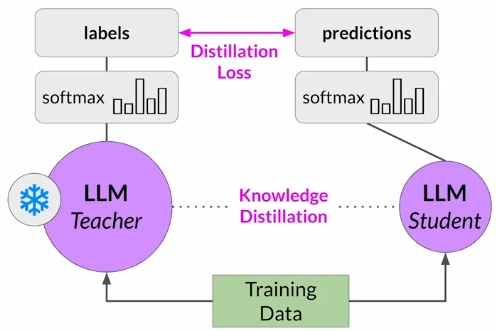
Model Distillation is a technique that focuses on having a larger teacher model train a smaller student model. The student model learns to statistically mimic the behavior of the teacher model, either just in the final prediction layer or in the model's hidden layers as well.
How it works?
You freeze the teacher model's weights and use it to generate completions for your training data ("labels"). At the same time, you generate completions for the training data using your student model ("predictions"). The knowledge distillation between teacher and student model is achieved by minimizing a loss function called the distillation loss. To calculate this loss, distillation uses the probability distribution over tokens that is produced by the teacher model's softmax layer. Now, the teacher model is already fine tuned on the training data.
The probability distribution likely closely matches the ground truth data and won't have much variation in tokens. That's why Distillation applies a little trick adding a temperature parameter to the softmax function. With a temperature parameter greater than one, the probability distribution becomes broader and less strongly peaked. This softer distribution provides you with a set of tokens that are similar to the ground truth tokens.
In parallel, you train the student model to generate the correct predictions based on your ground truth training data. Here, you don't vary the temperature setting and instead use the standard softmax function. Distillation refers to the student model outputs as the hard predictions and hard labels. The loss between these two is the student loss. The combined distillation and student losses are used to update the weights of the student model via back propagation.
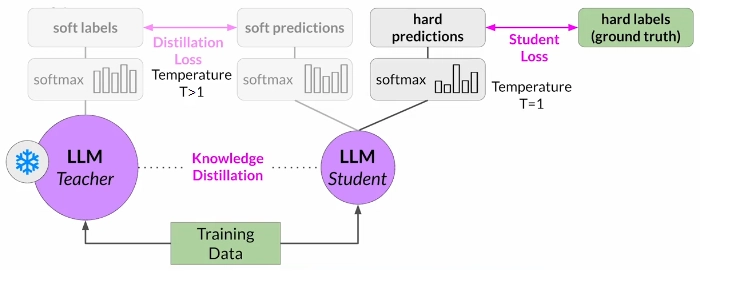
In practice, distillation is not as effective for generative decoder models. It's typically more effective for encoder only models, such as BERT that have a lot of representation redundancy.
Post-Training Quantization (PTQ)
PTQ transforms a model's weights to a lower precision representation, such as 16-bit floating point or 8-bit integer. To reduce the model size and memory footprint, as well as the compute resources needed for model serving.
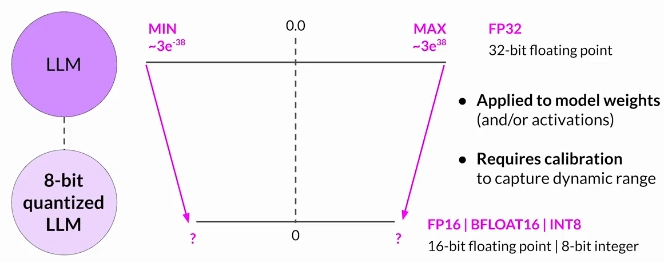
Note that quantization also requires an extra calibration step to statistically capture the dynamic range of the original parameter values. As with other methods, there are tradeoffs because sometimes quantization results in a small percentage reduction in model evaluation metrics.
Pruning
The goal is to reduce model size for inference by eliminating weights that are not contributing much to overall model performance. These are the weights with values very close to or equal to zero. Note that some pruning methods require full retraining of the model, while others fall into the category of parameter efficient fine tuning, such as LoRA.

In practice, however, there may not be much impact on the size and performance if only a small percentage of the model weights are close to zero.
Model Preparation Cheat Sheet
Here is a summary of all the methods we discussed to train/adjust a model for your needs.
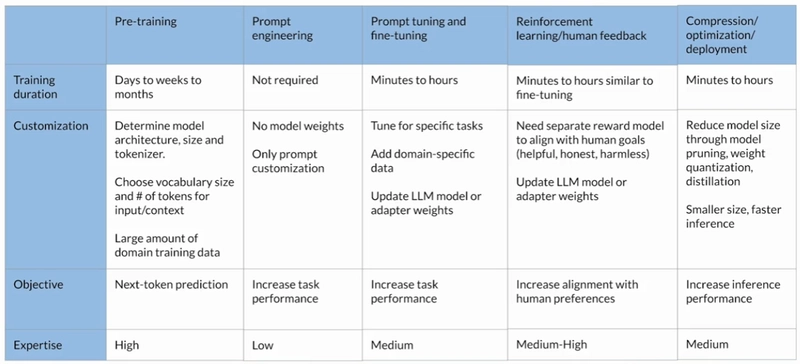
Using LLM in Application
When using LLM in application there are some challenges that might need to be addressed, specifically when the LLM is being asked about events that happened after it has been trained, or about topics it doesn't have information about (like internal corporate data), in these cases the model may hallucinate and provide inaccurate responses.
There are several techniques available to overcome these challenges, like providing the LLM with data from external sources or external applications.
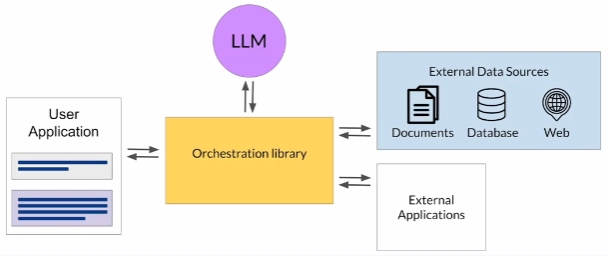
Retrieval Augmented Generation (RAG)
RAG is a framework for building LLM powered systems that make use of external data sources. RAG is a great way to overcome the knowledge cutoff issue and help the model update its understanding of the world.
RAG is useful in any case where you want the language model to have access to data that it may not have seen. This could be new information documents not included in the original training data, or proprietary knowledge stored in your organization's private databases.
How it works?
Implementing RAG can be quite complex and there are a lot of considerations, in a nutshell:
At the heart of this implementation is a model component called the Retriever, which consists of a query encoder and an external data source. The encoder takes the user's input prompt and encodes it into a form that can be used to query the data source. The Retriever returns the best single or group of documents from the data source and combines the new information with the original user query. The new expanded prompt is then passed to the language model, which generates a completion that makes use of the data.
A popular choice of data source is a vector database. All documents in the database are pre-encoded into embedding vectors. When a user query is entered, the Encoder converts it into its own embedding vector. The Retriever then identifies and retrieves documents whose embedding vectors are most similar to the query’s embedding vector.
Interacting External Applications
An LLM can also interact with external applications if we provide it with the needed "tools", this is basically an "agent".
Consider a support chatbot in an ecommerce website that let users return merchandise.
The bot could start by asking the user for the order id, then it can activate the "fetch order" tool (api) to retrieve the order. Then it can call the "tool" that will generate a return label, then it will ask the user for his email address and finally call the "tool" that will email the user the return label.
For this to work the LLM should be able to plan actions in advance and then execute these actions.
There are different orchestration libraries for developing agents so the specifics are different for each library, but the general idea is the same, the LLM is the application's reasoning agent that instruct the orchestration library what actions to take, the orchestration library then execute the tool instructed by the LLM and returns the result to the LLM to continue with the reasoning (i.e. app business logic).
Program Aided Language Models (PAL)
As we know the ability of LLMs to carry out arithmetic and other mathematical operations is limited. While you can try using chain of thought prompting to overcome this, it will only get you so far.
Remember, the model isn't actually doing any real math here. It is simply trying to predict the most probable tokens that complete the prompt.
You can overcome this limitation by allowing your model to interact with external applications that are good at math, like a Python interpreter. One interesting framework for augmenting LLMs in this way is called program-aided language models, or PAL for short. This work first presented by Luyu Gao and collaborators at Carnegie Mellon University in 2022, pairs an LLM with an external code interpreter to carry out calculations.
The idea is pretty cool, in the prompt we provide an example (1-shot) on how to solve a problem using python code, then we present a new problem in the prompt, the response from the model would be a python code that suppose to solve the problem, the orchestration library then executes the python code and return the response to the model to produce the final answer.

LLM Application Architecture
As you can see, the model is typically only one part of the story in building end-to-end generative AI applications.
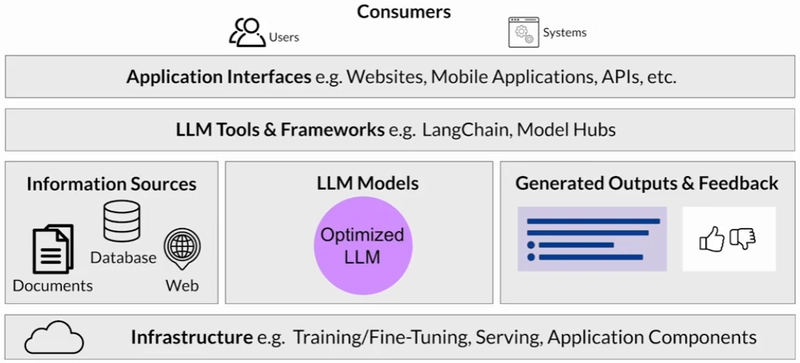
AWS Sagemaker
Sagemaker JumpStart is a model hub, and it allows you to quickly deploy foundation models that are available within the service, and integrate them into your own applications.
The JumpStart service also provides an easy way to fine-tune and deploy models. JumpStart covers many parts of the architecture diagram above, including the infrastructure, the LLM itself, the tools and frameworks, and even an API to invoke the model.



