![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)












































































































































































































































































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)














































































































![M4 MacBook Air Drops to New All-Time Low of $912 [Deal]](https://www.iclarified.com/images/news/97108/97108/97108-640.jpg)
![New iPhone 17 Dummy Models Surface in Black and White [Images]](https://www.iclarified.com/images/news/97106/97106/97106-640.jpg)


























































































































Model Context Protocol: Parte I Creando un Servidor MCP
Anthropic ha lanzado un nuevo protocolo de comunicación para modelos de IA llamado Model Context Protocol el cual nos permite brindarle información, contexto y herramientas a LLMs que requieren flujos complejos para lograr respuestas fnales. En este ciclo de post veremos como crear servidores MCP (MCP Servers) y clientes MCP (MCP Clients) para lograr, por medio de un prompt, que un LLM pueda acceder a herramientas creadas por nosotros y, a través de ellas, se conecte a APIS externas para obtener información en tiempo real o ejecute cualquier código que nosotros construyamos y así lograr una respuesta con base en dicha información consultada. Model Context Protocol Como puedes ver en la imágen anterior tenemos algo llamado clientes MCP que se conectan, a través del protocolo MCP, a un servidor MCP y este tiene acceso a bases de datos, sistemas de archivos o puede realizar llamadas a una API externa. Pero, ¿qué es un cliente y un servidor MCP? Cliente MCP Un cliente MCP es básicamente Claude Desktop, Github Copilot o en su defecto una aplicación o componente de software creado por nosotros mismos. Este cliente es el encargado de recibir el prompt del usuario y conectarse al servidor MCP el cual es el que almacena en su interior las Tools que están disponibles para ser ejecutadas y realizar acciones ya sea sobre nuestro sistema de archivos, una base de datos o solicitudes a través de la web. Los permisos de estas acciones deben estar configurados en nuestro servidor MCP. Servidor MCP Dicho lo anterior, el servidor MCP es el encargado de almacenar tres tipos de datos para que estén disponibles al cliente MCP: Resources Prompts Tools Hasta ahora hemos hecho un esbozo de lo que significan las Tools en el contexto de los MCP pero ¿Qué son los Resources y los Prompts? Resources Los Resources o Recursos son datos que expone el servidor al cliente para que este los lea y use como contexto para el LLM. En ese sentido los recursos pueden ser: Archivos Registros de bases de datos Respuestas de una API Logs entre otros Si deseas aprender más sobre Resources lee esto Prompts Los prompts en este contexto son prompts templates que podemos almacenar en nuestro servidor y exponerlos al cliente para que los pueda usar y, de esta forma, mantener una cohesión a la hora de realizar ciertas tareas dentro del flujo de nuestro sistema. Si deseas aprender más sobre Prompts lee esto Tools Por último, las Tools. Debemos pensar estas como funcionalidades almacenadas en nuestro servidor MCP para poder ejecutar diferentes tipos de operaciones: Interactuar con APIS externas. Realizar operaciones de computo. En otras palabras, estas herramientas no son más que funciones, como las que hemos construido siempre, almacenadas y listas para ser ejecutadas por el servidor MCP si el LLM asi lo decide. Si deseas aprender más sobre Tools lee esto En este post estarémos enfocados en el uso de Tools principalmente. Ahora bien, ¿cómo definimos estas herramientas en nuestro servidor MCP? Cuando usamos algún sdk de model context protocol la definición de estas herramientas tiene su propia sintaxis las cuales puedes ver aquí: Python Typescript Java Kotlin C# Para nuestro caso definiremos nuestro servidor MCP usando el SDK de Python: from mcp.server.fastmcp import FastMCP from dotenv import load_dotenv from utils.helpers import fetch_url, search_web from constants import SERPER_URL, docs_urls load_dotenv() mcp = FastMCP("docs") @mcp.tool() async def get_docs(query:str, library:str): """ Search the documentation for a given query and library, Supports Langchain, Openai, llama-index. Args: query: The query to search (e.g: Chroma DB) library: The library search in (e.g: Langchain) Returns: The information from the documentation. """ if library not in docs_urls: raise ValueError(f"The library {library} is not supported.") query = f"site:{docs_urls[library]} {query}" search_web_results = await search_web(query=query, url=SERPER_URL) if "error" in search_web_results: raise ValueError(f"Something went wrong: {search_web_results["error"]}") text = "" for result in search_web_results["organic"]: text += await fetch_url(result["link"]) return text def main(): mcp.run(transport="stdio") if __name__ == "__main__": main() En el código anterior podemos observar 5 aspectos importantes: La definición de nuestro MCP server. La creación de una herramienta o Tool para nuestro MCP Server. Validaciones dentro de nuestro MCP server. La creación de funciones utilitarias para modularizar la tarea de nuestra herramienta. El runner de nuestro MCP Server utilizando un concepto que veremos mas adelante llamado transport. veamos punto por punto. Definición de nuestro MCP server Para crear nuestro servidor es necesario instalar la depende
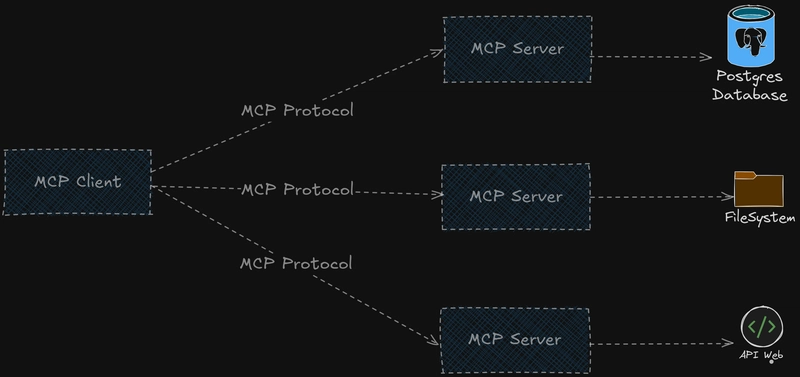
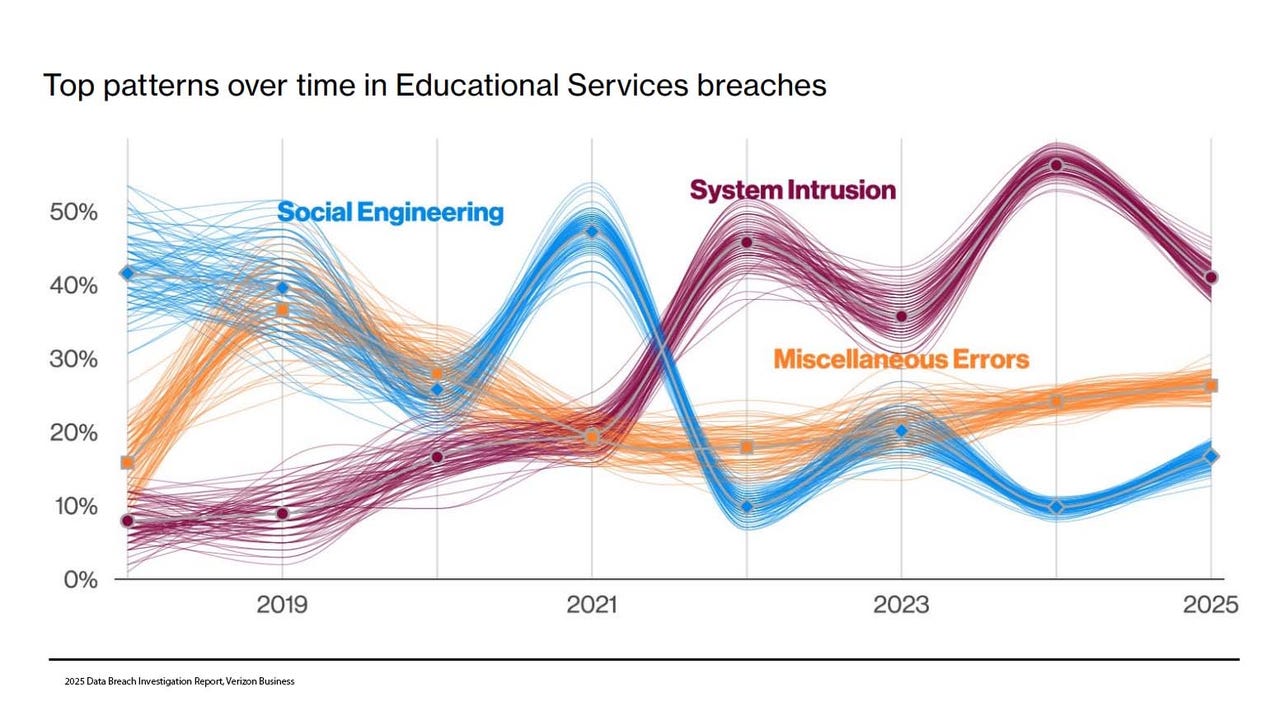
Anthropic ha lanzado un nuevo protocolo de comunicación para modelos de IA llamado Model Context Protocol el cual nos permite brindarle información, contexto y herramientas a LLMs que requieren flujos complejos para lograr respuestas fnales.
En este ciclo de post veremos como crear servidores MCP (MCP Servers) y clientes MCP (MCP Clients) para lograr, por medio de un prompt, que un LLM pueda acceder a herramientas creadas por nosotros y, a través de ellas, se conecte a APIS externas para obtener información en tiempo real o ejecute cualquier código que nosotros construyamos y así lograr una respuesta con base en dicha información consultada.
Model Context Protocol
Como puedes ver en la imágen anterior tenemos algo llamado clientes MCP que se conectan, a través del protocolo MCP, a un servidor MCP y este tiene acceso a bases de datos, sistemas de archivos o puede realizar llamadas a una API externa. Pero, ¿qué es un cliente y un servidor MCP?
Cliente MCP
Un cliente MCP es básicamente Claude Desktop, Github Copilot o en su defecto una aplicación o componente de software creado por nosotros mismos. Este cliente es el encargado de recibir el prompt del usuario y conectarse al servidor MCP el cual es el que almacena en su interior las Tools que están disponibles para ser ejecutadas y realizar acciones ya sea sobre nuestro sistema de archivos, una base de datos o solicitudes a través de la web.
Los permisos de estas acciones deben estar configurados en nuestro servidor MCP.
Servidor MCP
Dicho lo anterior, el servidor MCP es el encargado de almacenar tres tipos de datos para que estén disponibles al cliente MCP:
- Resources
- Prompts
- Tools
Hasta ahora hemos hecho un esbozo de lo que significan las Tools en el contexto de los MCP pero ¿Qué son los Resources y los Prompts?
Resources
Los Resources o Recursos son datos que expone el servidor al cliente para que este los lea y use como contexto para el LLM. En ese sentido los recursos pueden ser:
- Archivos
- Registros de bases de datos
- Respuestas de una API
- Logs
- entre otros
Si deseas aprender más sobre Resources lee esto
Prompts
Los prompts en este contexto son prompts templates que podemos almacenar en nuestro servidor y exponerlos al cliente para que los pueda usar y, de esta forma, mantener una cohesión a la hora de realizar ciertas tareas dentro del flujo de nuestro sistema.
Si deseas aprender más sobre Prompts lee esto
Tools
Por último, las Tools. Debemos pensar estas como funcionalidades almacenadas en nuestro servidor MCP para poder ejecutar diferentes tipos de operaciones:
- Interactuar con APIS externas.
- Realizar operaciones de computo.
En otras palabras, estas herramientas no son más que funciones, como las que hemos construido siempre, almacenadas y listas para ser ejecutadas por el servidor MCP si el LLM asi lo decide.
Si deseas aprender más sobre Tools lee esto
En este post estarémos enfocados en el uso de Tools principalmente.
Ahora bien, ¿cómo definimos estas herramientas en nuestro servidor MCP? Cuando usamos algún sdk de model context protocol la definición de estas herramientas tiene su propia sintaxis las cuales puedes ver aquí:
Para nuestro caso definiremos nuestro servidor MCP usando el SDK de Python:
from mcp.server.fastmcp import FastMCP
from dotenv import load_dotenv
from utils.helpers import fetch_url, search_web
from constants import SERPER_URL, docs_urls
load_dotenv()
mcp = FastMCP("docs")
@mcp.tool()
async def get_docs(query:str, library:str):
"""
Search the documentation for a given query and library,
Supports Langchain, Openai, llama-index.
Args:
query: The query to search (e.g: Chroma DB)
library: The library search in (e.g: Langchain)
Returns:
The information from the documentation.
"""
if library not in docs_urls:
raise ValueError(f"The library {library} is not supported.")
query = f"site:{docs_urls[library]} {query}"
search_web_results = await search_web(query=query, url=SERPER_URL)
if "error" in search_web_results:
raise ValueError(f"Something went wrong: {search_web_results["error"]}")
text = ""
for result in search_web_results["organic"]:
text += await fetch_url(result["link"])
return text
def main():
mcp.run(transport="stdio")
if __name__ == "__main__":
main()
En el código anterior podemos observar 5 aspectos importantes:
- La definición de nuestro MCP server.
- La creación de una herramienta o Tool para nuestro MCP Server.
- Validaciones dentro de nuestro MCP server.
- La creación de funciones utilitarias para modularizar la tarea de nuestra herramienta.
- El runner de nuestro MCP Server utilizando un concepto que veremos mas adelante llamado transport.
veamos punto por punto.
Definición de nuestro MCP server
Para crear nuestro servidor es necesario instalar la dependencia necesaria
pip install "mcp[cli]"
Una vez instalada debemos importar la clase FastMCP así:
from mcp.server.fastmcp import FastMCP
y una vez importada instanciamos nuestro servidor:
mcp = FastMCP(name="docs")
El parámetro name puede ser cualquiera que desees
Creación de herramienta
Para crear una herramienta necesitamos definir una función y anteponer la directiva:
@mcp.tool()
Esto le permite al servidor identificar que la función es una herramienta y así diferenciarla de los resources o prompts que vimos anteriormente.
Por otro lado es importante definir el docstring de manera clara, correcta y precisa. Proveer metadata sobre lo que hace la función, los argumentos que recibe y lo que se espera devolver como resultado. Entre más especifica sea la información que le proveamos al docstring el LLM tendrá más contexto para saber que herramienta ejecutar según el prompt que se haya usado.
En nuestro caso la herramienta recibe dos parámetros query y library los cuales son:
- Query: Tópico que se desea consultar.
- Library: Documentación o librería sobre la cual se desea consultar el tópico.
Estos dos parámetros son los que el LLM debe de identificar sobre el prompt utilizado y para ello es necesario una buena descripción de la herramienta usando los docstring.
Validaciones dentro de nuestro MCP server
Como puedes observar una herramienta de nuestro servidor MCP se comporta como una función comun y corriente por lo tanto dentro de ella podemos realizar validaciones y manejar errores de una manera convencional. En este caso levantamos dos casos de error:
if library not in docs_urls:
raise ValueError(f"The library {library} is not supported.")
if "error" in search_web_results:
raise ValueError(f"Something went wrong: {search_web_results["error"]}")
Para la primera validación usamos una variable llamada docs_urls para centralizar y modularizar las posibles librerías que el usuario puede consultar. Esta variable no es mas que una lista definida así:
docs_urls={
"langchain": "python.langchain.com/docs",
"llama-index": "docs.llamaindex.ai/en/stable",
"openai": "platform.openai.com/docs"
}
En este punto es bueno realizar énfasis en que al tener unos buenos metadatos en el docstring podemos lograr que el modelo identifique dentro del prompt la librería que el usuario desea consultar y así logre almacenarla dentro del parámetro library y de esa forma nosotros poder usarlo dentro de nuestras validaciones internas.
Funciones utilitarias
Como ya hemos resaltado nos encontramos frente a una función de python comun y corriente la cual podemos manipular de tal forma que nos permite modularizar los procesos que esta necesite realizar. En nuestro caso hemos abstraido dos procesos search_web y fetch_url.
Para la primera función utilizamos Serper como buscador de google con el fin de recuperar las 2 primeras URLs que coincidad con la busqueda del usuario. Para esto lo hacemos asi
query = f"site:{docs_urls[library]} {query}"
search_web_results = await search_web(query=query, url=SERPER_URL)
formateamos la variable query utilizando un operador de busqueda avanzada de google el cual nos permite buscar solo dentro de la URL que recuperamos de nuestra lista asi:
docs_urls[library]
Una vez formateado esta variable lo pasamos como parámetro a la función search_web_results junto con la URL de serper. Ya por dentro de la función encontramos este código:
async def search_web(query:str, url:str) -> dict | None:
payload = json.dumps({"q": query, "num": 2})
headers= {
"X-API-KEY": os.getenv("SERPER_API_KEY"),
"Content-Type": "Application/json"
}
async with httpx.AsyncClient() as client:
try:
response = await client.post(
url,
data=payload,
headers=headers,
timeout=30.0
)
response.raise_for_status()
return response.json
except httpx.TimeoutException():
return {"error": "Timeout error searching web"}
except httpx.HTTPStatusError as e:
return {"error": f"Error: {e.response.status_code}"}
EL cual no es más que una llamada a la API de Serper para que nos devuelva los 2 primeros resultados de la búsqueda.
Nuestra segunda función fetch_url se ejecuta después de devolver los resultados de search_web la propiedad que necesitamos, siguiendo la documentación de Serper, es organic la cual es una lista que contiene otra pripiedad llamada link y son estos links, en nuestro caso 2, los que utilizaremos como parámetros de nuestra segunda función fetch_url. Lo anterior lo encontramos definido aquí:
search_web_results = await search_web(query=query, url=SERPER_URL)
if "error" in search_web_results:
raise ValueError(f"Something went wrong: {search_web_results["error"]}")
text = ""
for result in search_web_results["organic"]:
text += await fetch_url(result["link"])
Como podemos observar nuestra función fetch_url se ejecuta dentro de un ciclo for utilizando la lista search_web_results["organic"]. Ya por dentro la función fetch_url luce así:
async def fetch_url(url:str):
try:
async with httpx.AsyncClient() as client:
response = await client.get(url=url, timeout=30.0)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
text = soup.get_text()
return text
except httpx.TimeoutException():
return {"error": "Timeout Error fetching url"}
Esta función realiza una solicitud HTTP a las URLs obtenidas en la primera función y, por medio de Beautiful Soup, parseamos el HTML a texto y lo devolvemos como respuesta de la misma función.
Por último el resultado de la función fetch_url lo devolvemos como respuesta final de la MCP Tool.
Transport
Por último nuestro código define el tipo de transporte que nuestro MCP Server utilizará. Para nuestro caso utilizamos el transporte tipo stdio el cual es un standard I/O que se recomienda usar cuando nuestro servidor MCP esta enfocado a aplicaciones por CLI o que corren de manera local en nuestro sistema realizando integraciones.
Se debe tener en cuenta de que existe otro tipo de transporte llamado SSE que está enfocado a conexiones entre el servidor MCP y un cliente MCP por medio de solicitudes POST.
Si deseas conocer más sobre transportes mira esto.
Vale hasta aquí hemos construido nuestro servidor MCP pero surgen 2 preguntas
- ¿Cómo lo usamos?
- ¿Dónde entra la IA en todo esto?
Como se nombro al principio estos servidores MCP se pueden utilizar ya sea con cliente creado por nosotros mismos o con alguna aplicacion de LLMs como Github Copilot o Claude Desktop.
En esta primera parte explicarémos como integrar nuestro servidor MCP con Github Copilot y en una segunda parte abordaremos la creación de un cliente personalizado que utiliza Express para comunicarse con nuestro servidor MCP.
Instalación con Github Copilot
Realmente es muy sencillo. Debemos primero asegurarnos tener las extensiones correspondientes de Github Copilot en VsCode y haber configurado nuestra cuenta para tener acceso a Copilot.
Luego de esto, debemos dirigirnos al archivo, dentro de vscode, llamado settings.json el cual se puede acceder así:
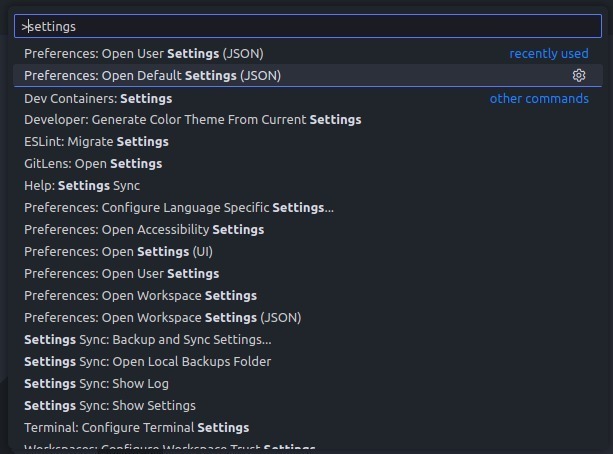
Damos click en Open user settings (JSON) y nos abrirá nuestras configuraciones de Vscode en formato JSON. Lo que harémos sera agregar al final de este archivo una nueva propiedad llamada mcp así:
"mcp": {
"servers":{
"documentation":{
"command": "",
"args": [
"--directory",
"",
"run",
"src/main.py"
]
}
}
}
Como puedes ver nos hace falta completar dos valores command y la tercera posición del array args. Para obtener estos valores sigue esto pasos:
- Para la propiedad command, si utilizaste
uvcomo package management, corre en tu terminal el comandowhich uvy pega esa ruta en la propiedadcommand - para la segunda posición del array args debes de pararte en la carpeta en donde está tu servidor MCP y correr el comando
pwd. Pega esa ruta en la segunda posición del array args.
Vale, pero ¿Qué es todo esto? Para poder utilizar nuestro servidor MCP con Copilot debemos especificarlo en nuestro settings.json para que copilot tenga acceso a él. Para ello definimos una propiedad mcp y dentro de ella otra propiedad llamada servers. En esta última listaremos todos los servidores que creemos para que Copilot pueda encontrarlos.
Cada servidor MCP que especifiquemos aquí debe de tener una configuración para que se corra cuando interactuemos con Copilot. Si utilizamos el ejemplo de nuestro ejercicio, al definir esto:
"documentation":{
"command": "",
"args": [
"--directory",
"",
"run",
"src/main.py"
]
}
es como si corrieramos en nuestra terminal esto:
uv --directory run
Al hacer esto, abriremos nuestro Copilot dentro de vscode y configuraremos el modo agent automaticamente se nos habilitará un icono al lado del input
![]()
AL dar click en este icono verémos todos nuestros MCP servers disponibles
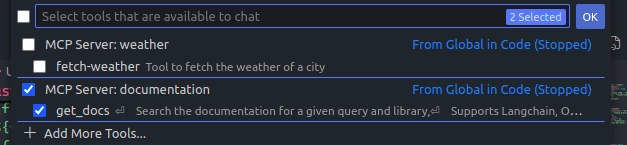
Podemos habilitarlos y deshabilitarlos a nuestro gusto.
Es todo, ya podemos utilizar nuestro LLM con Copilot y este tendrá acceso a los MCP habilitados en nuestro sistema para utilizarlos si considera que para lograr una respuesta correcta a nuestro prompt debe de acceder a ellos como herramientas.
En una próxima entrega veremos como podemos conectar este MCP Server a un MCP Client que utiliza Express para capturar los prompts del usuario que provienen de cualquier cliente que se pueda comunicar por medio de HTTP. Logrando esto veremos el panorama completo del flujo de datos dentro del protocolo MCP utilizando un LLM de por medio para completar tareas que requiera nuestro usuario.
Si desean darle un vistazo al código completo desde el repositorio pueden hacerlo desde aquí.