












































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)

































_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)






































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)





























































































































Making Embeddings Understand Files and Folders with Simple Sentences (messy-folder-reorganizer-ai)
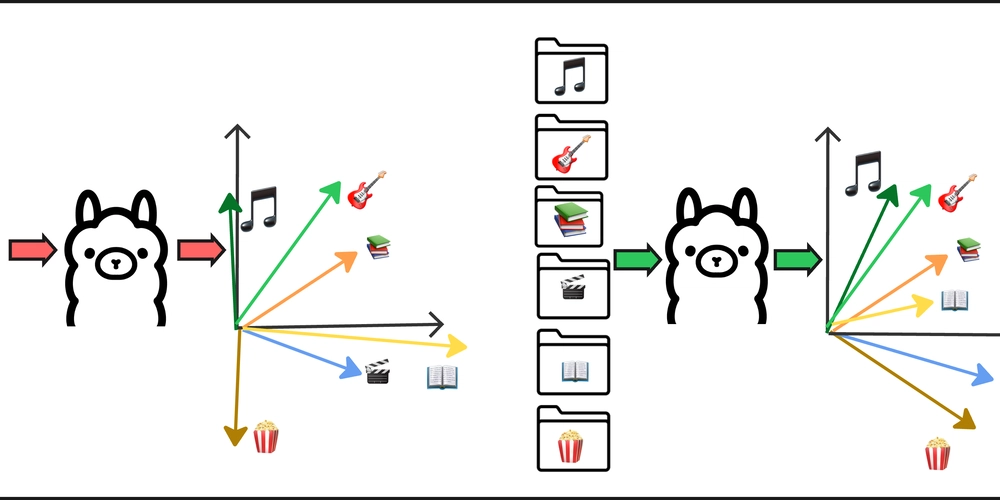
Do Embeddings Need Context? A Practical Look at File-to-Folder Matching When building smart systems that classify or match content — such as automatically sorting files into folders — embeddings are a powerful tool. But how well do they work with minimal input? And does adding natural language context make a difference? During development messy-folder-reorganizer-ai I found how adding contextual phrasing to file and folder names significantly improved the performance of embedding models and in this article I will share it with the reader. Test Case: Matching Files to Valid Folder Names Test A: Using Only File and Folder Names | File Name | Folder Name | Score | |-------------------------|-------------|-----------| | crack.exe | apps | 0.5147713 | | lovecraft novels.txt | books | 0.5832841 | | police report.docx | docs | 0.6303186 | | database admin.pkg | docs | 0.5538312 | | invoice from google.pdf | docs | 0.5381457 | | meme.png | images | 0.6993392 | | funny cat.jpg | images | 0.5511819 | | lord of the ring.avi | movies | 0.5454072 | | harry potter.mpeg4 | movies | 0.5410566 | Test B: Adding Natural Language Context Each string was framed like: "This is a file name: {file_name}" "This is a folder name: {folder_name}" | File Name | Folder Name | Score | |--------------------------------|-------------|-----------| | crack.exe | apps | 0.6714907 | | lovecraft novels.txt | books | 0.7517922 | | database admin.pkg | dest | 0.7194574 | | police report.docx | docs | 0.7456068 | | invoice from google.pdf | docs | 0.7141885 | | meme.png | images | 0.7737676 | | funny cat.jpg | images | 0.7438067 | | harry potter.mpeg4 | movies | 0.7156760 | | lord of the ring.avi | movies | 0.6718528 | Observations: Scores were consistently higher across the board when context was added. The model made more accurate matches, such as correctly associating database admin.pkg with dest instead of books. This suggests that embeddings perform better with structured, semantic context, not just bare tokens. Test Case: Only Some Files Have Valid Matches Now let's delete the movies and images folders and observe how the matching behavior changes: Test A: Using Only File and Folder Names | File Name | Folder Name | Score | |-------------------------|-------------|------------| | hobbit.fb2 | apps | 0.55056566 | | crack.exe | apps | 0.5147713 | | lovecraft novels.txt | books | 0.57081085 | | police report.docx | docs | 0.6303186 | | meme.png | docs | 0.58589196 | | database admin.pkg | docs | 0.5538312 | | invoice from google.pdf | docs | 0.5381457 | | lord of the ring.avi | docs | 0.492918 | | funny cat.jpg | docs | 0.45956808 | | harry potter.mpeg4 | docs | 0.45733657 | Test B: Adding Natural Language Context Same context generation pattern as in previous test case | File Name | Folder Name | Score | |-------------------------|-------------|------------| | crack.exe | apps | 0.6714907 | | lovecraft novels.txt | books | 0.72899115 | | database admin.pkg | dest | 0.7194574 | | meme.png | dest | 0.68507683 | | funny cat.jpg | dest | 0.6797525 | | lord of the ring.avi | dest | 0.5323342 | | police report.docx | docs | 0.7456068 | | invoice from google.pdf | docs | 0.71418846 | | hobbit.fb2 | docs | 0.6780642 | | harry potter.mpeg4 | docs | 0.5984984 | Observations: In Test A, files like meme.png, funny cat.jpg, and lord of the ring.avi were incorrectly matched to the docs folder. In Test B, they appeared in the more appropriate dest folder. There are still some mismatches — for example, hobbit.fb2 was matched with docs instead of books, likely due to the less common .fb2 format. harry potter.mpeg4 also matched with docs, though with a relatively low score. Why Does This Happen? 1. Context Gives Structure Embedding models are trained on natural language. So when we provide structured inputs like: “This is a file name: invoice from google.pdf” “This is a folder name: docs” ...the model better understands the semantic role of each string. It knows these aren't just tokens — they are types of things, which makes embeddings more aligned. 2. It’s Not Just Word Overlap Yes, phrases like "this is a f
Do Embeddings Need Context? A Practical Look at File-to-Folder Matching
When building smart systems that classify or match content — such as automatically sorting files into folders — embeddings are a powerful tool. But how well do they work with minimal input? And does adding natural language context make a difference?
During development messy-folder-reorganizer-ai I found how adding contextual phrasing to file and folder names significantly improved the performance of embedding models and in this article I will share it with the reader.
Test Case: Matching Files to Valid Folder Names
Test A: Using Only File and Folder Names
| File Name | Folder Name | Score |
|-------------------------|-------------|-----------|
| crack.exe | apps | 0.5147713 |
| lovecraft novels.txt | books | 0.5832841 |
| police report.docx | docs | 0.6303186 |
| database admin.pkg | docs | 0.5538312 |
| invoice from google.pdf | docs | 0.5381457 |
| meme.png | images | 0.6993392 |
| funny cat.jpg | images | 0.5511819 |
| lord of the ring.avi | movies | 0.5454072 |
| harry potter.mpeg4 | movies | 0.5410566 |
Test B: Adding Natural Language Context
Each string was framed like:
"This is a file name: {file_name}"-
"This is a folder name: {folder_name}"
| File Name | Folder Name | Score |
|--------------------------------|-------------|-----------|
| crack.exe | apps | 0.6714907 |
| lovecraft novels.txt | books | 0.7517922 |
| database admin.pkg | dest | 0.7194574 |
| police report.docx | docs | 0.7456068 |
| invoice from google.pdf | docs | 0.7141885 |
| meme.png | images | 0.7737676 |
| funny cat.jpg | images | 0.7438067 |
| harry potter.mpeg4 | movies | 0.7156760 |
| lord of the ring.avi | movies | 0.6718528 |
Observations:
- Scores were consistently higher across the board when context was added.
- The model made more accurate matches, such as correctly associating
database admin.pkgwithdestinstead ofbooks. - This suggests that embeddings perform better with structured, semantic context, not just bare tokens.
Test Case: Only Some Files Have Valid Matches
Now let's delete the movies and images folders and observe how the matching behavior changes:
Test A: Using Only File and Folder Names
| File Name | Folder Name | Score |
|-------------------------|-------------|------------|
| hobbit.fb2 | apps | 0.55056566 |
| crack.exe | apps | 0.5147713 |
| lovecraft novels.txt | books | 0.57081085 |
| police report.docx | docs | 0.6303186 |
| meme.png | docs | 0.58589196 |
| database admin.pkg | docs | 0.5538312 |
| invoice from google.pdf | docs | 0.5381457 |
| lord of the ring.avi | docs | 0.492918 |
| funny cat.jpg | docs | 0.45956808 |
| harry potter.mpeg4 | docs | 0.45733657 |
Test B: Adding Natural Language Context
Same context generation pattern as in previous test case
| File Name | Folder Name | Score |
|-------------------------|-------------|------------|
| crack.exe | apps | 0.6714907 |
| lovecraft novels.txt | books | 0.72899115 |
| database admin.pkg | dest | 0.7194574 |
| meme.png | dest | 0.68507683 |
| funny cat.jpg | dest | 0.6797525 |
| lord of the ring.avi | dest | 0.5323342 |
| police report.docx | docs | 0.7456068 |
| invoice from google.pdf | docs | 0.71418846 |
| hobbit.fb2 | docs | 0.6780642 |
| harry potter.mpeg4 | docs | 0.5984984 |
Observations:
In Test A, files like meme.png, funny cat.jpg, and lord of the ring.avi were incorrectly matched to the docs folder. In Test B, they appeared in the more appropriate dest folder.
There are still some mismatches — for example, hobbit.fb2 was matched with docs instead of books, likely due to the less common .fb2 format. harry potter.mpeg4 also matched with docs, though with a relatively low score.
Why Does This Happen?
1. Context Gives Structure
Embedding models are trained on natural language. So when we provide structured inputs like:
“This is a file name: invoice from google.pdf”
“This is a folder name: docs”
...the model better understands the semantic role of each string. It knows these aren't just tokens — they are types of things, which makes embeddings more aligned.
2. It’s Not Just Word Overlap
Yes, phrases like "this is a file name" and "this is a folder name" are similar. But if word overlap were the only reason for higher scores, all scores would rise evenly — regardless of actual content.
Instead, we're seeing better matching. That means the model is using true context to judge compatibility — a sign that semantic meaning is being used, not just lexical similarity.
3. Raw Strings Without Context Can Be Misleading
A folder named docs or my-pc is vague. A file named database admin.pkg is even more so. Embeddings of such raw strings might be overly similar due to lack of semantic separation.
Adding even a light wrapper like "This is a file name..." or "This is a folder name..." gives the model clearer context and role assignment, helping it avoid false positives and improve semantic accuracy.
Conclusion
- Embeddings require context to be effective, especially for classification or matching tasks.
- Providing natural-language-like structure (even just a short prefix) significantly improves performance.
- It’s not just about higher scores — it’s about better semantics and more accurate results.
If you're building tools that rely on embeddings, especially for classification, recommendation, or clustering — don't be afraid to add a little helpful context. It goes a long way.
Looking for Feedback
I’d really appreciate any feedback — positive or critical — on the project, the codebase, the article series, or the general approach used in the CLI.
Thanks for Reading!
Feel free to reach out here or connect with me on:
Or just drop me a note if you want to chat about Rust, AI, or creative ways to clean up messy folders!



