![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)
































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)
































































































![Switch 2 Pre-Order Rules Are Some BS: Here's How They Work [Update]](https://i.kinja-img.com/image/upload/c_fill,h_675,pg_1,q_80,w_1200/485ec87fd3cea832387b2699e4cbd2a1.jpg)











.png?#)




(1).jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)




-Mario-Kart-World-Hands-On-Preview-Is-It-Good-00-08-36.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)






















_NicoElNino_Alamy.png?#)
_Igor_Mojzes_Alamy.jpg?#)

.webp?#)
.webp?#)








































































































![Blackmagic Design Unveils DaVinci Resolve 20 With Over 100 New Features and AI Tools [Video]](https://www.iclarified.com/images/news/96951/96951/96951-640.jpg)


![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)





















































































































Logistic Regression โดยใช้ Python
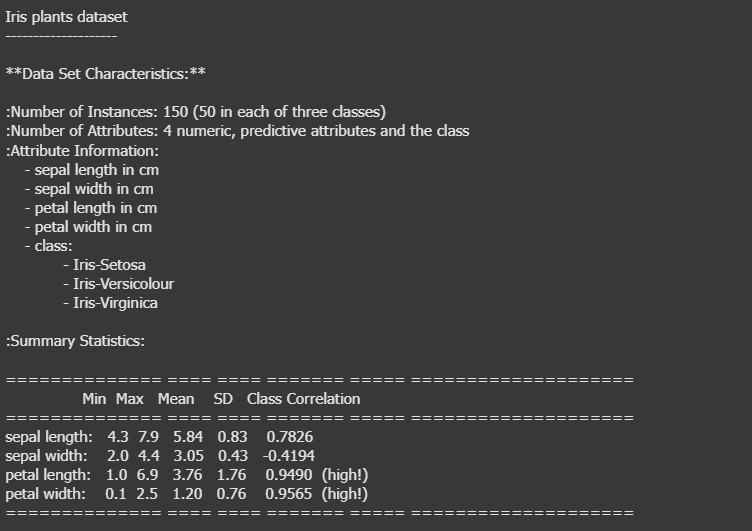
การทำนายผลลัพธ์ที่อยู่ในรูปแบบของการจำแนกประเภท เช่น ผู้ใช้จะซื้อสินค้าหรือไม่ อีเมลนี้เป็นสแปมหรือเปล่า หรือ เซลล์ในร่างกายเป็นมะเร็งหรือไม่ หนึ่งในวิธีที่ง่ายและเหมาะสมที่ใช้สำหรับการจำแนกข้อมูลประเภทนี้ คือการใช้ Logistic Regression ในบทความนี้ เราจะมาดูการใช้ Logistic Regression ใน Python โดยเราจะใช้ Google Colab ในการรันโค้ด และใช้ชุดข้อมูล Iris dataset (https://sklearner.com/scikit-learn-load_iris/) ข้อมูลชุดนี้มีทั้งหมด 150 แถว (ดอกไม้ 150 ตัวอย่าง) ประกอบด้วย 4 features และ 1 target class ซึ่งบอกสายพันธุ์ของดอกไม้ โดยในตัวอย่างนี้เราจะเลือกเฉพาะ 2 สายพันธุ์แรก เพื่อให้ง่ายต่อการจำแนกแบบ binary classification ข้อมูลประกอบด้วย 5 columns ดังนี้: sepal length (cm) – ความยาวกลีบเลี้ยง sepal width (cm) – ความกว้างกลีบเลี้ยง petal length (cm) – ความยาวกลีบดอก petal width (cm) – ความกว้างกลีบดอก target – สายพันธุ์ของดอกไม้ (0 = setosa, 1 = versicolor) ขั้นตอนที่ 1: นำเข้าข้อมูล Machine Learning ชุดข้อมูลนี้ประกอบด้วยข้อมูลเกี่ยวกับดอกไม้สามสายพันธุ์ ได้แก่ Setosa, Versicolor และ Virginica โดยมีคุณลักษณะ (features) เช่น ความยาวและความกว้างของกลีบดอกและกลีบเลี้ยง from sklearn import datasets # โหลดชุดข้อมูล Iris iris = datasets.load_iris() ขั้นตอนที่ 2: สำรวจและเตรียมข้อมูล ก่อนอื่น เรามาดูโครงสร้างของชุดข้อมูล print(iris.keys()) print(iris['DESCR']) print("Feature names:", iris['feature_names']) print("Target names:", iris['target_names']) ผลลัพท์ที่ได้จากการรันโค้ด ชุดข้อมูลนี้มีคุณลักษณะ 4 อย่าง แต่เพื่อความง่าย เราจะเลือกใช้เพียง 2 คุณลักษณะ ได้แก่ ความยาวและความกว้างของกลีบดอก (petal length และ petal width) นอกจากนี้ เราจะเลือกเฉพาะข้อมูลของสองสายพันธุ์แรก (Setosa และ Versicolor) เพื่อทำให้เป็นปัญหาการจำแนกประเภทแบบสองคลาส (binary classification) import numpy as np # เลือกคุณลักษณะ 2 อย่าง X = iris.data[:, [2, 3]] y = iris.target # เลือกเฉพาะคลาส 0 และ 1 X = X[y != 2] y = y[y != 2] ขั้นตอนที่ 3: แบ่งข้อมูลเป็นชุดฝึกสอนและชุดทดสอบ เราจะแบ่งข้อมูลออกเป็นสองส่วน: ชุดฝึกสอน (training set) และชุดทดสอบ (test set) โดยใช้สัดส่วน 80:20 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) ขั้นตอนที่ 4: สร้างและฝึกโมเดล Logistic Regression เราจะใช้ไลบรารี scikit-learn ในการสร้างและฝึกโมเดล Logistic Regression: from sklearn.linear_model import LogisticRegression # สร้างโมเดล model = LogisticRegression() # ฝึกโมเดล model.fit(X_train, y_train) ขั้นตอนที่ 5: ทำนายและประเมินผลโมเดล หลังจากฝึกโมเดลแล้ว เราจะทดสอบโมเดลกับชุดทดสอบและประเมินความแม่นยำ: from sklearn.metrics import accuracy_score # ทำนายผล y_pred = model.predict(X_test) print("Predicted class:", y_pred) # ประเมินความแม่นยำ accuracy = accuracy_score(y_test, y_pred) print(f'Accuracy: {accuracy:.2f}') นอกจากนี้ เรายังสามารถดูค่า coefficients และ intercept ของโมเดลได้: print("Coefficients:", model.coef_) print("Intercept:", model.intercept_) จากตัวอย่างนี้ เราจะได้ว่า ถ้าต้องการสร้าง Logistic Regression Model เพื่อทำนาย สายพันธุ์ของดอกไม้ (0 = setosa, 1 = versicolor) โดยใช้ 2 คุณลักษณะ ได้แก่ ความยาวและความกว้างของกลีบดอก (petal length และ petal width) เราจะได้ผลลัพท์เป็นสายพันธุ์ออกมา Predicted class: [1 1 1 0 0 0 0 1 0 0 0 0 1 0 1 0 1 1 0 0] โดยมี Acuracy อยู่ที่ 100% Logistic Regression เป็นอัลกอริธึมที่เรียบง่ายแต่มีประสิทธิภาพสำหรับการแก้ปัญหาการจำแนกประเภทแบบ Binary Classification และยังเป็นพื้นฐานที่สำคัญในการทำความเข้าใจอัลกอริธึมที่ซับซ้อนมากขึ้น การทดลองกับชุดข้อมูลอื่นๆ และการปรับเปลี่ยน parameters จะช่วยให้คุณมีความเข้าใจและสามารถประยุกต์ใช้ Logistic Regression ได้อย่างมีประสิทธิภาพมากยิ่งขึ้น ตัวอย่างเพิ่มเติม ใช้ชุดข้อมูล Wine dataset https://sklearner.com/scikit-learn-load_wine/ ข้อมูลชุดนี้มีทั้งหมด 178 แถว (ไวน์ 178 ตัวอย่าง) ประกอบด้วย 13 features และ 1 target class ซึ่งบอกประเภทของไวน์ โดยในตัวอย่างนี้ข้อมูลมี 3 ประเภท (0, 1, 2) สำหรับการจำแนกแบบ multiclass classification ข้อมูลประกอบด้วย 14 columns ดังนี้: alcohol – ปริมาณแอลกอฮอล์ malic_acid – กรดมาลิก ash – ปริมาณเถ้า alcalinity_of_ash – ความเป็นด่างของเถ้า magnesium – ปริมาณแมกนีเซียม total_phenols – ปริมาณฟีนอลทั้งหมด flavanoids – ปริมาณฟลาโวนอยด์ nonflavanoid_phenols – ปริมาณฟีนอลที่ไม่ใช่ฟลาโวนอยด์ proanthocyanins – ปริมาณโพรแอนโทไซยานิน color_intensity – ความเข้มของสี hue – ค่าฮิว od280/od315_of_diluted_wines – อัตราส่วน OD280/OD315 ของไวน์เจือจาง proline – ปริมาณโพรลีน target – ประเภทของไวน์ (0, 1, 2) ขั้นตอนที่ 1: นำเข้าข้อมูล from sklearn import datasets # โหลดชุดข้อมูล Wine wine = datasets.load_wine() ขั้นตอนที่ 2: สำรวจและเตรียมข้อมูล # สำรวจข้อมูลเบื้องต้น # สำรวจข้อมูลเบื้องต้น print("Keys of the dataset:", wine.keys()) print("\nDescription of the dataset:\n", wine['DESCR'] + "...") print("\nFeature names:", wine['feature_names']) print("Target names:", wine['target_names']) # ข้อมูลและเป้าหมาย X = wine.data y = wine.target ผลลัพท์ ขั้นตอนที่ 3: แบ่งข้อมูลเป็นชุดฝึกสอนและชุดทดสอบ เราจะแบ่ง
การทำนายผลลัพธ์ที่อยู่ในรูปแบบของการจำแนกประเภท เช่น ผู้ใช้จะซื้อสินค้าหรือไม่ อีเมลนี้เป็นสแปมหรือเปล่า หรือ เซลล์ในร่างกายเป็นมะเร็งหรือไม่ หนึ่งในวิธีที่ง่ายและเหมาะสมที่ใช้สำหรับการจำแนกข้อมูลประเภทนี้ คือการใช้ Logistic Regression
ในบทความนี้ เราจะมาดูการใช้ Logistic Regression ใน Python โดยเราจะใช้ Google Colab ในการรันโค้ด และใช้ชุดข้อมูล Iris dataset (https://sklearner.com/scikit-learn-load_iris/)
ข้อมูลชุดนี้มีทั้งหมด 150 แถว (ดอกไม้ 150 ตัวอย่าง) ประกอบด้วย 4 features และ 1 target class ซึ่งบอกสายพันธุ์ของดอกไม้ โดยในตัวอย่างนี้เราจะเลือกเฉพาะ 2 สายพันธุ์แรก เพื่อให้ง่ายต่อการจำแนกแบบ binary classification
ข้อมูลประกอบด้วย 5 columns ดังนี้:
sepal length (cm) – ความยาวกลีบเลี้ยง
sepal width (cm) – ความกว้างกลีบเลี้ยง
petal length (cm) – ความยาวกลีบดอก
petal width (cm) – ความกว้างกลีบดอก
target – สายพันธุ์ของดอกไม้ (0 = setosa, 1 = versicolor)
ขั้นตอนที่ 1: นำเข้าข้อมูล
Machine Learning ชุดข้อมูลนี้ประกอบด้วยข้อมูลเกี่ยวกับดอกไม้สามสายพันธุ์ ได้แก่ Setosa, Versicolor และ Virginica โดยมีคุณลักษณะ (features) เช่น ความยาวและความกว้างของกลีบดอกและกลีบเลี้ยง
from sklearn import datasets
# โหลดชุดข้อมูล Iris
iris = datasets.load_iris()
ขั้นตอนที่ 2: สำรวจและเตรียมข้อมูล
ก่อนอื่น เรามาดูโครงสร้างของชุดข้อมูล
print(iris.keys())
print(iris['DESCR'])
print("Feature names:", iris['feature_names'])
print("Target names:", iris['target_names'])
ผลลัพท์ที่ได้จากการรันโค้ด
ชุดข้อมูลนี้มีคุณลักษณะ 4 อย่าง แต่เพื่อความง่าย เราจะเลือกใช้เพียง 2 คุณลักษณะ ได้แก่ ความยาวและความกว้างของกลีบดอก (petal length และ petal width) นอกจากนี้ เราจะเลือกเฉพาะข้อมูลของสองสายพันธุ์แรก (Setosa และ Versicolor) เพื่อทำให้เป็นปัญหาการจำแนกประเภทแบบสองคลาส (binary classification)
import numpy as np
# เลือกคุณลักษณะ 2 อย่าง
X = iris.data[:, [2, 3]]
y = iris.target
# เลือกเฉพาะคลาส 0 และ 1
X = X[y != 2]
y = y[y != 2]
ขั้นตอนที่ 3: แบ่งข้อมูลเป็นชุดฝึกสอนและชุดทดสอบ
เราจะแบ่งข้อมูลออกเป็นสองส่วน: ชุดฝึกสอน (training set) และชุดทดสอบ (test set) โดยใช้สัดส่วน 80:20
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
ขั้นตอนที่ 4: สร้างและฝึกโมเดล Logistic Regression
เราจะใช้ไลบรารี scikit-learn ในการสร้างและฝึกโมเดล Logistic Regression:
from sklearn.linear_model import LogisticRegression
# สร้างโมเดล
model = LogisticRegression()
# ฝึกโมเดล
model.fit(X_train, y_train)
ขั้นตอนที่ 5: ทำนายและประเมินผลโมเดล
หลังจากฝึกโมเดลแล้ว เราจะทดสอบโมเดลกับชุดทดสอบและประเมินความแม่นยำ:
from sklearn.metrics import accuracy_score
# ทำนายผล
y_pred = model.predict(X_test)
print("Predicted class:", y_pred)
# ประเมินความแม่นยำ
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
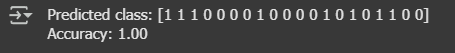
นอกจากนี้ เรายังสามารถดูค่า coefficients และ intercept ของโมเดลได้:
print("Coefficients:", model.coef_)
print("Intercept:", model.intercept_)
![]()
จากตัวอย่างนี้ เราจะได้ว่า ถ้าต้องการสร้าง Logistic Regression Model เพื่อทำนาย สายพันธุ์ของดอกไม้ (0 = setosa, 1 = versicolor) โดยใช้ 2 คุณลักษณะ ได้แก่ ความยาวและความกว้างของกลีบดอก (petal length และ petal width) เราจะได้ผลลัพท์เป็นสายพันธุ์ออกมา Predicted class: [1 1 1 0 0 0 0 1 0 0 0 0 1 0 1 0 1 1 0 0]
โดยมี Acuracy อยู่ที่ 100%
Logistic Regression เป็นอัลกอริธึมที่เรียบง่ายแต่มีประสิทธิภาพสำหรับการแก้ปัญหาการจำแนกประเภทแบบ Binary Classification และยังเป็นพื้นฐานที่สำคัญในการทำความเข้าใจอัลกอริธึมที่ซับซ้อนมากขึ้น การทดลองกับชุดข้อมูลอื่นๆ และการปรับเปลี่ยน parameters จะช่วยให้คุณมีความเข้าใจและสามารถประยุกต์ใช้ Logistic Regression ได้อย่างมีประสิทธิภาพมากยิ่งขึ้น
ตัวอย่างเพิ่มเติม
ใช้ชุดข้อมูล Wine dataset https://sklearner.com/scikit-learn-load_wine/
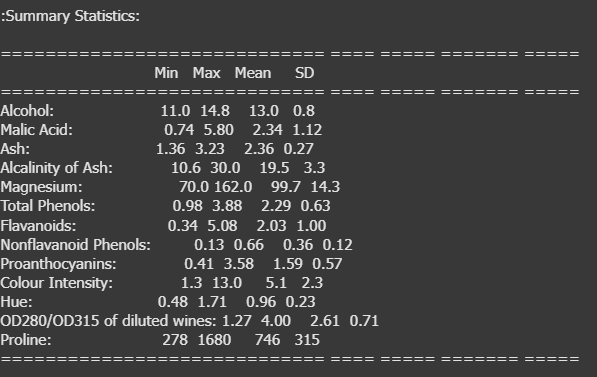
ข้อมูลชุดนี้มีทั้งหมด 178 แถว (ไวน์ 178 ตัวอย่าง) ประกอบด้วย 13 features และ 1 target class ซึ่งบอกประเภทของไวน์ โดยในตัวอย่างนี้ข้อมูลมี 3 ประเภท (0, 1, 2) สำหรับการจำแนกแบบ multiclass classification
ข้อมูลประกอบด้วย 14 columns ดังนี้:
alcohol – ปริมาณแอลกอฮอล์
malic_acid – กรดมาลิก
ash – ปริมาณเถ้า
alcalinity_of_ash – ความเป็นด่างของเถ้า
magnesium – ปริมาณแมกนีเซียม
total_phenols – ปริมาณฟีนอลทั้งหมด
flavanoids – ปริมาณฟลาโวนอยด์
nonflavanoid_phenols – ปริมาณฟีนอลที่ไม่ใช่ฟลาโวนอยด์
proanthocyanins – ปริมาณโพรแอนโทไซยานิน
color_intensity – ความเข้มของสี
hue – ค่าฮิว
od280/od315_of_diluted_wines – อัตราส่วน OD280/OD315 ของไวน์เจือจาง
proline – ปริมาณโพรลีน
target – ประเภทของไวน์ (0, 1, 2)
ขั้นตอนที่ 1: นำเข้าข้อมูล
from sklearn import datasets
# โหลดชุดข้อมูล Wine
wine = datasets.load_wine()
ขั้นตอนที่ 2: สำรวจและเตรียมข้อมูล
# สำรวจข้อมูลเบื้องต้น
# สำรวจข้อมูลเบื้องต้น
print("Keys of the dataset:", wine.keys())
print("\nDescription of the dataset:\n", wine['DESCR'] + "...")
print("\nFeature names:", wine['feature_names'])
print("Target names:", wine['target_names'])
# ข้อมูลและเป้าหมาย
X = wine.data
y = wine.target
ผลลัพท์
ขั้นตอนที่ 3: แบ่งข้อมูลเป็นชุดฝึกสอนและชุดทดสอบ
เราจะแบ่งข้อมูลออกเป็นสองส่วน: ชุดฝึกสอน (training set) และชุดทดสอบ (test set) โดยใช้สัดส่วน 80:20
from sklearn.model_selection import train_test_split
# แบ่งข้อมูล 80% สำหรับฝึกสอน และ 20% สำหรับทดสอบ โดยกำหนด random_state เพื่อให้ผลลัพธ์เหมือนเดิมทุกครั้ง
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
ขั้นตอนที่ 4: สร้างและฝึกโมเดล Logistic Regression
เราจะใช้ไลบรารี scikit-learn ในการสร้างและฝึกโมเดล Logistic Regression:
from sklearn.linear_model import LogisticRegression
# สร้างโมเดล
model = LogisticRegression()
# ฝึกโมเดล
model.fit(X_train, y_train)
ขั้นตอนที่ 5: ทำนายและประเมินผลโมเดล
หลังจากฝึกโมเดลแล้ว เราจะทดสอบโมเดลกับชุดทดสอบและประเมินความแม่นยำ:
# ทำนายผลลัพธ์บนชุดข้อมูลทดสอบ
y_pred = model.predict(X_test)
print("\nPredicted classes on test set:", y_pred[:20])
print("Actual classes on test set: ", y_test[:20])
# ประเมินความแม่นยำของโมเดล
accuracy = accuracy_score(y_test, y_pred)
print(f'\nAccuracy of Logistic Regression on Wine Dataset: {accuracy:.2f}')
# แสดง Coefficients และ Intercept ของโมเดล
print("\nCoefficients shape:", model.coef_.shape)
print("Intercept shape:", model.intercept_.shape)
print("\nCoefficients (for each class):")
for i, coef in enumerate(model.coef_):
print(f"Class {i}: {coef[:5]}...") # แสดง coefficients 5 ตัวแรกสำหรับแต่ละคลาส
print("\nIntercepts (for each class):", model.intercept_)
ผลลัพท์
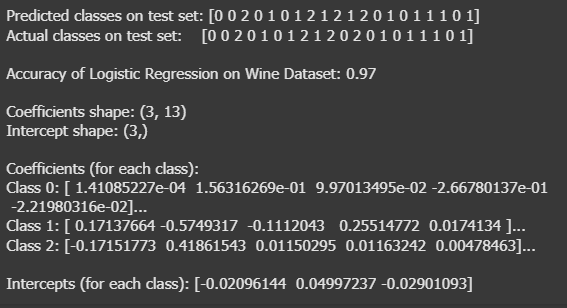
จะเห็นได้ว่าตัวอย่างเพิ่มเติมที่เราเอานำมานั้น ทำนาย ประเภทของไวน์ (0, 1, 2) โดยใช้ 13 คุณลักษณะ ซึ่งเป็นตัวอย่าง dataset ที่ใหญ่กว่า dataset ก่อนหน้าจะเห็นว่าค่า Acuracy ในครั้งนี้อยู่ที่ 97% แสดงให้เห็นว่าการใช้ Logistic Regression ค่าความถูกต้องจะขึ้นอยู่กับ ขนาดของ ข้อมูล และ ปริมาณ ปัจจัยที่ใช้ในการทดสอบ ครับผม