



























![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)








































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)








![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)





























































































































LLM Search Boost: ReZero Rewards Retry After Initial RAG Failures
This is a Plain English Papers summary of a research paper called LLM Search Boost: ReZero Rewards Retry After Initial RAG Failures. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Introduction: The Problem of Initial Search Failures in RAG Retrieval-Augmented Generation (RAG) has emerged as a powerful approach for enabling Large Language Models (LLMs) to access external knowledge sources. This ability helps overcome limitations in the models' pre-trained knowledge, allowing them to retrieve and integrate up-to-date or domain-specific information. However, RAG systems face a critical challenge: their effectiveness depends heavily on the quality of the initial search query. Current approaches to improving RAG typically focus on refining query formulation or enhancing reasoning over retrieved results. These methods overlook a fundamental aspect of effective information seeking - persistence when initial attempts fail. When humans search for information, we rarely give up after one unsuccessful attempt. Instead, we try again with different queries until we find what we need. The ReZero (Retry-Zero) framework addresses this gap by explicitly rewarding the act of trying again. This novel reinforcement learning approach directly incentivizes the model to explore alternative queries after an initial unsuccessful search rather than prematurely giving up or producing hallucinated responses. Figure 1: ReZero receives a reward signal for retrying after a failed search attempt. The results are compelling: ReZero achieved 46.88% accuracy compared to a 25% baseline, demonstrating that simply encouraging persistence can substantially improve performance on knowledge-intensive tasks. By rewarding the model for trying one more time, ReZero enhances LLM robustness in complex information-seeking scenarios where initial queries often prove insufficient. Related Work Modern RAG Systems: From Single to Multi-Step Retrieval Retrieval-Augmented Generation has evolved from simple single-retrieval approaches to more sophisticated multi-step systems. Early RAG implementations typically performed a single retrieval operation before generating a response. However, complex information needs often require multiple interactions with knowledge sources. Methods like Self-Ask and IRCoT integrate Chain-of-Thought reasoning with iterative retrieval, allowing models to decompose questions and gather information incrementally. These approaches improve reasoning over retrieved context but often rely on sophisticated prompting or assume the model inherently knows when and how to retrieve effectively. ReZero differs from these approaches by focusing on the robustness of the retrieval interaction itself. Rather than assuming perfect retrieval on the first attempt, it explicitly encourages models to retry when initial searches fail. This represents a dimension less explored in iterative RAG frameworks, which typically focus on sequential information gathering rather than correcting failed searches. Improving RAG with Learning and Search Methods Recent research has explored learning-based methods to enhance RAG systems' reasoning capabilities. Approaches like ReARTeR employ Process Reward Models to score intermediate reasoning steps and Process Explanation Models to provide critiques for refinement. While ReARTeR focuses on improving the quality and reliability of reasoning given retrieved information, ReZero concentrates on the search interaction itself - specifically encouraging retry behavior when initial attempts fail. DeepRetrieval takes a query-centric approach, using reinforcement learning to train LLMs to generate queries that maximize retrieval performance metrics like Recall and NDCG. It optimizes for the quality of a single, potentially refined query attempt. In contrast, ReZero complements this by rewarding the process of retrying, encouraging the model to make multiple attempts when necessary rather than focusing solely on crafting the perfect initial query. These complementary approaches highlight different aspects of improving RAG systems - query quality, reasoning quality, and now with ReZero, search persistence. Combining these approaches could lead to even more robust search and reasoning capabilities in LLMs. Reinforcement Learning for Aligning LLMs Reinforcement Learning has become central to aligning LLMs with human preferences (RLHF) and enhancing specific capabilities like reasoning and tool use. Methods like ReFT use RL to fine-tune LLMs for reasoning tasks based on outcome or process rewards. While prior work has used RL to optimize reasoning steps or query generation, ReZero introduces a novel application by incorporating a reward signal specifically tied to the retry action in a search context. This aligns with the broader goal of using RL to encourage desirable behaviors, but targets the specific behavior of pers
This is a Plain English Papers summary of a research paper called LLM Search Boost: ReZero Rewards Retry After Initial RAG Failures. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Introduction: The Problem of Initial Search Failures in RAG
Retrieval-Augmented Generation (RAG) has emerged as a powerful approach for enabling Large Language Models (LLMs) to access external knowledge sources. This ability helps overcome limitations in the models' pre-trained knowledge, allowing them to retrieve and integrate up-to-date or domain-specific information. However, RAG systems face a critical challenge: their effectiveness depends heavily on the quality of the initial search query.
Current approaches to improving RAG typically focus on refining query formulation or enhancing reasoning over retrieved results. These methods overlook a fundamental aspect of effective information seeking - persistence when initial attempts fail. When humans search for information, we rarely give up after one unsuccessful attempt. Instead, we try again with different queries until we find what we need.
The ReZero (Retry-Zero) framework addresses this gap by explicitly rewarding the act of trying again. This novel reinforcement learning approach directly incentivizes the model to explore alternative queries after an initial unsuccessful search rather than prematurely giving up or producing hallucinated responses.
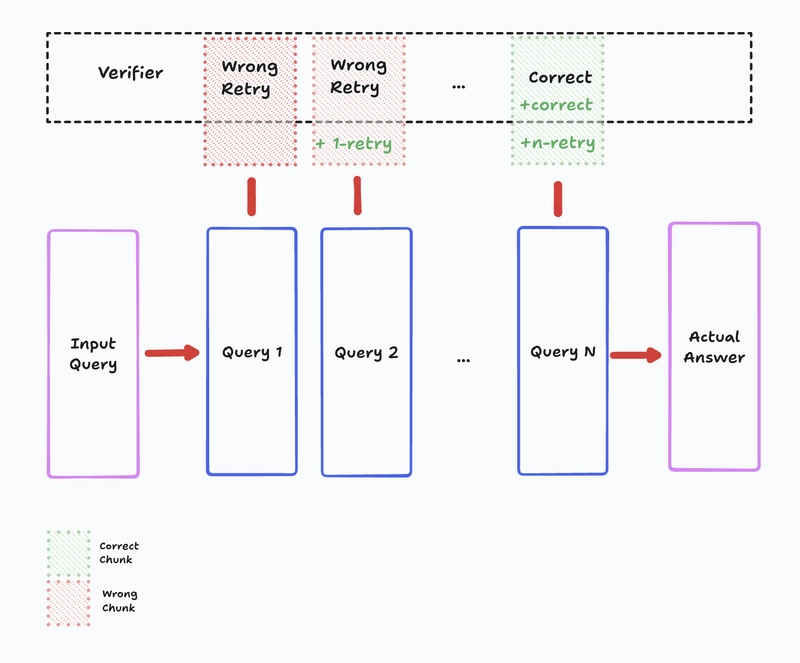
Figure 1: ReZero receives a reward signal for retrying after a failed search attempt.
The results are compelling: ReZero achieved 46.88% accuracy compared to a 25% baseline, demonstrating that simply encouraging persistence can substantially improve performance on knowledge-intensive tasks. By rewarding the model for trying one more time, ReZero enhances LLM robustness in complex information-seeking scenarios where initial queries often prove insufficient.
Related Work
Modern RAG Systems: From Single to Multi-Step Retrieval
Retrieval-Augmented Generation has evolved from simple single-retrieval approaches to more sophisticated multi-step systems. Early RAG implementations typically performed a single retrieval operation before generating a response. However, complex information needs often require multiple interactions with knowledge sources.
Methods like Self-Ask and IRCoT integrate Chain-of-Thought reasoning with iterative retrieval, allowing models to decompose questions and gather information incrementally. These approaches improve reasoning over retrieved context but often rely on sophisticated prompting or assume the model inherently knows when and how to retrieve effectively.
ReZero differs from these approaches by focusing on the robustness of the retrieval interaction itself. Rather than assuming perfect retrieval on the first attempt, it explicitly encourages models to retry when initial searches fail. This represents a dimension less explored in iterative RAG frameworks, which typically focus on sequential information gathering rather than correcting failed searches.
Improving RAG with Learning and Search Methods
Recent research has explored learning-based methods to enhance RAG systems' reasoning capabilities. Approaches like ReARTeR employ Process Reward Models to score intermediate reasoning steps and Process Explanation Models to provide critiques for refinement. While ReARTeR focuses on improving the quality and reliability of reasoning given retrieved information, ReZero concentrates on the search interaction itself - specifically encouraging retry behavior when initial attempts fail.
DeepRetrieval takes a query-centric approach, using reinforcement learning to train LLMs to generate queries that maximize retrieval performance metrics like Recall and NDCG. It optimizes for the quality of a single, potentially refined query attempt. In contrast, ReZero complements this by rewarding the process of retrying, encouraging the model to make multiple attempts when necessary rather than focusing solely on crafting the perfect initial query.
These complementary approaches highlight different aspects of improving RAG systems - query quality, reasoning quality, and now with ReZero, search persistence. Combining these approaches could lead to even more robust search and reasoning capabilities in LLMs.
Reinforcement Learning for Aligning LLMs
Reinforcement Learning has become central to aligning LLMs with human preferences (RLHF) and enhancing specific capabilities like reasoning and tool use. Methods like ReFT use RL to fine-tune LLMs for reasoning tasks based on outcome or process rewards.
While prior work has used RL to optimize reasoning steps or query generation, ReZero introduces a novel application by incorporating a reward signal specifically tied to the retry action in a search context. This aligns with the broader goal of using RL to encourage desirable behaviors, but targets the specific behavior of persistence in information retrieval.
The concept of iterative improvement appears in self-correction methods where LLMs critique and revise their own outputs. However, these approaches typically focus on refining the generated text based on internal checks or external feedback. ReZero differs by encouraging retrying the interaction with the external search tool, addressing potential failures at the information-gathering stage rather than the output generation stage.
By leveraging RL to incentivize persistence in search, ReZero occupies a unique space in research learning to reason and search with LLMs.
Methodology: The ReZero Framework
ReZero Overview: Encouraging Persistence in Search
ReZero is a reinforcement learning framework designed to enhance LLMs' search capabilities in RAG systems. It builds on recent advances in RL for reasoning tasks and responds to findings suggesting RL fosters better generalization compared to supervised fine-tuning.
The core innovation of ReZero is its explicit incentivization of persistence. Using Group Relative Policy Optimization (GRPO), the framework rewards the model for retrying search queries when initial attempts fail to yield sufficient information. This mimics human information-seeking behavior, where we typically try different approaches when our first search doesn't produce the desired results.
The name "ReZero" (Retry-Zero) reflects the framework's focus on trying one more time after an initial zero-success search attempt. This simple yet powerful concept addresses a fundamental limitation in current RAG systems: their frequent inability to recover from poor initial queries.
The Reinforcement Learning Framework
ReZero operates within a search environment where the LLM interacts with an external retrieval system. The RL loop involves four standard components:
State: The current conversation history, including the user's prompt, the LLM's previous responses (with tags like
Action: The LLM's generation, which could be an internal thought process (
Reward: A scalar signal derived from evaluating the LLM's outputs against predefined criteria using multiple reward functions that collectively act as a self-teacher.
Policy: The LLM's strategy for generating actions, fine-tuned using GRPO to maximize cumulative reward.
This framework creates a complete learning loop that trains the model to make more effective decisions about when and how to search for information.
Specialized Reward Functions
ReZero employs six distinct reward functions to provide comprehensive training signals:
reward_correctness: Evaluates the final answer's accuracy against ground truth using the model itself as a self-judge (LLM-as-a-Judge).
reward_format: Ensures adherence to the required conversational format and tag usage, outputting a binary reward.
reward_retry: The core innovation that encourages persistence by assigning a positive reward for each subsequent search query after the first one. Crucially, this reward is conditional on task completion - it's only awarded if the model eventually produces a complete answer.
reward_em_chunk: Verifies if the correct information chunk was retrieved by comparing retrieved content against ground truth using exact matching.
reward_search_strategy: Evaluates the quality of the search process by checking adherence to a desired flow: broad initial search, analysis of results, refined follow-up searches, and synthesis of findings into an answer.
reward_search_diversity: Assesses the variety in search queries, rewarding semantic dissimilarity between queries and effective use of search operators while penalizing repetition.
These reward functions collectively guide the policy toward correctness, format adherence, effective information gathering, and critically, search persistence. By designing rewards that specifically target retry behavior, ReZero enhances LLMs' grounding capabilities through trying again.
The Training Process
The LLM is fine-tuned directly from a pre-trained base model using reinforcement learning, specifically employing the Group Relative Policy Optimization (GRPO) algorithm. The training operates within an interactive framework involving a search engine acting as a verifier.
The process follows these key steps:
Iterative Interaction Loop (Rollout): The LLM interacts with the search engine by generating a response sequence that can include search queries. The search engine processes these queries and returns information chunks. Crucially, the model might repeat this query-retrieval process within the same generation sequence before producing a final answer.
Reward Calculation: Upon completion of the generation sequence, the total reward is computed using the suite of reward functions. This aggregate reward reflects the overall quality and effectiveness of the sequence, including the persistence demonstrated through retries.
Policy Update (GRPO): The calculated rewards for multiple sampled trajectories are fed into the GRPO algorithm, which updates the LLM's parameters to increase the probability of generating higher-reward sequences.
Noise Injection for Robustness: To strengthen the model's ability to generalize its retry strategy, noise is introduced during training at the vector database level. This simulates imperfect retrieval, encouraging the LLM to learn robust retry mechanisms rather than overfitting to scenarios where the first search always yields perfect results.
This training process directly fine-tunes the base LLM, teaching it not only to answer correctly but also to strategically and persistently use the search tool, even when facing retrieval imperfections. This approach helps improve zero-shot LLM re-ranking abilities by enhancing the model's robustness to imperfect initial retrieval.
Experiments and Results
The experimental setup implemented the ReZero framework using Group Relative Policy Optimization (GRPO) to fine-tune a pre-trained language model. The training utilized the unsloth library and ran within an interactive environment involving a search engine as a verifier.
For these experiments, the Apollo 3 mission dataset was used, divided into 341 distinct data chunks with 32 chunks reserved for evaluation. The training ran for 1000 steps (approximately 3 epochs) on a single NVIDIA H200 GPU using Llama3.2-3B-Instruct as the base model.
To isolate and assess the impact of the proposed reward_retry mechanism, two model configurations were compared:
Baseline: Trained using three reward functions: reward_correctness, reward_format, and reward_emchunk, but lacking the explicit incentive to retry search queries.
ReZero (with reward_retry): The full implementation of the proposed framework, trained with all reward functions including the critical reward_retry component designed to encourage persistence.
Both models started from the same pre-trained weights and underwent the same fundamental RL training procedure, differing only in the inclusion of the reward_retry signal.
The results showed a dramatic difference in performance. The ReZero model achieved a peak accuracy of 46.88% at 250 training steps. In contrast, the Baseline model reached a maximum accuracy of only 25.00% at 350 steps. Not only did ReZero achieve significantly higher peak performance, but it also demonstrated a faster initial learning rate.
Interestingly, both models exhibited a decline in accuracy after reaching their peaks, eventually dropping to 0% accuracy in later training steps. This suggests potential challenges with RL training stability that warrant further investigation.
The substantial difference in peak accuracy (46.88% vs. 25.00%) provides strong evidence that explicitly rewarding retry behavior via the reward_retry function significantly enhances the model's ability to effectively utilize search tools and arrive at correct answers, particularly when initial queries prove insufficient.
Discussion: Implications and Limitations
The experimental results provide compelling evidence for the efficacy of the ReZero framework, particularly the contribution of the reward_retry component. The most striking finding is the substantial performance gap between the ReZero model and the Baseline configuration. ReZero achieved a peak accuracy of 46.88%, nearly double the 25.00% peak accuracy of the Baseline model that lacked the retry incentive.
This significant difference validates the central hypothesis: explicitly rewarding the act of retrying a search query enhances the LLM's ability to navigate information retrieval challenges. This mirrors aspects of human information-seeking behavior, where initial attempts often require refinement or alternative approaches.
The faster initial learning rate observed in the ReZero model suggests that encouraging persistence accelerates the model's adaptation to effective search strategies. The use of noise injection during training likely amplified scenarios where initial searches failed, providing more effective learning signals for the reward_retry mechanism.
However, the performance trajectory also reveals important challenges. Both models exhibited a notable decline in accuracy after reaching their peaks, eventually collapsing to 0% accuracy on the evaluation set. This phenomenon suggests that current limitations may lie less in the concept of rewarding retries and more in the specifics of the RL training process itself.
Potential factors contributing to this decline include:
- Overfitting to the training data chunks
- Instability inherent in the GRPO algorithm over extended training
- Suboptimal balancing of different reward components
A significant limitation of this study is its reliance on a single dataset derived from the Apollo 3 mission. While this provided a controlled environment for comparison, it represents a relatively narrow domain. The generalizability of the observed performance gains to broader knowledge domains remains an open question.
Future research should prioritize:
- Evaluating ReZero across a wider range of datasets spanning multiple domains
- Investigating methods to stabilize the RL training process
- Exploring variations of the reward_retry function
- Conducting qualitative analysis of generated search queries
- Analyzing the practical trade-off between accuracy gains and increased latency
- Combining ReZero with complementary techniques like advanced query rewriting or sophisticated reasoning methods
Addressing these limitations and research directions could further enhance the robustness and applicability of the ReZero approach.
Conclusion: The Value of Trying One More Time
ReZero addresses the challenge of enhancing RAG system robustness, particularly when initial search queries fail to retrieve necessary information. By explicitly incentivizing persistence in the search process through a specific reward_retry component, ReZero encourages LLMs to attempt subsequent searches following unsuccessful initial attempts.
Experiments on the Apollo 3 mission dataset demonstrated the significant impact of this approach. The ReZero model achieved a peak accuracy of 46.88%, substantially outperforming the 25.00% peak accuracy of a baseline model trained without the retry incentive. This strongly supports the hypothesis that explicitly rewarding the act of retrying enhances an LLM's ability to overcome initial search failures.
Despite promising results, the observed decline in performance after reaching peak accuracy highlights challenges related to RL training stability. The evaluation was also confined to a single domain, limiting claims of broad generalizability.
Future research should validate ReZero across a wider range of datasets, stabilize the RL training dynamics, explore refinements to the reward_retry function, conduct qualitative analyses of learned retry strategies, investigate latency trade-offs, and explore integration with complementary RAG techniques.
ReZero offers a valuable contribution by demonstrating that directly rewarding persistence—the willingness to "try one more time"—can significantly improve LLMs' effectiveness in complex information-seeking scenarios. This work highlights the potential of incorporating mechanisms that mirror human problem-solving strategies into AI systems operating within RAG frameworks, reinforcing that sometimes the most important factor in successful information retrieval is simply the determination to try again.


