

























































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)




































































































































































































![Blue Archive tier list [April 2025]](https://media.pocketgamer.com/artwork/na-33404-1636469504/blue-archive-screenshot-2.jpg?#)

































.png?#)







.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)





























.webp?#)















































































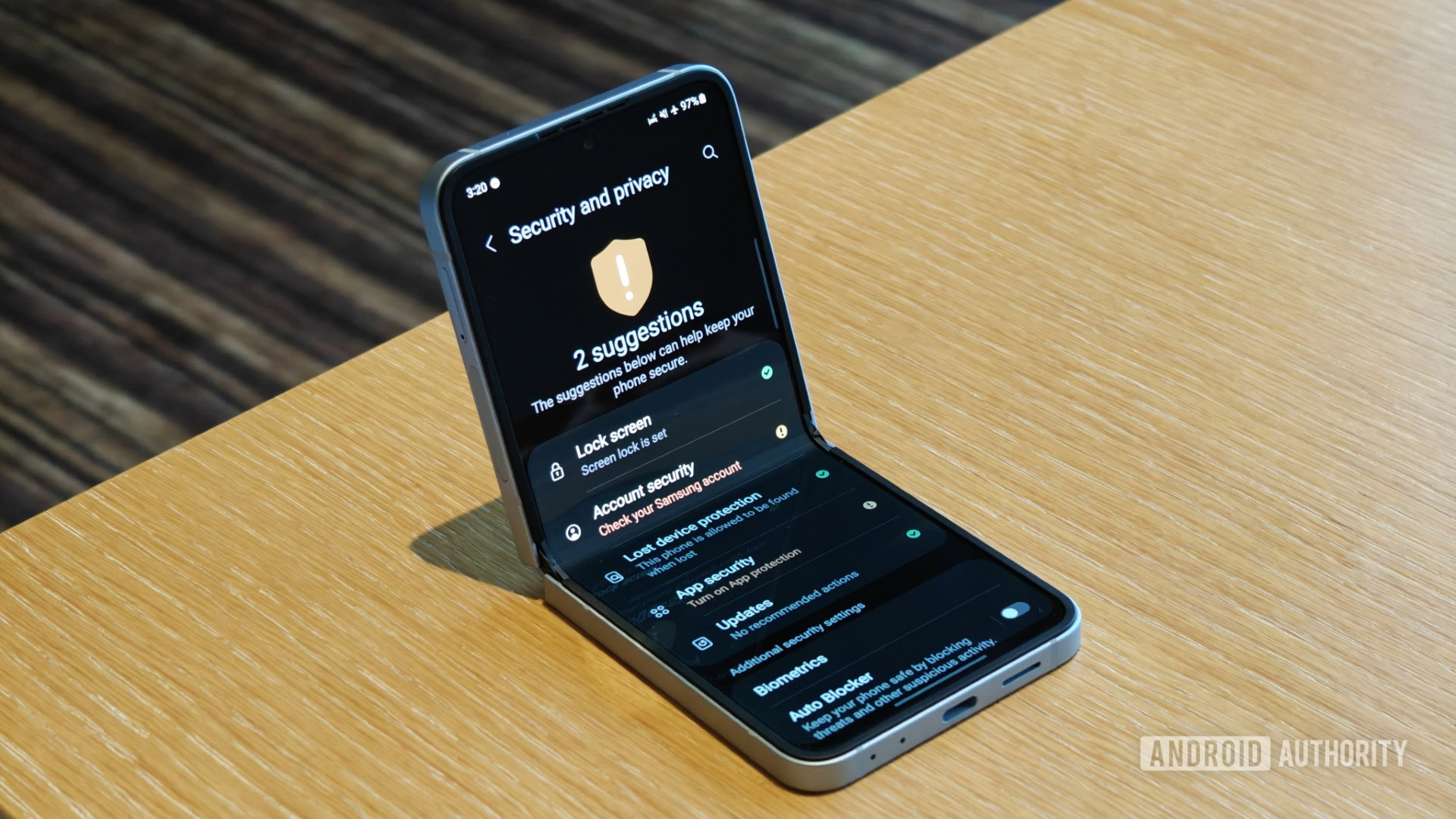

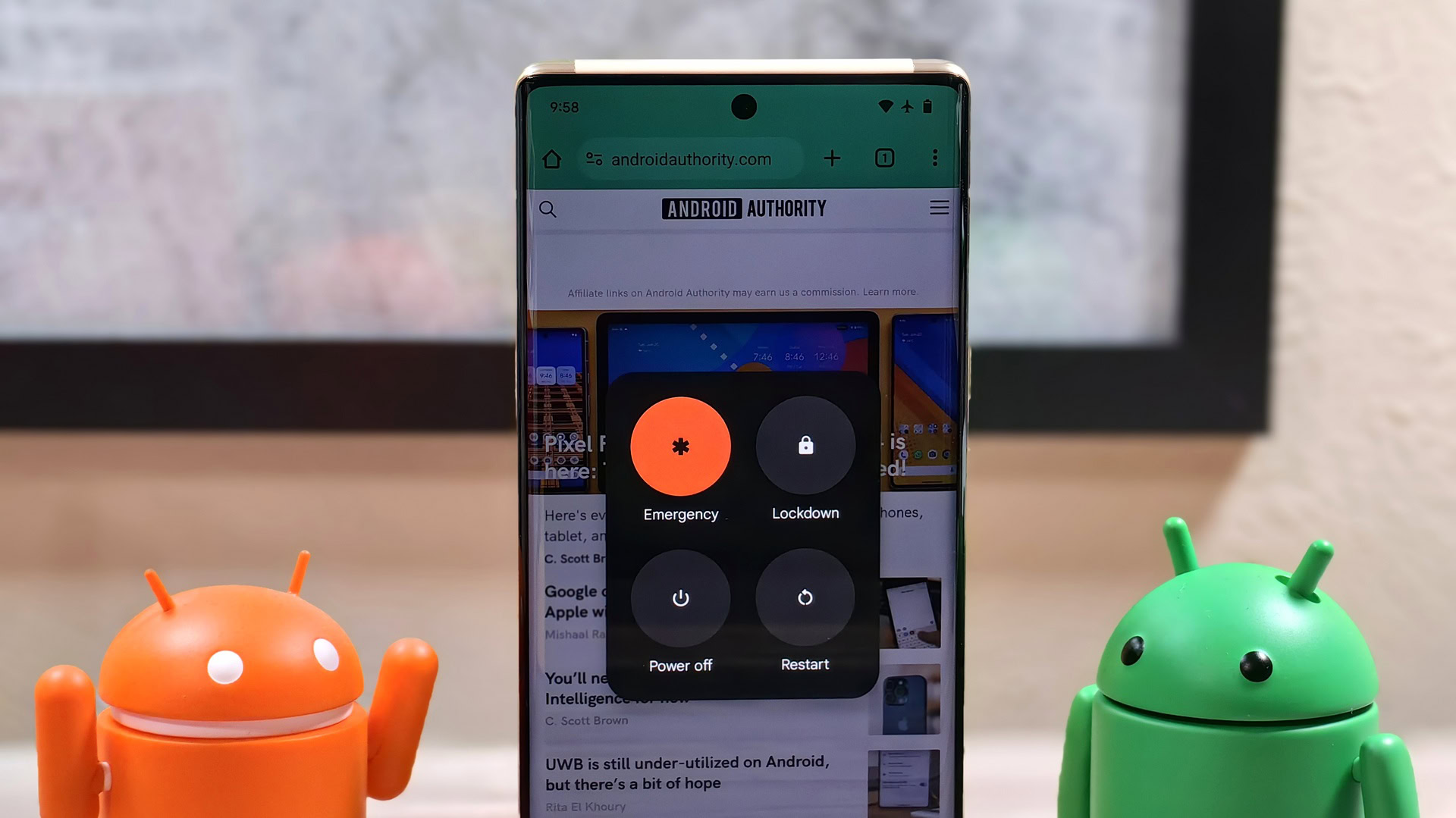



![[Update: Optional] Google rolling out auto-restart security feature to Android](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-2.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)












![Apple Releases iOS 18.4.1 and iPadOS 18.4.1 [Download]](https://www.iclarified.com/images/news/97043/97043/97043-640.jpg)
![Apple Releases visionOS 2.4.1 for Vision Pro [Download]](https://www.iclarified.com/images/news/97046/97046/97046-640.jpg)
![Apple Vision 'Air' Headset May Feature Titanium and iPhone 5-Era Black Finish [Rumor]](https://www.iclarified.com/images/news/97040/97040/97040-640.jpg)




















































































































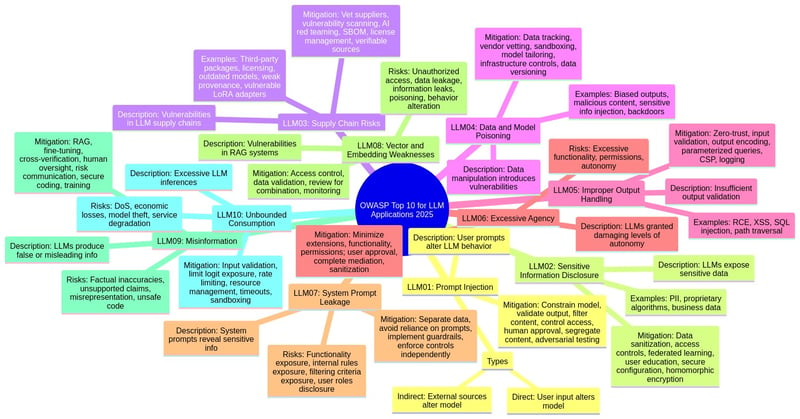
LLM Agents Fail Key Skills: New Test Reveals Human-AI Performance Gap
This is a Plain English Papers summary of a research paper called LLM Agents Fail Key Skills: New Test Reveals Human-AI Performance Gap. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview Multi-Mission Tool Bench provides a new framework for evaluating LLM agents Tests agent robustness across related but distinct missions Features 9 scenarios with multiple missions requiring tool use Measures task completion rate, efficiency, and solution quality Tests for critical agent abilities: adaptation, memory, and exploration Shows significant performance gaps between human and LLM agents Plain English Explanation The Multi-Mission Tool Bench is like an obstacle course designed to test how well AI agents can handle a series of related tasks. Imagine you're testing a chef by asking them to make pasta, t... Click here to read the full summary of this paper
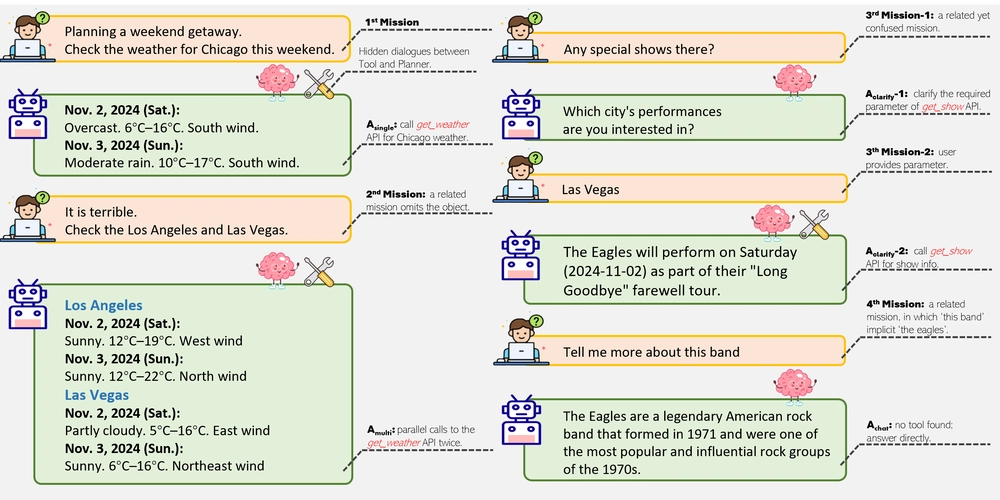
This is a Plain English Papers summary of a research paper called LLM Agents Fail Key Skills: New Test Reveals Human-AI Performance Gap. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- Multi-Mission Tool Bench provides a new framework for evaluating LLM agents
- Tests agent robustness across related but distinct missions
- Features 9 scenarios with multiple missions requiring tool use
- Measures task completion rate, efficiency, and solution quality
- Tests for critical agent abilities: adaptation, memory, and exploration
- Shows significant performance gaps between human and LLM agents
Plain English Explanation
The Multi-Mission Tool Bench is like an obstacle course designed to test how well AI agents can handle a series of related tasks. Imagine you're testing a chef by asking them to make pasta, t...