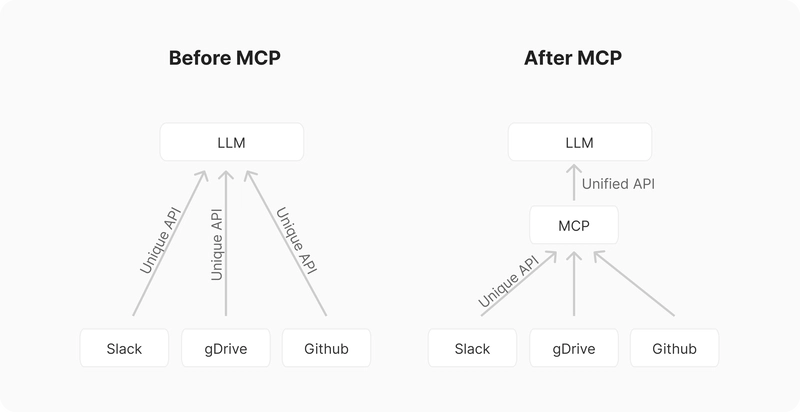
![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)




















































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)























































































































_roibu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




 CISO’s Core Focus.webp?#)






































































































![M4 MacBook Air Drops to Just $849 - Act Fast! [Lowest Price Ever]](https://www.iclarified.com/images/news/97140/97140/97140-640.jpg)
![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)
































































































Introduction to Presto: Open Source SQL Query Engine that's changing Big Data Analytics
In today's data-driven world, organizations face a constant challenge: how to analyse massive datasets quickly and efficiently without moving data between disparate systems. Presto, an open-source distributed SQL query engine that's revolutionizing how we approach big data analytics. What is Presto? Presto is an open-source distributed SQL query engine designed for fast interactive analysis of data at any scale. Unlike traditional database systems that require data to be loaded into their proprietary storage format, Presto can query data directly where it lives – be it Hadoop, AWS S3, Google Cloud Storage, Relational Databases, NoSQL systems, or even custom data sources. Presto Architecture allows you: Query data across multiple sources without ETL (Extract, Transform & Load). Process petabytes of data with sub-second query response times. Use familiar ANSI SQL syntax for complex analytics. Scale resources independently of your data volume. The Origin Story: From Facebook to Global Adoption Presto was born in 2012 at Facebook (now Meta) when engineers faced a challenge: Facebook's data analysts were waiting hours for their Hive queries to complete, severely limiting their productivity. The team set out to build a new query engine that could provide interactive query speeds on Facebook's massive 300PB data warehouse. Within a few months, they had a prototype that was 10x faster than Hive for many workloads, and by 2013, Facebook open-sourced Presto to the world. Since then, Presto has been adopted by technology giants like Uber, Netflix, Twitter, and Airbnb, as well as countless enterprises across industries. Coordinator Node (
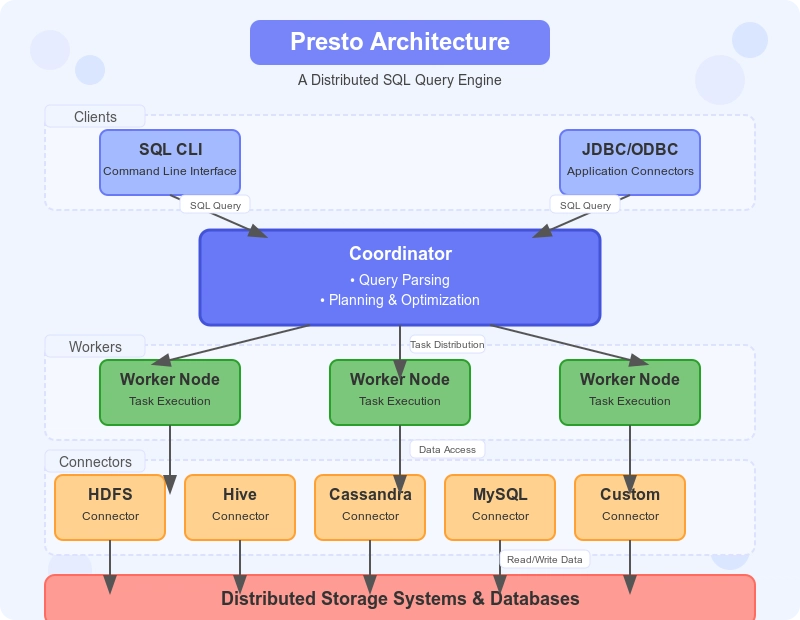
In today's data-driven world, organizations face a constant challenge: how to analyse massive datasets quickly and efficiently without moving data between disparate systems. Presto, an open-source distributed SQL query engine that's revolutionizing how we approach big data analytics.
What is Presto?
Presto is an open-source distributed SQL query engine designed for fast interactive analysis of data at any scale. Unlike traditional database systems that require data to be loaded into their proprietary storage format, Presto can query data directly where it lives – be it Hadoop, AWS S3, Google Cloud Storage, Relational Databases, NoSQL systems, or even custom data sources.
Presto Architecture allows you:
- Query data across multiple sources without ETL (Extract, Transform & Load).
- Process petabytes of data with sub-second query response times.
- Use familiar ANSI SQL syntax for complex analytics.
- Scale resources independently of your data volume.
The Origin Story: From Facebook to Global Adoption
Presto was born in 2012 at Facebook (now Meta) when engineers faced a challenge: Facebook's data analysts were waiting hours for their Hive queries to complete, severely limiting their productivity.
The team set out to build a new query engine that could provide interactive query speeds on Facebook's massive 300PB data warehouse. Within a few months, they had a prototype that was 10x faster than Hive for many workloads, and by 2013, Facebook open-sourced Presto to the world.
Since then, Presto has been adopted by technology giants like Uber, Netflix, Twitter, and Airbnb, as well as countless enterprises across industries.
Coordinator Node (