


































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)
























































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)























































































































_roibu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




 CISO’s Core Focus.webp?#)







































































































![M4 MacBook Air Drops to Just $849 - Act Fast! [Lowest Price Ever]](https://www.iclarified.com/images/news/97140/97140/97140-640.jpg)
![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)





























































































Index Only Scan on JSON Documents, with Covering and Multi-Key Indexes in MongoDB
Storing JSON documents in a SQL database does not make it a document database. The strength of any database lies in its indexing capabilities, and SQL databases, even with JSON datatypes, lack the flexibility of document databases, particularly when dealing with arrays in an embedded One-to-Many relationships. In SQL databases, normalized tables are first-class citizens, with single-key indexes optimized for handling equality and range filters (WHERE), sorting (ORDER BY), and projection coverage (SELECT) for individual tables. To avoid joining before filtering, a denormalized model is preferred when those operations involve multiple tables. While SQL databases can store documents, including arrays for One-to-Many relationships, working with arrays in JSON necessitates the use of inverted indexes like PostgreSQL's GIN, which do not cover range filters, sorting, and projection like regular indexes. In contrast, MongoDB treats documents as the core of its data model. Its indexing mechanisms naturally extend to handle documents and their arrays, retaining functionality for filtering, sorting, and projection coverage, as regular indexes can hangle multiple keys per documents. In previous posts, we examined how a multi-key index supports sort operations. Now, let's explore the conditions under which a query projection is covered by the index, eliminating the need to fetch the document from the collection. Here is the table of content of the tests: With default projection: IXSCAN ➤ FETCH Partial projection: IXSCAN ➤ FETCH ➤ PROJECTION_SIMPLE Full projection: IXSCAN ➤ PROJECTION_COVERED Query on a single-key entry: IXSCAN ➤ PROJECTION_COVERED Query on a multi-key entry: IXSCAN ➤ FETCH ➤ PROJECTION_SIMPLE Projection of "_id" : IXSCAN ➤ FETCH ➤ PROJECTION_SIMPLE Projection of "$recordId" : IXSCAN ➤ PROJECTION_DEFAULT Here is a collection of friends, with their first name, last name, and phone number. db.friends.insertMany([ { firstName: "Rachel", lastName: "Green", phoneNumber: "555-1234" }, { firstName: "Ross", lastName: "Geller", phoneNumber: "555-2345" }, { firstName: "Monica", lastName: "Geller", phoneNumber: "555-3456" }, { firstName: "Chandler", lastName: "Bing", phoneNumber: "555-4567" }, { firstName: "Joey", lastName: "Tribbiani", phoneNumber: "555-6789" }, { firstName: "Janice", lastName: "Hosenstein", phoneNumber: "555-7890" }, { firstName: "Gunther", lastName: "Centralperk", phoneNumber: "555-8901" }, { firstName: "Carol", lastName: "Willick", phoneNumber: "555-9012" }, { firstName: "Susan", lastName: "Bunch", phoneNumber: "555-0123" }, { firstName: "Mike", lastName: "Hannigan", phoneNumber: "555-1123" }, { firstName: "Emily", lastName: "Waltham", phoneNumber: "555-2234" } ]) In any database, relational or document, implementing new use cases often requires an index for effective access patterns. For instance, for a reverse phone directory, I create an index where the key starts with the phone number. I add the names to the key in order to allow for index-only scans to benefit from the O(log n) scalability of B-Tree indexes: db.friends.createIndex( { phoneNumber:1, firstName:1, lastName:1 } ) To confirm that an index-only scan is occurring, I examine the execution plan specifically for PROJECTION_COVERED rather than FETCH With default projection: IXSCAN ➤ FETCH Due to its flexible schema, MongoDB cannot assume that all fields in every document within a collection are covered by the index. As a result, it must fetch the entire document: db.friends.find( { phoneNumber:"555-6789" } ).explain('executionStats').executionStats { executionSuccess: true, nReturned: 1, executionTimeMillis: 0, totalKeysExamined: 1, totalDocsExamined: 1, executionStages: { isCached: false, stage: 'FETCH', nReturned: 1, executionTimeMillisEstimate: 0, works: 2, advanced: 1, needTime: 0, needYield: 0, saveState: 0, restoreState: 0, isEOF: 1, docsExamined: 1, alreadyHasObj: 0, inputStage: { stage: 'IXSCAN', nReturned: 1, executionTimeMillisEstimate: 0, works: 2, advanced: 1, needTime: 0, needYield: 0, saveState: 0, restoreState: 0, isEOF: 1, keyPattern: { phoneNumber: 1, firstName: 1, lastName: 1 }, indexName: 'phoneNumber_1_firstName_1_lastName_1', isMultiKey: false, multiKeyPaths: { phoneNumber: [], firstName: [], lastName: [] }, isUnique: false, isSparse: false, isPartial: false, indexVersion: 2, direction: 'forward', indexBounds: { phoneNumber: [ '["555-6789", "555-6789"]' ], firstName: [ '[MinKey, MaxKey]' ], lastName: [ '[MinKey, MaxKey]' ] }, keysExamined: 1, seeks: 1, dupsTested: 0, dupsDropped: 0 } } } Looking at the result, I can see the "_id" which is stored in the document: db.friends.find( { phoneNu
Storing JSON documents in a SQL database does not make it a document database. The strength of any database lies in its indexing capabilities, and SQL databases, even with JSON datatypes, lack the flexibility of document databases, particularly when dealing with arrays in an embedded One-to-Many relationships.
In SQL databases, normalized tables are first-class citizens, with single-key indexes optimized for handling equality and range filters (WHERE), sorting (ORDER BY), and projection coverage (SELECT) for individual tables. To avoid joining before filtering, a denormalized model is preferred when those operations involve multiple tables.
While SQL databases can store documents, including arrays for One-to-Many relationships, working with arrays in JSON necessitates the use of inverted indexes like PostgreSQL's GIN, which do not cover range filters, sorting, and projection like regular indexes.
In contrast, MongoDB treats documents as the core of its data model. Its indexing mechanisms naturally extend to handle documents and their arrays, retaining functionality for filtering, sorting, and projection coverage, as regular indexes can hangle multiple keys per documents.
In previous posts, we examined how a multi-key index supports sort operations. Now, let's explore the conditions under which a query projection is covered by the index, eliminating the need to fetch the document from the collection.
Here is the table of content of the tests:
- With default projection: IXSCAN ➤ FETCH
- Partial projection: IXSCAN ➤ FETCH ➤ PROJECTION_SIMPLE
- Full projection: IXSCAN ➤ PROJECTION_COVERED
- Query on a single-key entry: IXSCAN ➤ PROJECTION_COVERED
- Query on a multi-key entry: IXSCAN ➤ FETCH ➤ PROJECTION_SIMPLE
- Projection of "_id" : IXSCAN ➤ FETCH ➤ PROJECTION_SIMPLE
- Projection of "$recordId" : IXSCAN ➤ PROJECTION_DEFAULT
Here is a collection of friends, with their first name, last name, and phone number.
db.friends.insertMany([
{ firstName: "Rachel", lastName: "Green", phoneNumber: "555-1234" },
{ firstName: "Ross", lastName: "Geller", phoneNumber: "555-2345" },
{ firstName: "Monica", lastName: "Geller", phoneNumber: "555-3456" },
{ firstName: "Chandler", lastName: "Bing", phoneNumber: "555-4567" },
{ firstName: "Joey", lastName: "Tribbiani", phoneNumber: "555-6789" },
{ firstName: "Janice", lastName: "Hosenstein", phoneNumber: "555-7890" },
{ firstName: "Gunther", lastName: "Centralperk", phoneNumber: "555-8901" },
{ firstName: "Carol", lastName: "Willick", phoneNumber: "555-9012" },
{ firstName: "Susan", lastName: "Bunch", phoneNumber: "555-0123" },
{ firstName: "Mike", lastName: "Hannigan", phoneNumber: "555-1123" },
{ firstName: "Emily", lastName: "Waltham", phoneNumber: "555-2234" }
])
In any database, relational or document, implementing new use cases often requires an index for effective access patterns. For instance, for a reverse phone directory, I create an index where the key starts with the phone number. I add the names to the key in order to allow for index-only scans to benefit from the O(log n) scalability of B-Tree indexes:
db.friends.createIndex(
{ phoneNumber:1, firstName:1, lastName:1 }
)
To confirm that an index-only scan is occurring, I examine the execution plan specifically for PROJECTION_COVERED rather than FETCH
With default projection: IXSCAN ➤ FETCH
Due to its flexible schema, MongoDB cannot assume that all fields in every document within a collection are covered by the index. As a result, it must fetch the entire document:
db.friends.find(
{ phoneNumber:"555-6789" }
).explain('executionStats').executionStats
{
executionSuccess: true,
nReturned: 1,
executionTimeMillis: 0,
totalKeysExamined: 1,
totalDocsExamined: 1,
executionStages: {
isCached: false,
stage: 'FETCH',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
docsExamined: 1,
alreadyHasObj: 0,
inputStage: {
stage: 'IXSCAN',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
keyPattern: { phoneNumber: 1, firstName: 1, lastName: 1 },
indexName: 'phoneNumber_1_firstName_1_lastName_1',
isMultiKey: false,
multiKeyPaths: { phoneNumber: [], firstName: [], lastName: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: {
phoneNumber: [ '["555-6789", "555-6789"]' ],
firstName: [ '[MinKey, MaxKey]' ],
lastName: [ '[MinKey, MaxKey]' ]
},
keysExamined: 1,
seeks: 1,
dupsTested: 0,
dupsDropped: 0
}
}
}
Looking at the result, I can see the "_id" which is stored in the document:
db.friends.find(
{ phoneNumber:"555-6789" }
)
[
{
_id: ObjectId('680d46a1672e2e146dd4b0c6'),
firstName: 'Joey',
lastName: 'Tribbiani',
phoneNumber: '555-6789'
}
]
I can remove it from the projection as I don't need it.
Partial projection: IXSCAN ➤ FETCH ➤ PROJECTION_SIMPLE
I add a projection to exclude the "_id" from the result, but it doesn't remove the FETCH that gets the document with all fields:
db.friends.find(
{ phoneNumber:"555-6789" }
, { "_id":0 }
).explain('executionStats').executionStats
{
executionSuccess: true,
nReturned: 1,
executionTimeMillis: 0,
totalKeysExamined: 1,
totalDocsExamined: 1,
executionStages: {
isCached: false,
stage: 'PROJECTION_SIMPLE',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
transformBy: { _id: 0 },
inputStage: {
stage: 'FETCH',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
docsExamined: 1,
alreadyHasObj: 0,
inputStage: {
stage: 'IXSCAN',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
keyPattern: { phoneNumber: 1, firstName: 1, lastName: 1 },
indexName: 'phoneNumber_1_firstName_1_lastName_1',
isMultiKey: false,
multiKeyPaths: { phoneNumber: [], firstName: [], lastName: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: {
phoneNumber: [ '["555-6789", "555-6789"]' ],
firstName: [ '[MinKey, MaxKey]' ],
lastName: [ '[MinKey, MaxKey]' ]
},
keysExamined: 1,
seeks: 1,
dupsTested: 0,
dupsDropped: 0
}
}
}
}
Even if I know that my documents have no other fields, the query planner doesn't know it and must plan to get the document.
Full projection: IXSCAN ➤ PROJECTION_COVERED
When the projection declares all fields, and they are in the index key, there's no need to fetch the document as the projection is covered:
db.friends.find(
{ phoneNumber:"555-6789" }
, { "_id":0 , firstName:1, lastName:1, phoneNumber:1 }
).explain('executionStats').executionStats
{
executionSuccess: true,
nReturned: 1,
executionTimeMillis: 0,
totalKeysExamined: 1,
totalDocsExamined: 0,
executionStages: {
isCached: false,
stage: 'PROJECTION_COVERED',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
transformBy: { _id: 0, firstName: 1, lastName: 1, phoneNumber: 1 },
inputStage: {
stage: 'IXSCAN',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
keyPattern: { phoneNumber: 1, firstName: 1, lastName: 1 },
indexName: 'phoneNumber_1_firstName_1_lastName_1',
isMultiKey: false,
multiKeyPaths: { phoneNumber: [], firstName: [], lastName: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: {
phoneNumber: [ '["555-6789", "555-6789"]' ],
firstName: [ '[MinKey, MaxKey]' ],
lastName: [ '[MinKey, MaxKey]' ]
},
keysExamined: 1,
seeks: 1,
dupsTested: 0,
dupsDropped: 0
}
}
}
Such plan is an index only scan, optimal as it doesn't need to read documents.
Adding an array instead of a scalar value
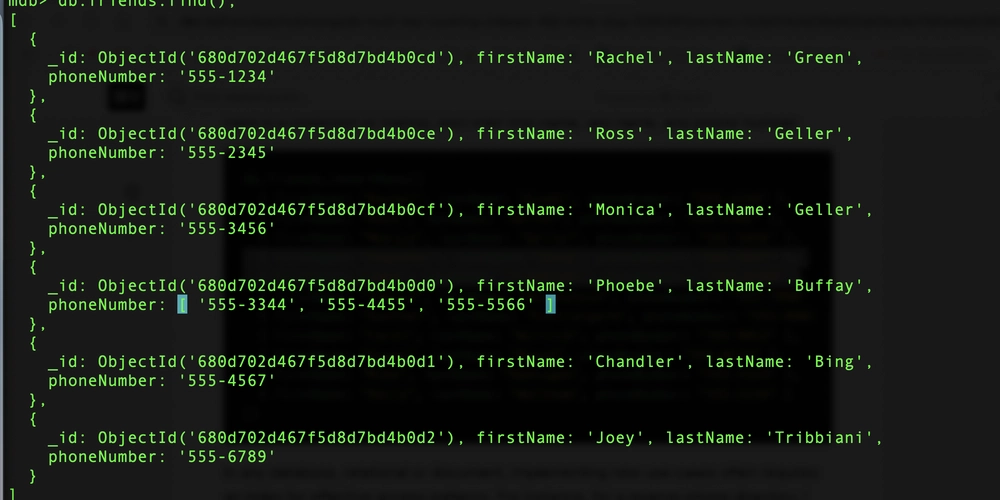
Now that we have examined how a query is covered by a single-key index, where each document has a unique index entry, let's explore the implications of a multi-key index. In MongoDB, a field can contain a single value in one document and an array of values in another. I add such a document, where one of the friends has three phone numbers:
db.friends.insertOne({
firstName: "Phoebe",
lastName: "Buffay",
phoneNumber: ["555-3344", "555-4455", "555-5566"]
})
We refer to the index as a multi-key index, but in reality, it remains the same index in MongoDB. The distinction lies in its capacity to hold multiple entries per document, rather than solely single-key entries.
Query on a single-key entry: IXSCAN ➤ PROJECTION_COVERED
When I query the same single-key document as before, nothing changes and the projection is covered:
db.friends.find(
{ phoneNumber:"555-6789" }
, { "_id":0 , firstName:1, lastName:1, phoneNumber:1 }
).explain('executionStats').executionStats
{
executionSuccess: true,
nReturned: 1,
executionTimeMillis: 0,
totalKeysExamined: 1,
totalDocsExamined: 1,
executionStages: {
isCached: false,
stage: 'PROJECTION_SIMPLE',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
transformBy: { _id: 0, firstName: 1, lastName: 1, phoneNumber: 1 },
inputStage: {
stage: 'FETCH',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
docsExamined: 1,
alreadyHasObj: 0,
inputStage: {
stage: 'IXSCAN',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
keyPattern: { phoneNumber: 1, firstName: 1, lastName: 1 },
indexName: 'phoneNumber_1_firstName_1_lastName_1',
isMultiKey: true,
multiKeyPaths: { phoneNumber: [ 'phoneNumber' ], firstName: [], lastName: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: {
phoneNumber: [ '["555-6789", "555-6789"]' ],
firstName: [ '[MinKey, MaxKey]' ],
lastName: [ '[MinKey, MaxKey]' ]
},
keysExamined: 1,
seeks: 1,
dupsTested: 1,
dupsDropped: 0
}
}
}
}
A key advantage of MongoDB's flexible document model is that changes in structure, as the business evolves, do not impact existing documents. This is more agile than SQL databases where changing a One-to-One relationship to a One-to-Many requires complete refactoring of the model and extensive non-regression testing.
Query on a multi-key entry: IXSCAN ➤ FETCH ➤ PROJECTION_SIMPLE
There's a difference when I query the document with an array of values, visible with isMultiKey: true in the IXSCAN, and a FETCH stage:
db.friends.find(
{ phoneNumber:"555-4455" }
, { "_id":0 , firstName:1, lastName:1, phoneNumber:1 }
).explain('executionStats').executionStats
{
executionSuccess: true,
nReturned: 1,
executionTimeMillis: 0,
totalKeysExamined: 1,
totalDocsExamined: 1,
executionStages: {
isCached: false,
stage: 'PROJECTION_SIMPLE',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
transformBy: { _id: 0, firstName: 1, lastName: 1, phoneNumber: 1 },
inputStage: {
stage: 'FETCH',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
docsExamined: 1,
alreadyHasObj: 0,
inputStage: {
stage: 'IXSCAN',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
keyPattern: { phoneNumber: 1, firstName: 1, lastName: 1 },
indexName: 'phoneNumber_1_firstName_1_lastName_1',
isMultiKey: true,
multiKeyPaths: { phoneNumber: [ 'phoneNumber' ], firstName: [], lastName: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: {
phoneNumber: [ '["555-4455", "555-4455"]' ],
firstName: [ '[MinKey, MaxKey]' ],
lastName: [ '[MinKey, MaxKey]' ]
},
keysExamined: 1,
seeks: 1,
dupsTested: 1,
dupsDropped: 0
}
}
}
}
Understanding the behavior is simplified by recognizing that there is one index entry for each key, with only one entry being read (keysExamined: 1). However, the projection requires access to all associated values. Even if a single value is used to locate the document, the result must display all relevant values:
db.friends.find(
{ phoneNumber:"555-4455" }
, { "_id":0 , firstName:1, lastName:1, phoneNumber:1 }
)
[
{
firstName: 'Phoebe',
lastName: 'Buffay',
phoneNumber: [ '555-3344', '555-4455', '555-5566' ]
}
]
In a multi-key index, the key can be covered, but reading from adjacent keys would not be efficient, so the projection retrieves the document.
Representation of the index entries
To understand and remember how it works, it's useful to represent the logical storage of documents and index entries.
Here are the documents in the collection:
[
{"$recordId": "1", "phoneNumber": "555-1234", "firstName": "Rachel", "lastName": "Green"},
{"$recordId": "2", "phoneNumber": "555-2345", "firstName": "Ross", "lastName": "Geller"},
{"$recordId": "3", "phoneNumber": "555-3456", "firstName": "Monica", "lastName": "Geller"},
{"$recordId": "4", "phoneNumber": "555-4567", "firstName": "Chandler", "lastName": "Bing"},
{"$recordId": "5", "phoneNumber": "555-6789", "firstName": "Joey", "lastName": "Tribbiani"},
{"$recordId": "6", "phoneNumber": "555-7890", "firstName": "Janice", "lastName": "Hosenstein"},
{"$recordId": "7", "phoneNumber": "555-8901", "firstName": "Gunther", "lastName": "Centralperk"},
{"$recordId": "8", "phoneNumber": "555-9012", "firstName": "Carol", "lastName": "Willick"},
{"$recordId": "9", "phoneNumber": "555-0123", "firstName": "Susan", "lastName": "Bunch"},
{"$recordId": "10", "phoneNumber": "555-1123", "firstName": "Mike", "lastName": "Hannigan"},
{"$recordId": "11", "phoneNumber": "555-2234", "firstName": "Emily", "lastName": "Waltham"},
{"$recordId": "12", "phoneNumber": ["555-3344", "555-4455", "555-5566"], "firstName": "Phoebe", "lastName": "Buffay"}
]
Here are the index entries, with each key formed by concatenating the indexed fields in their declaration order. Arrays are unwound, creating separate index entries for each element:
[
{"key": "555-1234 Rachel Green", "$recordId": "1"},
{"key": "555-2345 Ross Geller", "$recordId": "2"},
{"key": "555-3456 Monica Geller", "$recordId": "3"},
{"key": "555-4567 Chandler Bing", "$recordId": "4"},
{"key": "555-6789 Joey Tribbiani", "$recordId": "5"},
{"key": "555-7890 Janice Hosenstein", "$recordId": "6"},
{"key": "555-8901 Gunther Centralperk", "$recordId": "7"},
{"key": "555-9012 Carol Willick", "$recordId": "8"},
{"key": "555-0123 Susan Bunch", "$recordId": "9"},
{"key": "555-1123 Mike Hannigan", "$recordId": "10"},
{"key": "555-2234 Emily Waltham", "$recordId": "11"},
{"key": "555-3344 Phoebe Buffay", "$recordId": "12"},
{"key": "555-4455 Phoebe Buffay", "$recordId": "12"},
{"key": "555-5566 Phoebe Buffay", "$recordId": "12"}
]
Multi-key entries share the same RecordId, the internal document identifier.
Projection of "_id" : IXSCAN ➤ FETCH ➤ PROJECTION_SIMPLE
The "$recordId" is the WiredTiger identifier of the document, and is different from the "_id" (except in a clustered collection where it is assigned from the "_id" instead of a sequence). That explains why the projection of "_id" must fetch the document:
db.friends.find(
{ phoneNumber:"555-6789" }
, { "_id":1 , firstName:1, lastName:1, phoneNumber:1 }
).explain('executionStats').executionStats
{
executionSuccess: true,
nReturned: 1,
executionTimeMillis: 0,
totalKeysExamined: 1,
totalDocsExamined: 1,
executionStages: {
isCached: false,
stage: 'PROJECTION_SIMPLE',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
transformBy: { _id: 1, firstName: 1, lastName: 1, phoneNumber: 1 },
inputStage: {
stage: 'FETCH',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
docsExamined: 1,
alreadyHasObj: 0,
inputStage: {
stage: 'IXSCAN',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
keyPattern: { phoneNumber: 1, firstName: 1, lastName: 1 },
indexName: 'phoneNumber_1_firstName_1_lastName_1',
isMultiKey: false,
multiKeyPaths: { phoneNumber: [], firstName: [], lastName: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: {
phoneNumber: [ '["555-6789", "555-6789"]' ],
firstName: [ '[MinKey, MaxKey]' ],
lastName: [ '[MinKey, MaxKey]' ]
},
keysExamined: 1,
seeks: 1,
dupsTested: 0,
dupsDropped: 0
}
}
}
}
Projection of "$recordId" : IXSCAN ➤ PROJECTION_DEFAULT
If instead of displaying the "_id", I display the "$recordId" with showRecordId(), there is no need to fetch the document as it is present in the index key:
db.friends.find(
{ phoneNumber:"555-6789" }
, { "_id":0 , firstName:1, lastName:1, phoneNumber:1 }
).showRecordId().explain('executionStats').executionStats
{
executionSuccess: true,
nReturned: 1,
executionTimeMillis: 0,
totalKeysExamined: 1,
totalDocsExamined: 0,
executionStages: {
isCached: false,
stage: 'PROJECTION_DEFAULT',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
transformBy: {
_id: 0,
firstName: 1,
lastName: 1,
phoneNumber: 1,
'$recordId': { '$meta': 'recordId' }
},
inputStage: {
stage: 'IXSCAN',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
keyPattern: { phoneNumber: 1, firstName: 1, lastName: 1 },
indexName: 'phoneNumber_1_firstName_1_lastName_1',
isMultiKey: false,
multiKeyPaths: { phoneNumber: [], firstName: [], lastName: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: {
phoneNumber: [ '["555-6789", "555-6789"]' ],
firstName: [ '[MinKey, MaxKey]' ],
lastName: [ '[MinKey, MaxKey]' ]
},
keysExamined: 1,
seeks: 1,
dupsTested: 0,
dupsDropped: 0
}
}
}
Understanding internal index storage and verifying execution plans helps clarify projection coverage behavior.
Comparison with SQL databases
MongoDB's flexible schema enhances indexing capabilities on a per-document basis. You can create an index that works uniformly a field with single-values or arrays. During query time, the query planner identifies multi-key index entries and adjusts its capabilities accordingly.
In a SQL database, a single business object can disrupt the model, necessitating a refactor from a Many-to-One relationship to a Many-to-Many, a complect migration script, and extensive regression tests. This increases complexity, as exceptions become the norm. I exposed an example in ❝The World Is Too Messy for SQL to Work❞.
Utilizing a document datatype like JSONB in PostgreSQL offers greater flexibility, but presents the same challenges when indexing. You must choose between a regular index on single-value fields or an inverted index (GIN) for JSON paths that include arrays, each with distinct limitations in handling range filters, sorting, and projections.
When querying data from hundreds or thousands of documents, utilizing an Index Only Scan, or Covered Projection, is more efficient. This method allows direct retrieval of all values from the index scan, eliminating the need for a FETCH step. The MongoDB query planner will do it when possible and you can verify from the explain statistics.



