










































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)










































































































(1).jpg?#)































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)








































































































![Apple Developing AI 'Vibe-Coding' Assistant for Xcode With Anthropic [Report]](https://www.iclarified.com/images/news/97200/97200/97200-640.jpg)
![Apple's New Ads Spotlight Apple Watch for Kids [Video]](https://www.iclarified.com/images/news/97197/97197/97197-640.jpg)


































































![[Weekly funding roundup April 26-May 2] VC inflow continues to remain downcast](https://images.yourstory.com/cs/2/220356402d6d11e9aa979329348d4c3e/WeeklyFundingRoundupNewLogo1-1739546168054.jpg)
























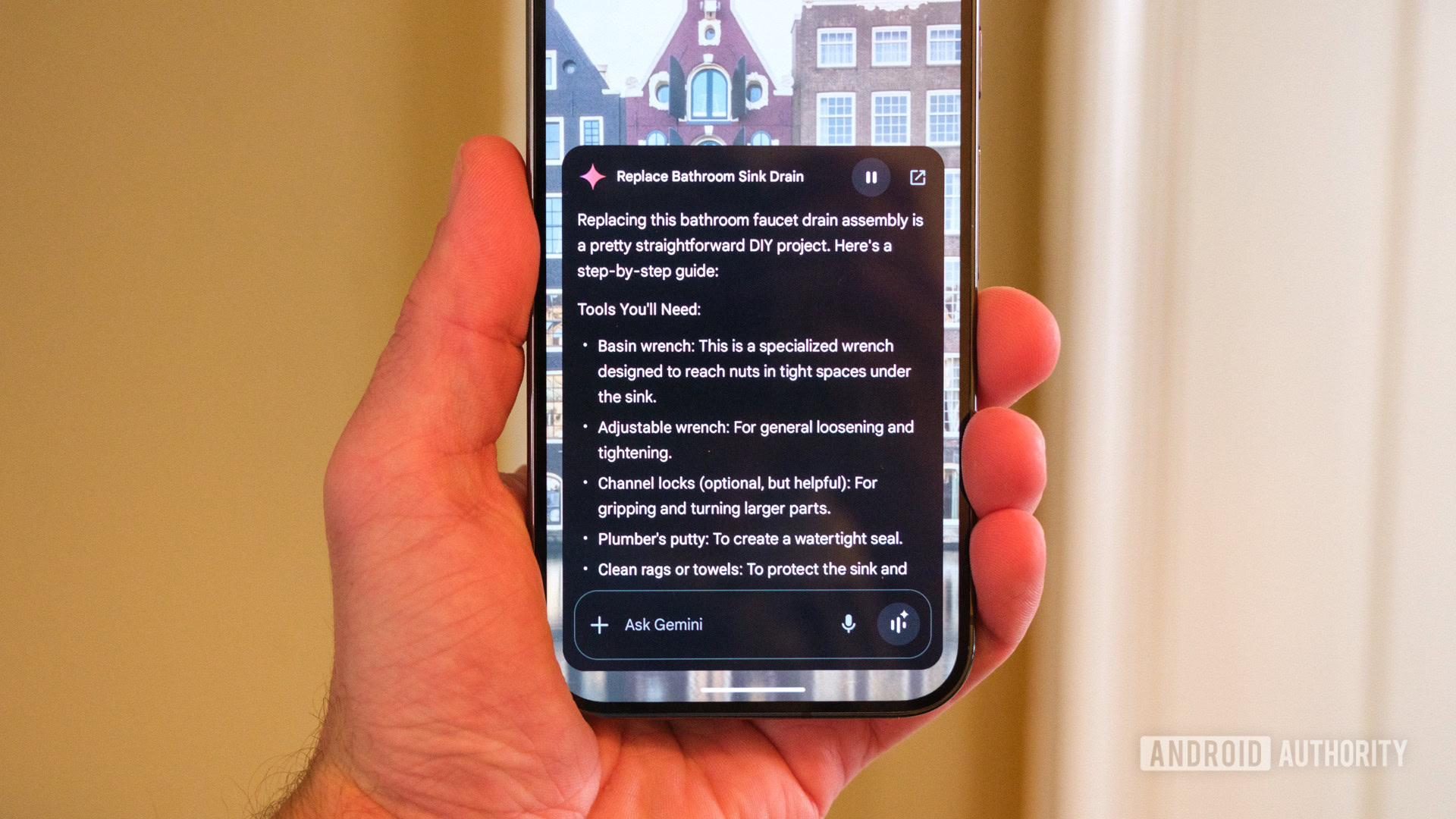
I Built an Open-Source Framework to Make LLM Data Extraction Dead Simple
After getting tired of writing endless boilerplate to extract structured data from documents with LLMs, I built ContextGem - a free, open-source framework that makes this radically easier. What makes it different? ✅ Automated dynamic prompts and data modeling ✅ Precise reference mapping to source content ✅ Built-in justifications for extractions ✅ Nested context extraction ✅ Works with any LLM provider and more built-in abstractions that save developer time. Simple LLM extraction in just a few lines: from contextgem import Aspect, Document, DocumentLLM # Define what to extract doc = Document(raw_text="Your document text here...") doc.aspects = [ Aspect( name="Intellectual property", description="Clauses on intellectual property rights", ) ] # Extract with any LLM llm = DocumentLLM(model="/", api_key="") doc = llm.extract_all(doc) # Get results print(doc.aspects[0].extracted_items) Features a native DOCX converter, support for multiple LLMs, and full serialization - all under Apache 2.0 permissive license. View project on GitHub: https://github.com/shcherbak-ai/contextgem Try it out and let me know your thoughts!

After getting tired of writing endless boilerplate to extract structured data from documents with LLMs, I built ContextGem - a free, open-source framework that makes this radically easier.
What makes it different?
✅ Automated dynamic prompts and data modeling
✅ Precise reference mapping to source content
✅ Built-in justifications for extractions
✅ Nested context extraction
✅ Works with any LLM provider
and more built-in abstractions that save developer time.
Simple LLM extraction in just a few lines:
from contextgem import Aspect, Document, DocumentLLM
# Define what to extract
doc = Document(raw_text="Your document text here...")
doc.aspects = [
Aspect(
name="Intellectual property",
description="Clauses on intellectual property rights",
)
]
# Extract with any LLM
llm = DocumentLLM(model="/ ", api_key="Features a native DOCX converter, support for multiple LLMs, and full serialization - all under Apache 2.0 permissive license.
View project on GitHub: https://github.com/shcherbak-ai/contextgem
Try it out and let me know your thoughts!


